 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$S^3$: Learnable Sparse Signal Superdensity for Guided Depth Estimation
Mar 22, 2021

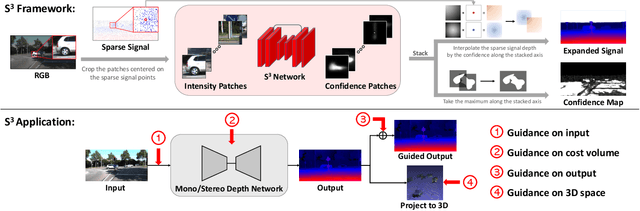
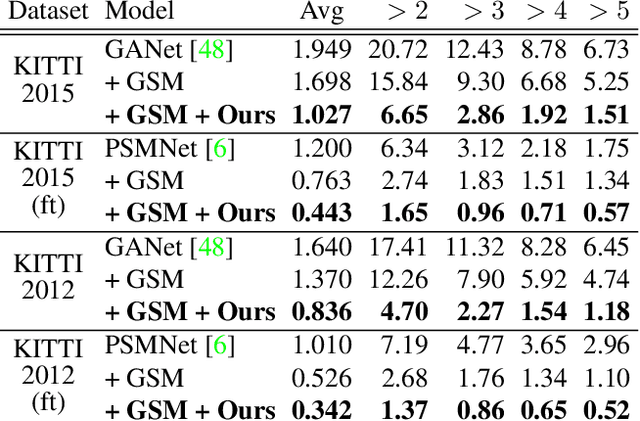
Dense depth estimation plays a key role in multiple applications such as robotics, 3D reconstruction, and augmented reality. While sparse signal, e.g., LiDAR and Radar, has been leveraged as guidance for enhancing dense depth estimation, the improvement is limited due to its low density and imbalanced distribution. To maximize the utility from the sparse source, we propose $S^3$ technique, which expands the depth value from sparse cues while estimating the confidence of expanded region. The proposed $S^3$ can be applied to various guided depth estimation approaches and trained end-to-end at different stages, including input, cost volume and output. Extensive experiments demonstrate the effectiveness, robustness, and flexibility of the $S^3$ technique on LiDAR and Radar signal.
What Do Position Embeddings Learn? An Empirical Study of Pre-Trained Language Model Positional Encoding
Oct 10, 2020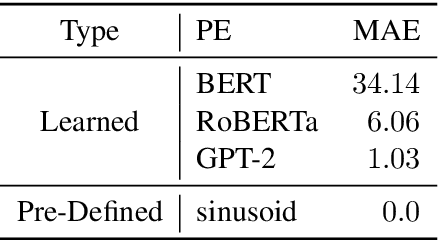
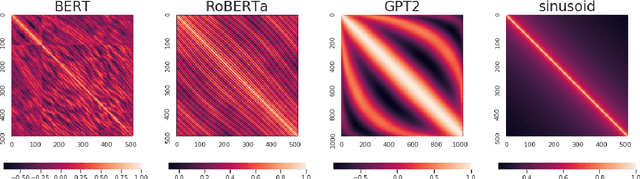
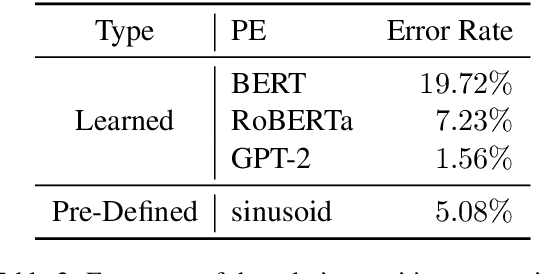
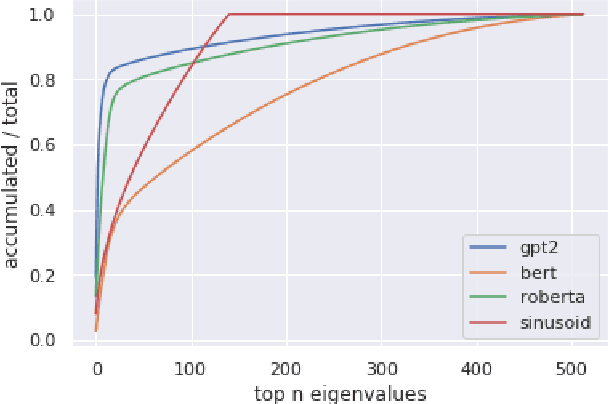
In recent years, pre-trained Transformers have dominated the majority of NLP benchmark tasks. Many variants of pre-trained Transformers have kept breaking out, and most focus on designing different pre-training objectives or variants of self-attention. Embedding the position information in the self-attention mechanism is also an indispensable factor in Transformers however is often discussed at will. Therefore, this paper carries out an empirical study on position embeddings of mainstream pre-trained Transformers, which mainly focuses on two questions: 1) Do position embeddings really learn the meaning of positions? 2) How do these different learned position embeddings affect Transformers for NLP tasks? This paper focuses on providing a new insight of pre-trained position embeddings through feature-level analysis and empirical experiments on most of iconic NLP tasks. It is believed that our experimental results can guide the future work to choose the suitable positional encoding function for specific tasks given the application property.
Modeling Melodic Feature Dependency with Modularized Variational Auto-Encoder
Oct 31, 2018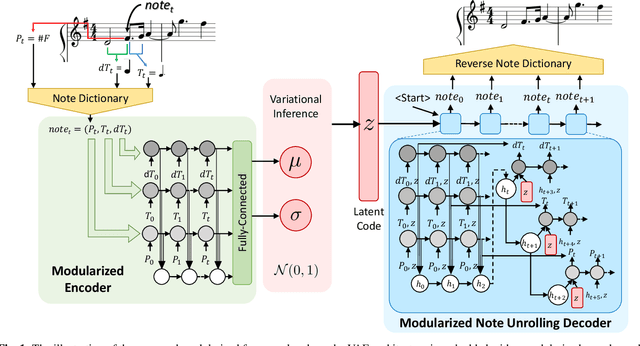
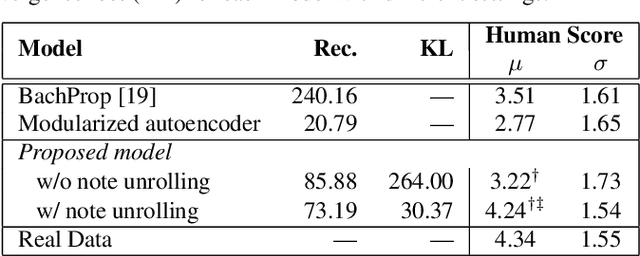
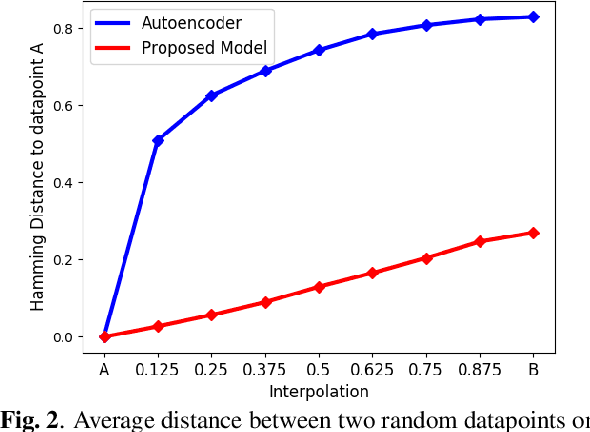
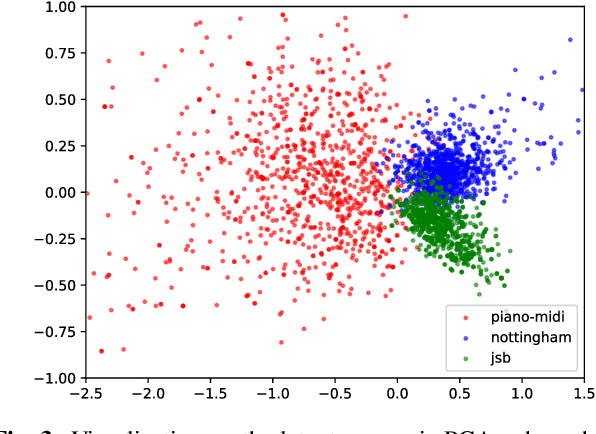
Automatic melody generation has been a long-time aspiration for both AI researchers and musicians. However, learning to generate euphonious melodies has turned out to be highly challenging. This paper introduces 1) a new variant of variational autoencoder (VAE), where the model structure is designed in a modularized manner in order to model polyphonic and dynamic music with domain knowledge, and 2) a hierarchical encoding/decoding strategy, which explicitly models the dependency between melodic features. The proposed framework is capable of generating distinct melodies that sounds natural, and the experiments for evaluating generated music clips show that the proposed model outperforms the baselines in human evaluation.