 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models as Expert Annotators
Aug 11, 2025Textual data annotation, the process of labeling or tagging text with relevant information, is typically costly, time-consuming, and labor-intensive. While large language models (LLMs) have demonstrated their potential as direct alternatives to human annotators for general domains natural language processing (NLP) tasks, their effectiveness on annotation tasks in domains requiring expert knowledge remains underexplored. In this paper, we investigate: whether top-performing LLMs, which might be perceived as having expert-level proficiency in academic and professional benchmarks, can serve as direct alternatives to human expert annotators? To this end, we evaluate both individual LLMs and multi-agent approaches across three highly specialized domains: finance, biomedicine, and law. Specifically, we propose a multi-agent discussion framework to simulate a group of human annotators, where LLMs are tasked to engage in discussions by considering others' annotations and justifications before finalizing their labels. Additionally, we incorporate reasoning models (e.g., o3-mini) to enable a more comprehensive comparison. Our empirical results reveal that: (1) Individual LLMs equipped with inference-time techniques (e.g., chain-of-thought (CoT), self-consistency) show only marginal or even negative performance gains, contrary to prior literature suggesting their broad effectiveness. (2) Overall, reasoning models do not demonstrate statistically significant improvements over non-reasoning models in most settings. This suggests that extended long CoT provides relatively limited benefits for data annotation in specialized domains. (3) Certain model behaviors emerge in the multi-agent discussion environment. For instance, Claude 3.7 Sonnet with thinking rarely changes its initial annotations, even when other agents provide correct annotations or valid reasoning.
Are Expert-Level Language Models Expert-Level Annotators?
Oct 04, 2024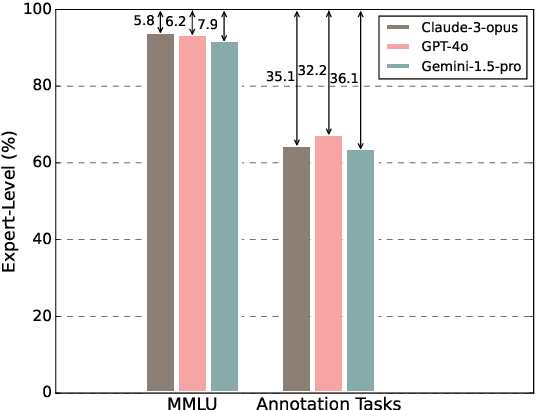
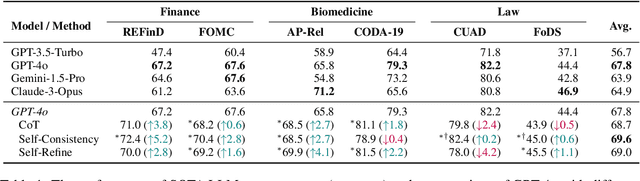
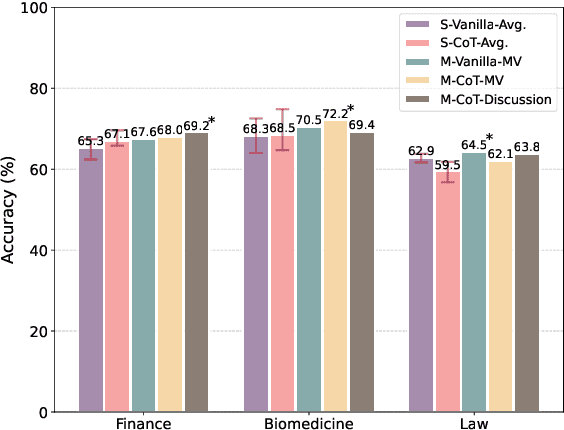
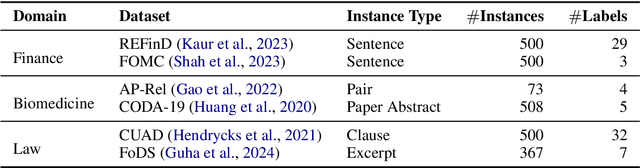
Data annotation refers to the labeling or tagging of textual data with relevant information. A large body of works have reported positive results on leveraging LLMs as an alternative to human annotators. However, existing studies focus on classic NLP tasks, and the extent to which LLMs as data annotators perform in domains requiring expert knowledge remains underexplored. In this work, we investigate comprehensive approaches across three highly specialized domains and discuss practical suggestions from a cost-effectiveness perspective. To the best of our knowledge, we present the first systematic evaluation of LLMs as expert-level data annotators.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024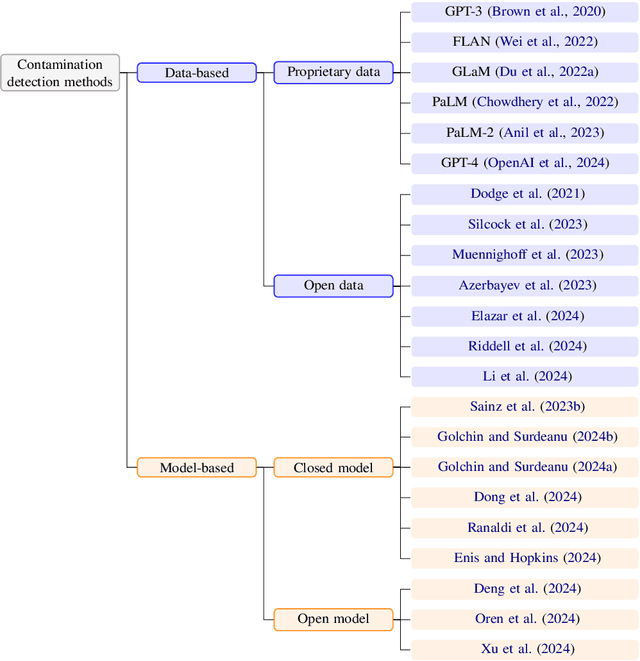
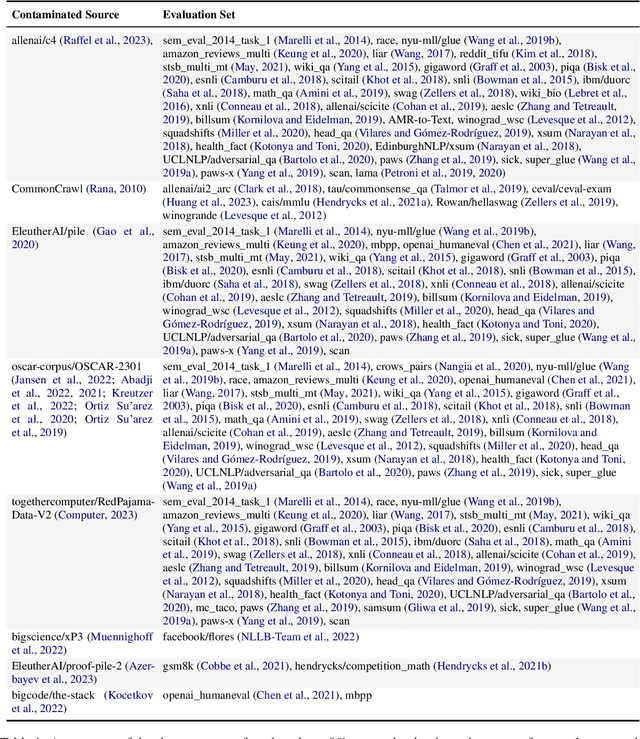
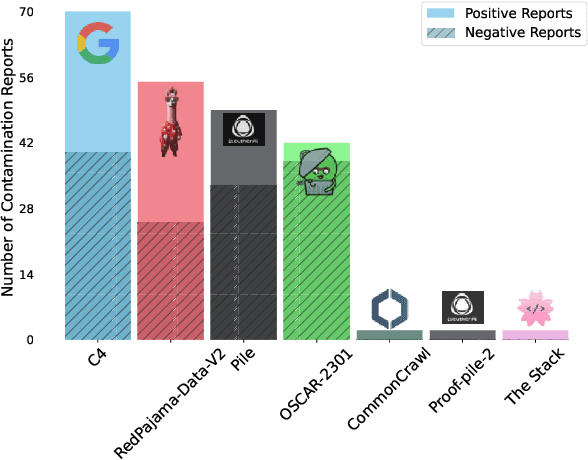
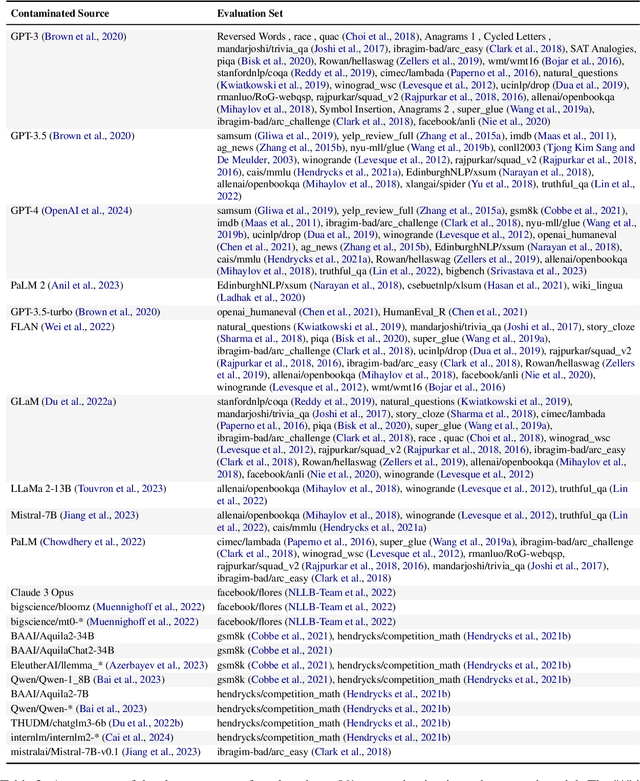
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization
Jun 03, 2024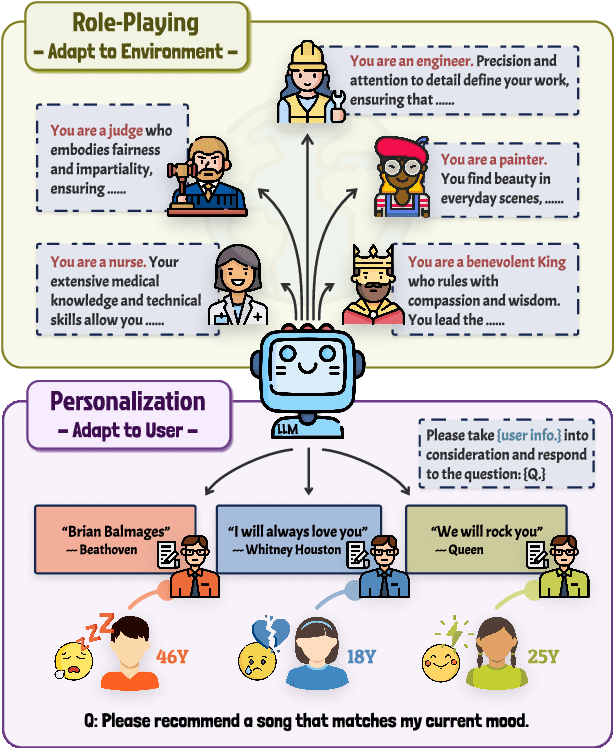

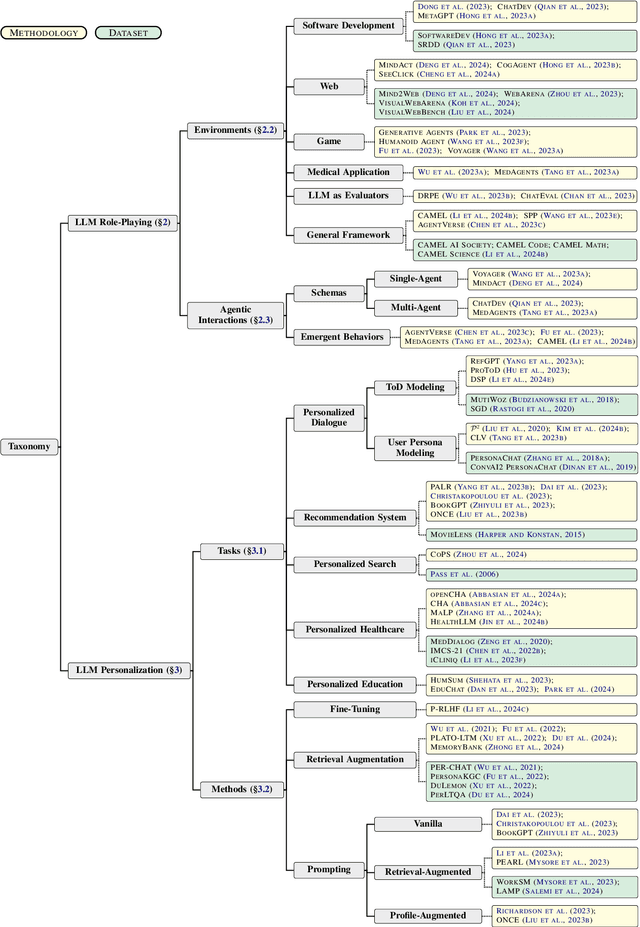
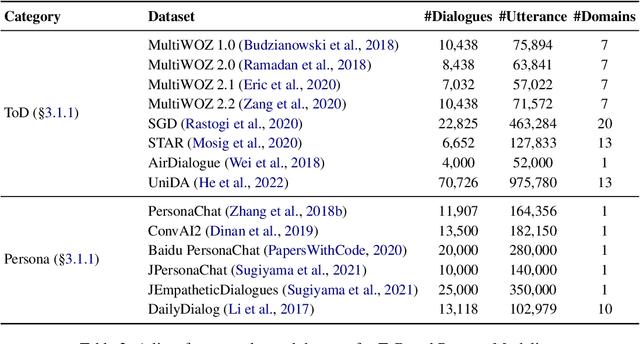
Recently, methods investigating how to adapt large language models (LLMs) for specific scenarios have gained great attention. Particularly, the concept of \textit{persona}, originally adopted in dialogue literature, has re-surged as a promising avenue. However, the growing research on persona is relatively disorganized, lacking a systematic overview. To close the gap, we present a comprehensive survey to categorize the current state of the field. We identify two lines of research, namely (1) LLM Role-Playing, where personas are assigned to LLMs, and (2) LLM Personalization, where LLMs take care of user personas. To the best of our knowledge, we present the first survey tailored for LLM role-playing and LLM personalization under the unified view of persona, including taxonomy, current challenges, and potential directions. To foster future endeavors, we actively maintain a paper collection available to the community: https://github.com/MiuLab/PersonaLLM-Survey