 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Content Understanding in Conversational Question Answering
Sep 24, 2019



With a lot of work about context-free question answering systems, there is an emerging trend of conversational question answering models in the natural language processing field. Thanks to the recently collected datasets, including QuAC and CoQA, there has been more work on conversational question answering, and some models have achieved competitive performance on both datasets. However, to best of our knowledge, two important questions for conversational comprehension research have not been well studied: 1) How well can the benchmark dataset reflect models' content understanding? 2) Do the models utilize the conversation content well? To investigate the two questions, we design different training settings, testing settings, as well as an attack to verify the models' capability of content understanding on QuAC and CoQA. The results indicate some potential hazards of using QuAC and CoQA for conversational comprehension research. Our analysis also sheds some light one both models and datasets. Given deeper investigation of the task, it is believed that this work is beneficial to the future progress of conversation comprehension.
Knowledge-Grounded Response Generation with Deep Attentional Latent-Variable Model
Mar 23, 2019


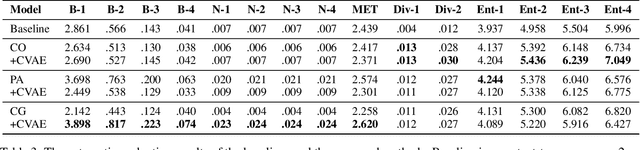
End-to-end dialogue generation has achieved promising results without using handcrafted features and attributes specific for each task and corpus. However, one of the fatal drawbacks in such approaches is that they are unable to generate informative utterances, so it limits their usage from some real-world conversational applications. This paper attempts at generating diverse and informative responses with a variational generation model, which contains a joint attention mechanism conditioning on the information from both dialogue contexts and extra knowledge.