 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Word-Level Spurious Alignment between Images and Pseudo-Captions in Unsupervised Image Captioning
Paper and Code



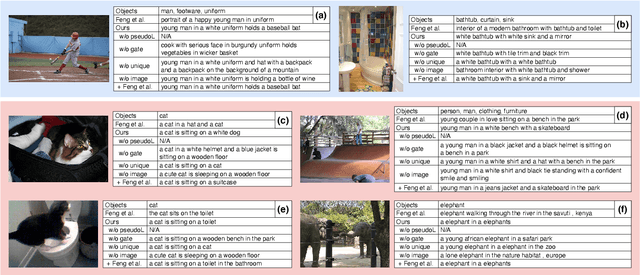
Unsupervised image captioning is a challenging task that aims at generating captions without the supervision of image-sentence pairs, but only with images and sentences drawn from different sources and object labels detected from the images. In previous work, pseudo-captions, i.e., sentences that contain the detected object labels, were assigned to a given image. The focus of the previous work was on the alignment of input images and pseudo-captions at the sentence level. However, pseudo-captions contain many words that are irrelevant to a given image. In this work, we investigate the effect of removing mismatched words from image-sentence alignment to determine how they make this task difficult. We propose a simple gating mechanism that is trained to align image features with only the most reliable words in pseudo-captions: the detected object labels. The experimental results show that our proposed method outperforms the previous methods without introducing complex sentence-level learning objectives. Combined with the sentence-level alignment method of previous work, our method further improves its performance. These results confirm the importance of careful alignment in word-level details.