 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Champion-level Vision-based Reinforcement Learning Agent for Competitive Racing in Gran Turismo 7
Apr 12, 2025Deep reinforcement learning has achieved superhuman racing performance in high-fidelity simulators like Gran Turismo 7 (GT7). It typically utilizes global features that require instrumentation external to a car, such as precise localization of agents and opponents, limiting real-world applicability. To address this limitation, we introduce a vision-based autonomous racing agent that relies solely on ego-centric camera views and onboard sensor data, eliminating the need for precise localization during inference. This agent employs an asymmetric actor-critic framework: the actor uses a recurrent neural network with the sensor data local to the car to retain track layouts and opponent positions, while the critic accesses the global features during training. Evaluated in GT7, our agent consistently outperforms GT7's built-drivers. To our knowledge, this work presents the first vision-based autonomous racing agent to demonstrate champion-level performance in competitive racing scenarios.
Hyperspherical Normalization for Scalable Deep Reinforcement Learning
Feb 21, 2025Scaling up the model size and computation has brought consistent performance improvements in supervised learning. However, this lesson often fails to apply to reinforcement learning (RL) because training the model on non-stationary data easily leads to overfitting and unstable optimization. In response, we introduce SimbaV2, a novel RL architecture designed to stabilize optimization by (i) constraining the growth of weight and feature norm by hyperspherical normalization; and (ii) using a distributional value estimation with reward scaling to maintain stable gradients under varying reward magnitudes. Using the soft actor-critic as a base algorithm, SimbaV2 scales up effectively with larger models and greater compute, achieving state-of-the-art performance on 57 continuous control tasks across 4 domains. The code is available at https://dojeon-ai.github.io/SimbaV2.
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
Oct 13, 2024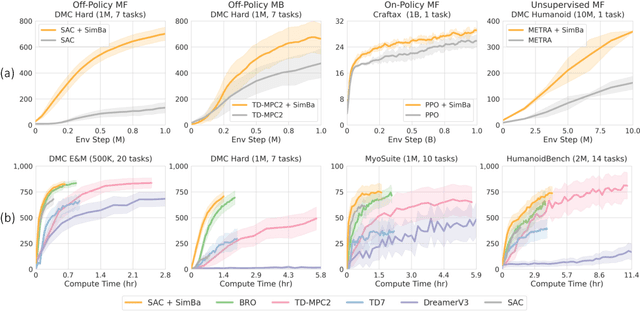

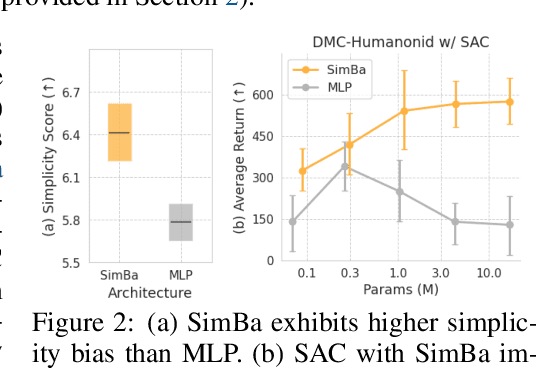
Recent advances in CV and NLP have been largely driven by scaling up the number of network parameters, despite traditional theories suggesting that larger networks are prone to overfitting. These large networks avoid overfitting by integrating components that induce a simplicity bias, guiding models toward simple and generalizable solutions. However, in deep RL, designing and scaling up networks have been less explored. Motivated by this opportunity, we present SimBa, an architecture designed to scale up parameters in deep RL by injecting a simplicity bias. SimBa consists of three components: (i) an observation normalization layer that standardizes inputs with running statistics, (ii) a residual feedforward block to provide a linear pathway from the input to output, and (iii) a layer normalization to control feature magnitudes. By scaling up parameters with SimBa, the sample efficiency of various deep RL algorithms-including off-policy, on-policy, and unsupervised methods-is consistently improved. Moreover, solely by integrating SimBa architecture into SAC, it matches or surpasses state-of-the-art deep RL methods with high computational efficiency across DMC, MyoSuite, and HumanoidBench. These results demonstrate SimBa's broad applicability and effectiveness across diverse RL algorithms and environments.
A Super-human Vision-based Reinforcement Learning Agent for Autonomous Racing in Gran Turismo
Jun 18, 2024



Racing autonomous cars faster than the best human drivers has been a longstanding grand challenge for the fields of Artificial Intelligence and robotics. Recently, an end-to-end deep reinforcement learning agent met this challenge in a high-fidelity racing simulator, Gran Turismo. However, this agent relied on global features that require instrumentation external to the car. This paper introduces, to the best of our knowledge, the first super-human car racing agent whose sensor input is purely local to the car, namely pixels from an ego-centric camera view and quantities that can be sensed from on-board the car, such as the car's velocity. By leveraging global features only at training time, the learned agent is able to outperform the best human drivers in time trial (one car on the track at a time) races using only local input features. The resulting agent is evaluated in Gran Turismo 7 on multiple tracks and cars. Detailed ablation experiments demonstrate the agent's strong reliance on visual inputs, making it the first vision-based super-human car racing agent.
Value Function Decomposition for Iterative Design of Reinforcement Learning Agents
Jun 24, 2022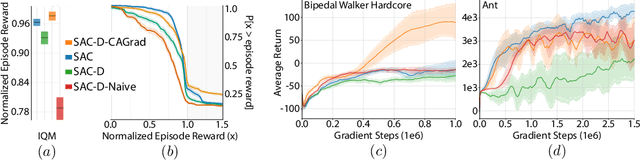

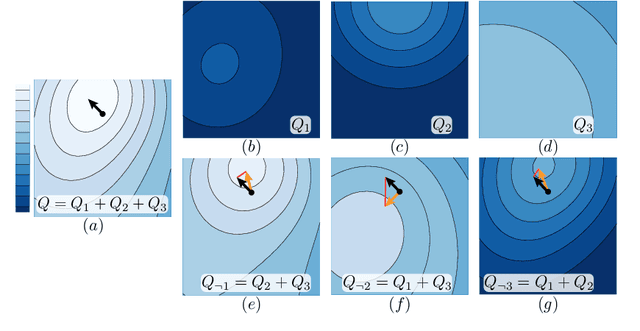

Designing reinforcement learning (RL) agents is typically a difficult process that requires numerous design iterations. Learning can fail for a multitude of reasons, and standard RL methods provide too few tools to provide insight into the exact cause. In this paper, we show how to integrate value decomposition into a broad class of actor-critic algorithms and use it to assist in the iterative agent-design process. Value decomposition separates a reward function into distinct components and learns value estimates for each. These value estimates provide insight into an agent's learning and decision-making process and enable new training methods to mitigate common problems. As a demonstration, we introduce SAC-D, a variant of soft actor-critic (SAC) adapted for value decomposition. SAC-D maintains similar performance to SAC, while learning a larger set of value predictions. We also introduce decomposition-based tools that exploit this information, including a new reward influence metric, which measures each reward component's effect on agent decision-making. Using these tools, we provide several demonstrations of decomposition's use in identifying and addressing problems in the design of both environments and agents. Value decomposition is broadly applicable and easy to incorporate into existing algorithms and workflows, making it a powerful tool in an RL practitioner's toolbox.
Expert Human-Level Driving in Gran Turismo Sport Using Deep Reinforcement Learning with Image-based Representation
Nov 11, 2021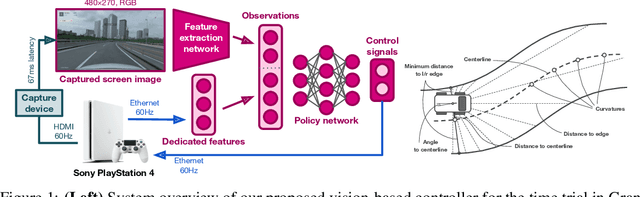

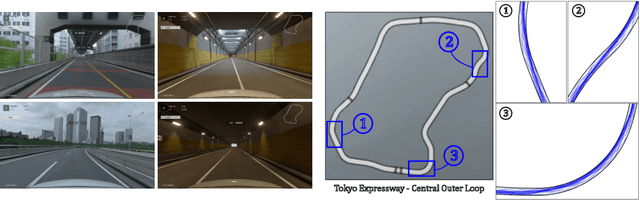
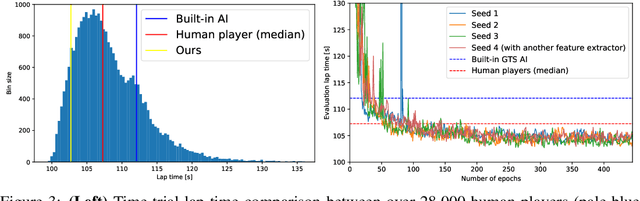
When humans play virtual racing games, they use visual environmental information on the game screen to understand the rules within the environments. In contrast, a state-of-the-art realistic racing game AI agent that outperforms human players does not use image-based environmental information but the compact and precise measurements provided by the environment. In this paper, a vision-based control algorithm is proposed and compared with human player performances under the same conditions in realistic racing scenarios using Gran Turismo Sport (GTS), which is known as a high-fidelity realistic racing simulator. In the proposed method, the environmental information that constitutes part of the observations in conventional state-of-the-art methods is replaced with feature representations extracted from game screen images. We demonstrate that the proposed method performs expert human-level vehicle control under high-speed driving scenarios even with game screen images as high-dimensional inputs. Additionally, it outperforms the built-in AI in GTS in a time trial task, and its score places it among the top 10% approximately 28,000 human players.
d3rlpy: An Offline Deep Reinforcement Learning Library
Nov 06, 2021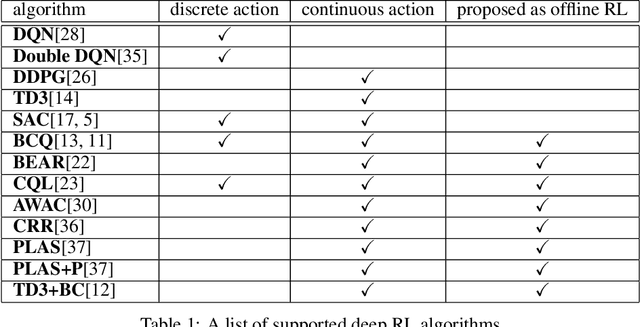
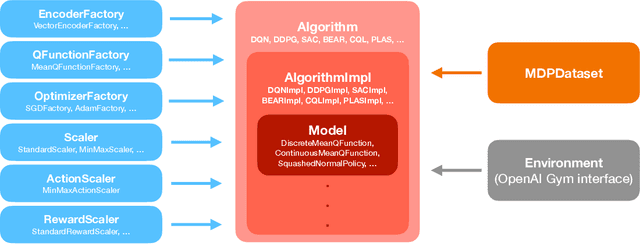
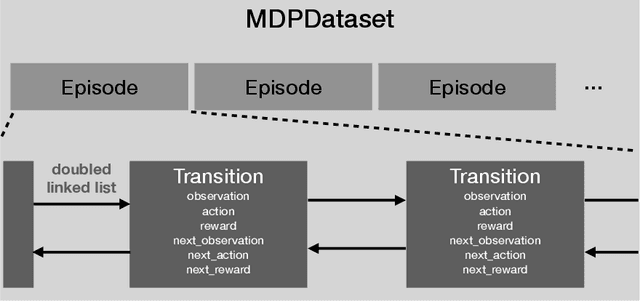
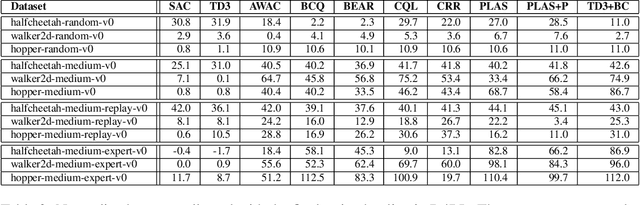
In this paper, we introduce d3rlpy, an open-sourced offline deep reinforcement learning (RL) library for Python. d3rlpy supports a number of offline deep RL algorithms as well as online algorithms via a user-friendly API. To assist deep RL research and development projects, d3rlpy provides practical and unique features such as data collection, exporting policies for deployment, preprocessing and postprocessing, distributional Q-functions, multi-step learning and a convenient command-line interface. Furthermore, d3rlpy additionally provides a novel graphical interface that enables users to train offline RL algorithms without coding programs. Lastly, the implemented algorithms are benchmarked with D4RL datasets to ensure the implementation quality. The d3rlpy source code can be found on GitHub: \url{https://github.com/takuseno/d3rlpy}.