 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Multi-Stage Feature Fusion for Multimodal Dialogue Modeling
Aug 14, 2019

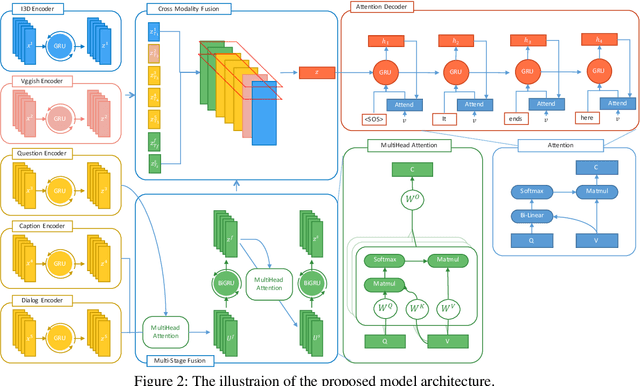

Visual question answering and visual dialogue tasks have been increasingly studied in the multimodal field towards more practical real-world scenarios. A more challenging task, audio visual scene-aware dialogue (AVSD), is proposed to further advance the technologies that connect audio, vision, and language, which introduces temporal video information and dialogue interactions between a questioner and an answerer. This paper proposes an intuitive mechanism that fuses features and attention in multiple stages in order to well integrate multimodal features, and the results demonstrate its capability in the experiments. Also, we apply several state-of-the-art models in other tasks to the AVSD task, and further analyze their generalization across different tasks.
Modeling Melodic Feature Dependency with Modularized Variational Auto-Encoder
Oct 31, 2018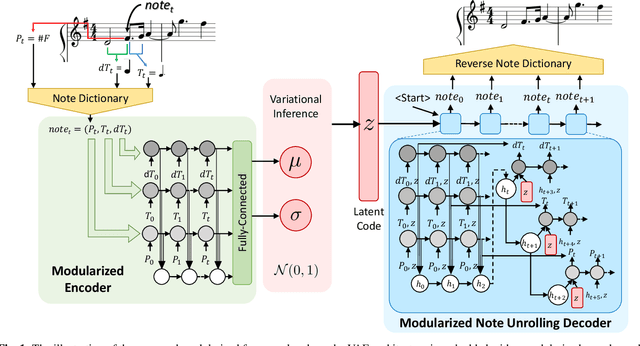
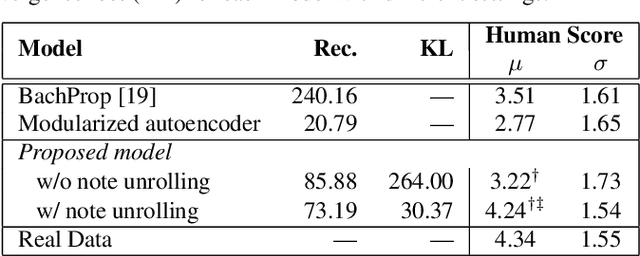
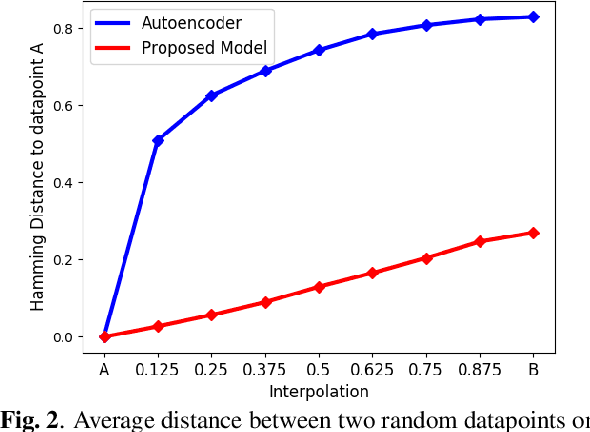
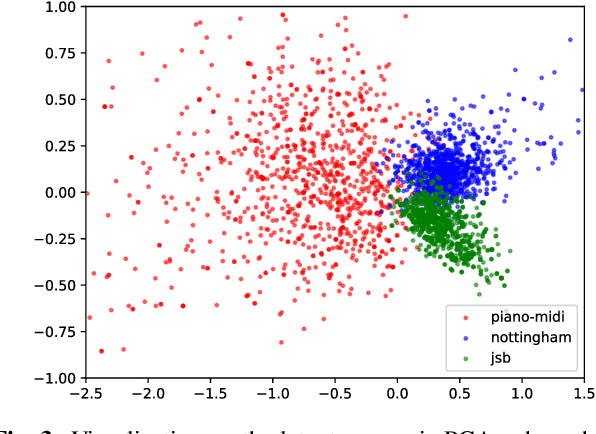
Automatic melody generation has been a long-time aspiration for both AI researchers and musicians. However, learning to generate euphonious melodies has turned out to be highly challenging. This paper introduces 1) a new variant of variational autoencoder (VAE), where the model structure is designed in a modularized manner in order to model polyphonic and dynamic music with domain knowledge, and 2) a hierarchical encoding/decoding strategy, which explicitly models the dependency between melodic features. The proposed framework is capable of generating distinct melodies that sounds natural, and the experiments for evaluating generated music clips show that the proposed model outperforms the baselines in human evaluation.