 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEATS: Bootstrapping E-commerce Attribute Taxonomies for Search through Iterative Human-AI Collaboration
Jun 03, 2026E-commerce platforms in emerging markets often operate with underdeveloped product catalogs that contain only category taxonomies but lack structured attribute schemas. This absence of fine-grained product attributes limits search capabilities -- preventing faceted filtering, degrading query understanding, and weakening semantic representations used by search systems. We present BEATS, a human-in-the-loop LLM framework for bootstrapping product attribute taxonomies entirely from scratch. Our approach extends a multi-stage LLM generation pipeline with two critical production stages: (1) proactive quality checking by model developers to filter erroneous outputs, and (2) human annotation by domain-expert local staff to validate generated attributes. The framework operates iteratively -- prompts at each generation stage are refined based on quality check observations and annotator feedback across successive rounds, progressively improving attribute quality. Once the attribute taxonomy is established, we employ LLMs to perform structured attribute tagging on individual product items, enriching their contextual representations. The enriched catalog directly benefits multiple components of the search system: enabling granular attribute-based filtering, providing structured features for ranking models, and improving semantic representations for dense retrieval. We validate the generated taxonomy by training dense retrieval models on attribute-enriched product data, demonstrating consistent improvements over baselines using original catalog information. Our system has been deployed at Rakuten Taiwan, enriching 9 major categories spanning 2,694 sub-categories with 67,277 generated attributes, and over 5.4 million products have been tagged with the generated attributes, with plans to enrich the entire product catalog.
BARCOR: Towards A Unified Framework for Conversational Recommendation Systems
Mar 27, 2022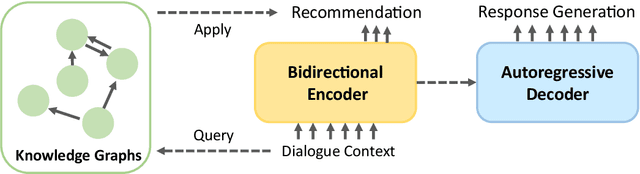

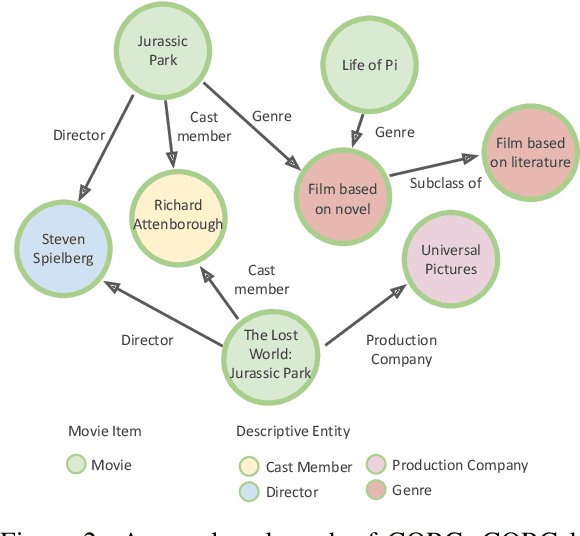

Recommendation systems focus on helping users find items of interest in the situations of information overload, where users' preferences are typically estimated by the past observed behaviors. In contrast, conversational recommendation systems (CRS) aim to understand users' preferences via interactions in conversation flows. CRS is a complex problem that consists of two main tasks: (1) recommendation and (2) response generation. Previous work often tried to solve the problem in a modular manner, where recommenders and response generators are separate neural models. Such modular architectures often come with a complicated and unintuitive connection between the modules, leading to inefficient learning and other issues. In this work, we propose a unified framework based on BART for conversational recommendation, which tackles two tasks in a single model. Furthermore, we also design and collect a lightweight knowledge graph for CRS in the movie domain. The experimental results show that the proposed methods achieve the state-of-the-art performance in terms of both automatic and human evaluation.
TREND: Trigger-Enhanced Relation-Extraction Network for Dialogues
Aug 31, 2021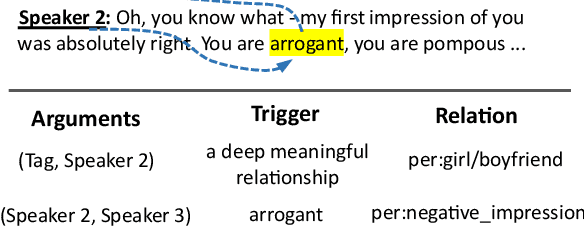

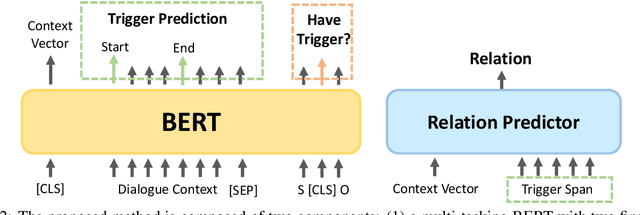

The goal of dialogue relation extraction (DRE) is to identify the relation between two entities in a given dialogue. During conversations, speakers may expose their relations to certain entities by some clues, such evidences called "triggers". However, none of the existing work on DRE tried to detect triggers and leverage the information for enhancing the performance. This paper proposes TREND, a multi-tasking BERT-based model which learns to identify triggers for improving relation extraction. The experimental results show that the proposed method achieves the state-of-the-art on the benchmark datasets.
Dual Inference for Improving Language Understanding and Generation
Oct 15, 2020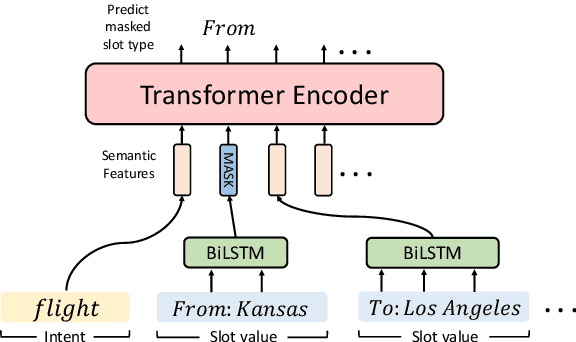

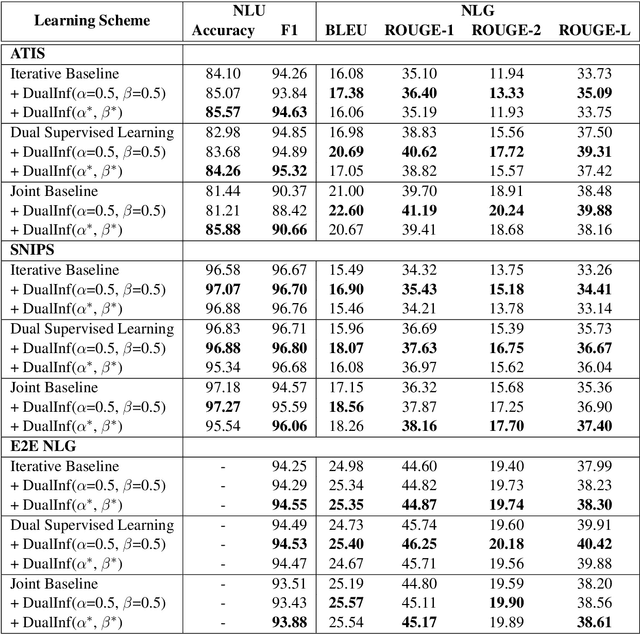
Natural language understanding (NLU) and Natural language generation (NLG) tasks hold a strong dual relationship, where NLU aims at predicting semantic labels based on natural language utterances and NLG does the opposite. The prior work mainly focused on exploiting the duality in model training in order to obtain the models with better performance. However, regarding the fast-growing scale of models in the current NLP area, sometimes we may have difficulty retraining whole NLU and NLG models. To better address the issue, this paper proposes to leverage the duality in the inference stage without the need of retraining. The experiments on three benchmark datasets demonstrate the effectiveness of the proposed method in both NLU and NLG, providing the great potential of practical usage.
Lifelong Language Knowledge Distillation
Oct 05, 2020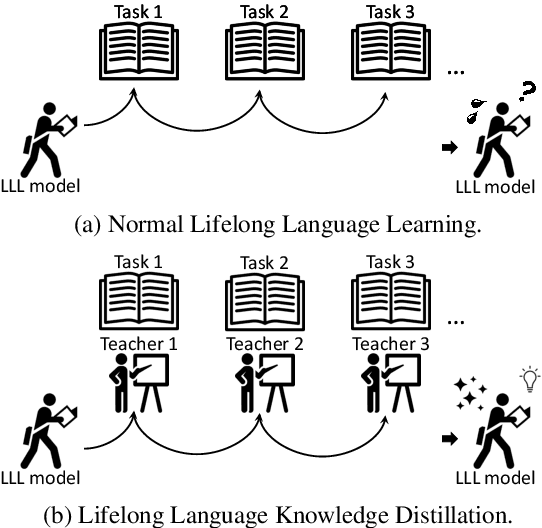
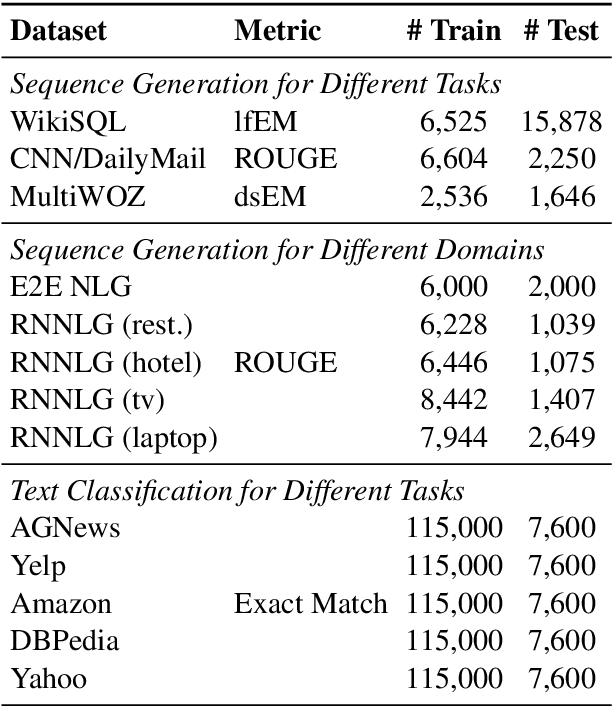
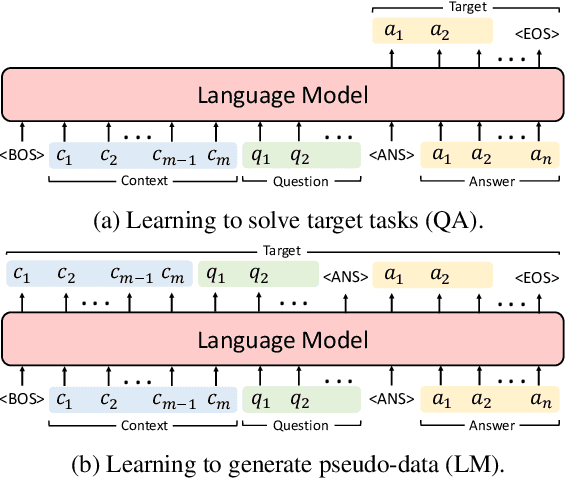
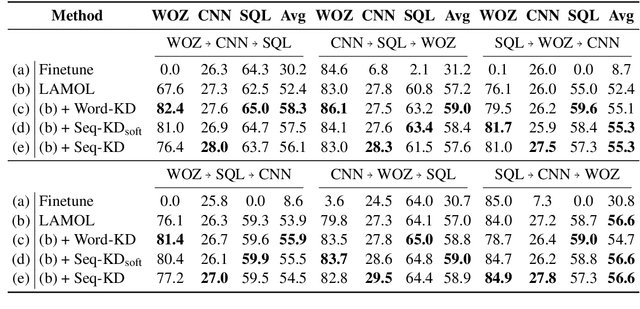
It is challenging to perform lifelong language learning (LLL) on a stream of different tasks without any performance degradation comparing to the multi-task counterparts. To address this issue, we present Lifelong Language Knowledge Distillation (L2KD), a simple but efficient method that can be easily applied to existing LLL architectures in order to mitigate the degradation. Specifically, when the LLL model is trained on a new task, we assign a teacher model to first learn the new task, and pass the knowledge to the LLL model via knowledge distillation. Therefore, the LLL model can better adapt to the new task while keeping the previously learned knowledge. Experiments show that the proposed L2KD consistently improves previous state-of-the-art models, and the degradation comparing to multi-task models in LLL tasks is well mitigated for both sequence generation and text classification tasks.
Towards Unsupervised Language Understanding and Generation by Joint Dual Learning
Apr 30, 2020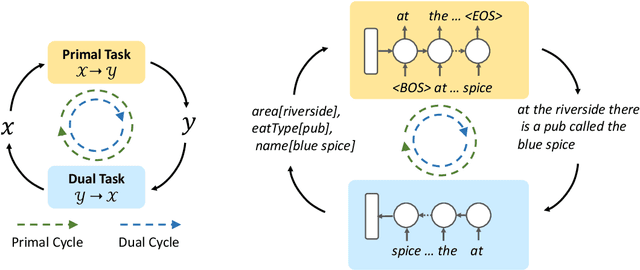
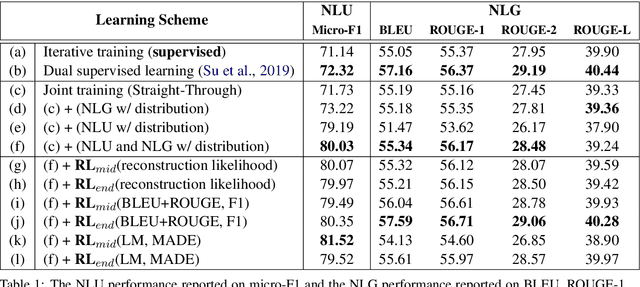
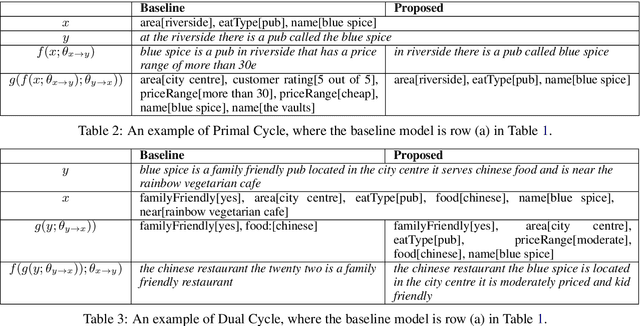
In modular dialogue systems, natural language understanding (NLU) and natural language generation (NLG) are two critical components, where NLU extracts the semantics from the given texts and NLG is to construct corresponding natural language sentences based on the input semantic representations. However, the dual property between understanding and generation has been rarely explored. The prior work is the first attempt that utilized the duality between NLU and NLG to improve the performance via a dual supervised learning framework. However, the prior work still learned both components in a supervised manner, instead, this paper introduces a general learning framework to effectively exploit such duality, providing flexibility of incorporating both supervised and unsupervised learning algorithms to train language understanding and generation models in a joint fashion. The benchmark experiments demonstrate that the proposed approach is capable of boosting the performance of both NLU and NLG.
Towards Understanding of Medical Randomized Controlled Trials by Conclusion Generation
Oct 03, 2019
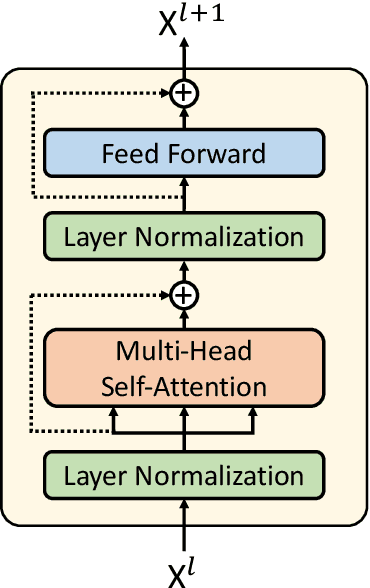
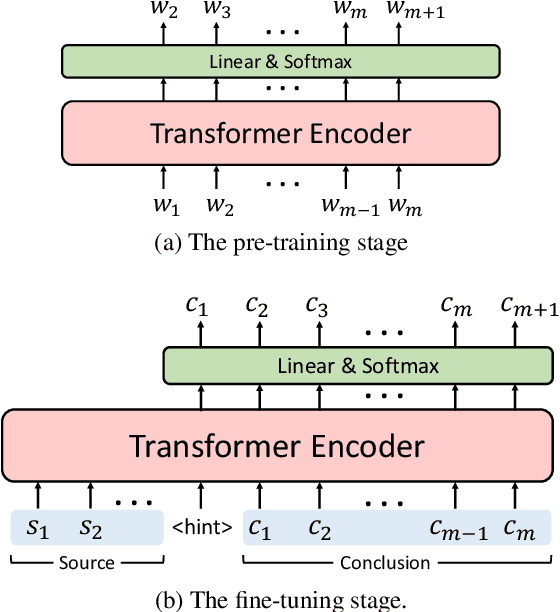

Randomized controlled trials (RCTs) represent the paramount evidence of clinical medicine. Using machines to interpret the massive amount of RCTs has the potential of aiding clinical decision-making. We propose a RCT conclusion generation task from the PubMed 200k RCT sentence classification dataset to examine the effectiveness of sequence-to-sequence models on understanding RCTs. We first build a pointer-generator baseline model for conclusion generation. Then we fine-tune the state-of-the-art GPT-2 language model, which is pre-trained with general domain data, for this new medical domain task. Both automatic and human evaluation show that our GPT-2 fine-tuned models achieve improved quality and correctness in the generated conclusions compared to the baseline pointer-generator model. Further inspection points out the limitations of this current approach and future directions to explore.
Reactive Multi-Stage Feature Fusion for Multimodal Dialogue Modeling
Aug 14, 2019

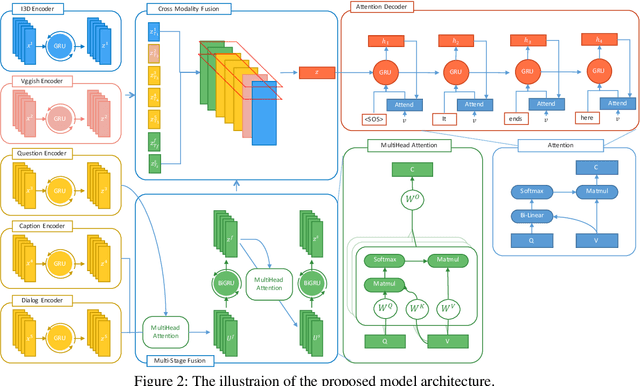

Visual question answering and visual dialogue tasks have been increasingly studied in the multimodal field towards more practical real-world scenarios. A more challenging task, audio visual scene-aware dialogue (AVSD), is proposed to further advance the technologies that connect audio, vision, and language, which introduces temporal video information and dialogue interactions between a questioner and an answerer. This paper proposes an intuitive mechanism that fuses features and attention in multiple stages in order to well integrate multimodal features, and the results demonstrate its capability in the experiments. Also, we apply several state-of-the-art models in other tasks to the AVSD task, and further analyze their generalization across different tasks.
Bridging Dialogue Generation and Facial Expression Synthesis
May 28, 2019
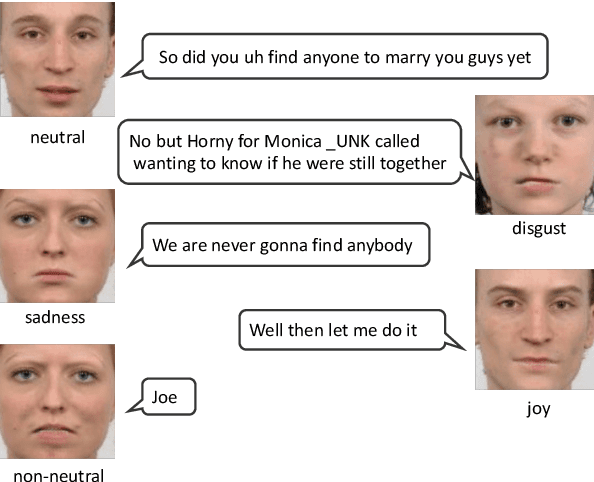
Spoken dialogue systems that assist users to solve complex tasks such as movie ticket booking have become an emerging research topic in artificial intelligence and natural language processing areas. With a well-designed dialogue system as an intelligent personal assistant, people can accomplish certain tasks more easily via natural language interactions. Today there are several virtual intelligent assistants in the market; however, most systems only focus on single modality, such as textual or vocal interaction. A multimodal interface has various advantages: (1) allowing human to communicate with machines in a natural and concise form using the mixture of modalities that most precisely convey the intention to satisfy communication needs, and (2) providing more engaging experience by natural and human-like feedback. This paper explores a brand new research direction, which aims at bridging dialogue generation and facial expression synthesis for better multimodal interaction. The goal is to generate dialogue responses and simultaneously synthesize corresponding visual expressions on faces, which is also an ultimate step toward more human-like virtual assistants.
Dual Supervised Learning for Natural Language Understanding and Generation
May 28, 2019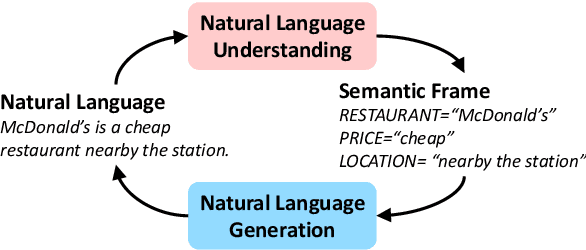
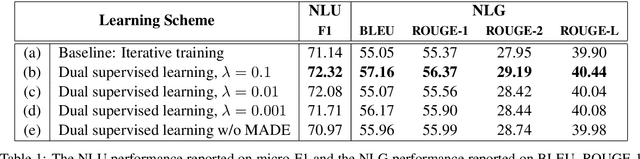
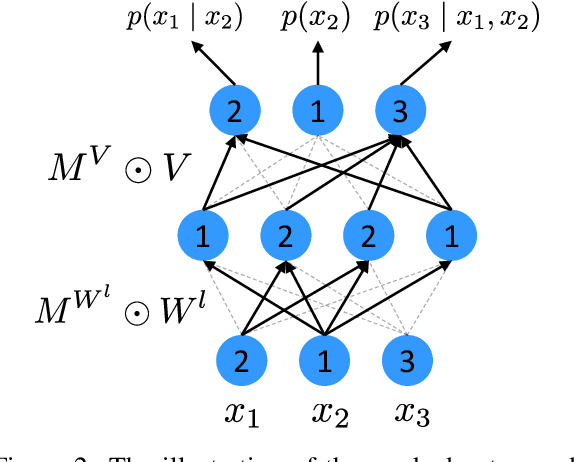
Natural language understanding (NLU) and natural language generation (NLG) are both critical research topics in the NLP field. Natural language understanding is to extract the core semantic meaning from the given utterances, while natural language generation is opposite, of which the goal is to construct corresponding sentences based on the given semantics. However, such dual relationship has not been investigated in the literature. This paper proposes a new learning framework for language understanding and generation on top of dual supervised learning, providing a way to exploit the duality. The preliminary experiments show that the proposed approach boosts the performance for both tasks.