 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Inference for Improving Language Understanding and Generation
Paper and Code
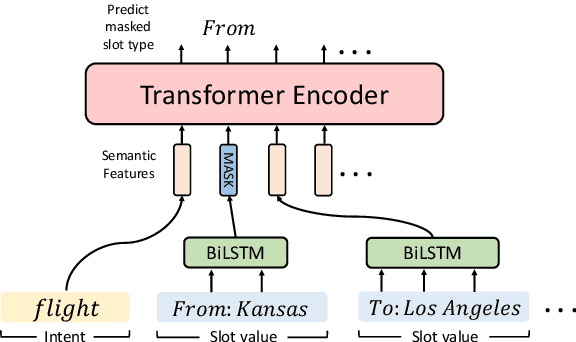

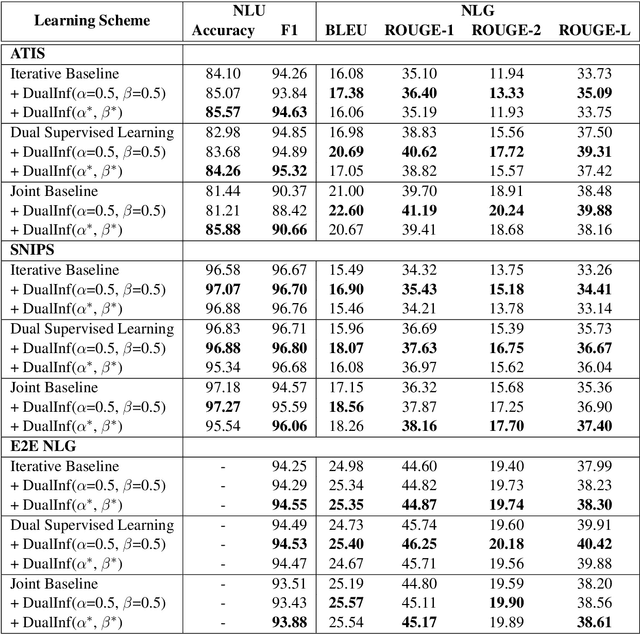
Natural language understanding (NLU) and Natural language generation (NLG) tasks hold a strong dual relationship, where NLU aims at predicting semantic labels based on natural language utterances and NLG does the opposite. The prior work mainly focused on exploiting the duality in model training in order to obtain the models with better performance. However, regarding the fast-growing scale of models in the current NLP area, sometimes we may have difficulty retraining whole NLU and NLG models. To better address the issue, this paper proposes to leverage the duality in the inference stage without the need of retraining. The experiments on three benchmark datasets demonstrate the effectiveness of the proposed method in both NLU and NLG, providing the great potential of practical usage.