 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Dialogue Generation and Facial Expression Synthesis
Paper and Code
May 28, 2019
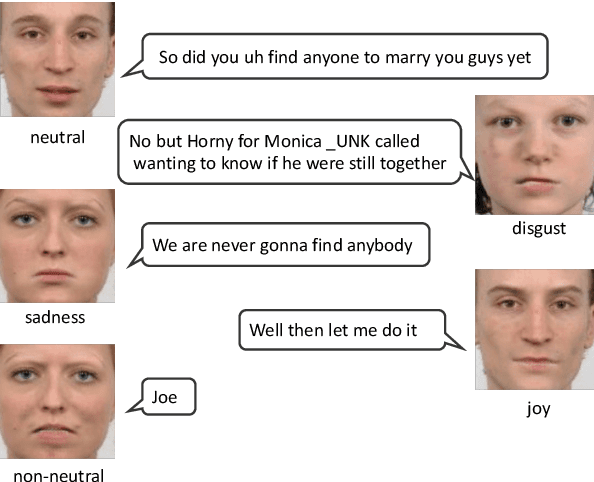
Spoken dialogue systems that assist users to solve complex tasks such as movie ticket booking have become an emerging research topic in artificial intelligence and natural language processing areas. With a well-designed dialogue system as an intelligent personal assistant, people can accomplish certain tasks more easily via natural language interactions. Today there are several virtual intelligent assistants in the market; however, most systems only focus on single modality, such as textual or vocal interaction. A multimodal interface has various advantages: (1) allowing human to communicate with machines in a natural and concise form using the mixture of modalities that most precisely convey the intention to satisfy communication needs, and (2) providing more engaging experience by natural and human-like feedback. This paper explores a brand new research direction, which aims at bridging dialogue generation and facial expression synthesis for better multimodal interaction. The goal is to generate dialogue responses and simultaneously synthesize corresponding visual expressions on faces, which is also an ultimate step toward more human-like virtual assistants.