 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast and Easy Regression Technique for k-NN Classification Without Using Negative Pairs
Paper and Code

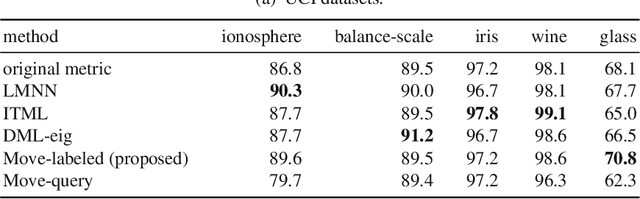

This paper proposes an inexpensive way to learn an effective dissimilarity function to be used for $k$-nearest neighbor ($k$-NN) classification. Unlike Mahalanobis metric learning methods that map both query (unlabeled) objects and labeled objects to new coordinates by a single transformation, our method learns a transformation of labeled objects to new points in the feature space whereas query objects are kept in their original coordinates. This method has several advantages over existing distance metric learning methods: (i) In experiments with large document and image datasets, it achieves $k$-NN classification accuracy better than or at least comparable to the state-of-the-art metric learning methods. (ii) The transformation can be learned efficiently by solving a standard ridge regression problem. For document and image datasets, training is often more than two orders of magnitude faster than the fastest metric learning methods tested. This speed-up is also due to the fact that the proposed method eliminates the optimization over "negative" object pairs, i.e., objects whose class labels are different. (iii) The formulation has a theoretical justification in terms of reducing hubness in data.