 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trajectory Alignment Coefficient in Two Acts: From Reward Tuning to Reward Learning
Jan 23, 2026The success of reinforcement learning (RL) is fundamentally tied to having a reward function that accurately reflects the task objective. Yet, designing reward functions is notoriously time-consuming and prone to misspecification. To address this issue, our first goal is to understand how to support RL practitioners in specifying appropriate weights for a reward function. We leverage the Trajectory Alignment Coefficient (TAC), a metric that evaluates how closely a reward function's induced preferences match those of a domain expert. To evaluate whether TAC provides effective support in practice, we conducted a human-subject study in which RL practitioners tuned reward weights for Lunar Lander. We found that providing TAC during reward tuning led participants to produce more performant reward functions and report lower cognitive workload relative to standard tuning without TAC. However, the study also underscored that manual reward design, even with TAC, remains labor-intensive. This limitation motivated our second goal: to learn a reward model that maximizes TAC directly. Specifically, we propose Soft-TAC, a differentiable approximation of TAC that can be used as a loss function to train reward models from human preference data. Validated in the racing simulator Gran Turismo 7, reward models trained using Soft-TAC successfully captured preference-specific objectives, resulting in policies with qualitatively more distinct behaviors than models trained with standard Cross-Entropy loss. This work demonstrates that TAC can serve as both a practical tool for guiding reward tuning and a reward learning objective in complex domains.
A Champion-level Vision-based Reinforcement Learning Agent for Competitive Racing in Gran Turismo 7
Apr 12, 2025Deep reinforcement learning has achieved superhuman racing performance in high-fidelity simulators like Gran Turismo 7 (GT7). It typically utilizes global features that require instrumentation external to a car, such as precise localization of agents and opponents, limiting real-world applicability. To address this limitation, we introduce a vision-based autonomous racing agent that relies solely on ego-centric camera views and onboard sensor data, eliminating the need for precise localization during inference. This agent employs an asymmetric actor-critic framework: the actor uses a recurrent neural network with the sensor data local to the car to retain track layouts and opponent positions, while the critic accesses the global features during training. Evaluated in GT7, our agent consistently outperforms GT7's built-drivers. To our knowledge, this work presents the first vision-based autonomous racing agent to demonstrate champion-level performance in competitive racing scenarios.
Residual-MPPI: Online Policy Customization for Continuous Control
Jul 02, 2024Policies learned through Reinforcement Learning (RL) and Imitation Learning (IL) have demonstrated significant potential in achieving advanced performance in continuous control tasks. However, in real-world environments, it is often necessary to further customize a trained policy when there are additional requirements that were unforeseen during the original training phase. It is possible to fine-tune the policy to meet the new requirements, but this often requires collecting new data with the added requirements and access to the original training metric and policy parameters. In contrast, an online planning algorithm, if capable of meeting the additional requirements, can eliminate the necessity for extensive training phases and customize the policy without knowledge of the original training scheme or task. In this work, we propose a generic online planning algorithm for customizing continuous-control policies at the execution time which we call Residual-MPPI. It is able to customize a given prior policy on new performance metrics in few-shot and even zero-shot online settings. Also, Residual-MPPI only requires access to the action distribution produced by the prior policy, without additional knowledge regarding the original task. Through our experiments, we demonstrate that the proposed Residual-MPPI algorithm can accomplish the few-shot/zero-shot online policy customization task effectively, including customizing the champion-level racing agent, Gran Turismo Sophy (GT Sophy) 1.0, in the challenging car racing scenario, Gran Turismo Sport (GTS) environment. Demo videos are available on our website: https://sites.google.com/view/residual-mppi
A Super-human Vision-based Reinforcement Learning Agent for Autonomous Racing in Gran Turismo
Jun 18, 2024



Racing autonomous cars faster than the best human drivers has been a longstanding grand challenge for the fields of Artificial Intelligence and robotics. Recently, an end-to-end deep reinforcement learning agent met this challenge in a high-fidelity racing simulator, Gran Turismo. However, this agent relied on global features that require instrumentation external to the car. This paper introduces, to the best of our knowledge, the first super-human car racing agent whose sensor input is purely local to the car, namely pixels from an ego-centric camera view and quantities that can be sensed from on-board the car, such as the car's velocity. By leveraging global features only at training time, the learned agent is able to outperform the best human drivers in time trial (one car on the track at a time) races using only local input features. The resulting agent is evaluated in Gran Turismo 7 on multiple tracks and cars. Detailed ablation experiments demonstrate the agent's strong reliance on visual inputs, making it the first vision-based super-human car racing agent.
BeTAIL: Behavior Transformer Adversarial Imitation Learning from Human Racing Gameplay
Feb 22, 2024Imitation learning learns a policy from demonstrations without requiring hand-designed reward functions. In many robotic tasks, such as autonomous racing, imitated policies must model complex environment dynamics and human decision-making. Sequence modeling is highly effective in capturing intricate patterns of motion sequences but struggles to adapt to new environments or distribution shifts that are common in real-world robotics tasks. In contrast, Adversarial Imitation Learning (AIL) can mitigate this effect, but struggles with sample inefficiency and handling complex motion patterns. Thus, we propose BeTAIL: Behavior Transformer Adversarial Imitation Learning, which combines a Behavior Transformer (BeT) policy from human demonstrations with online AIL. BeTAIL adds an AIL residual policy to the BeT policy to model the sequential decision-making process of human experts and correct for out-of-distribution states or shifts in environment dynamics. We test BeTAIL on three challenges with expert-level demonstrations of real human gameplay in Gran Turismo Sport. Our proposed residual BeTAIL reduces environment interactions and improves racing performance and stability, even when the BeT is pretrained on different tracks than downstream learning. Videos and code available at: https://sites.google.com/berkeley.edu/BeTAIL/home.
Improving Wind Resistance Performance of Cascaded PID Controlled Quadcopters using Residual Reinforcement Learning
Aug 03, 2023



Wind resistance control is an essential feature for quadcopters to maintain their position to avoid deviation from target position and prevent collisions with obstacles. Conventionally, cascaded PID controller is used for the control of quadcopters for its simplicity and ease of tuning its parameters. However, it is weak against wind disturbances and the quadcopter can easily deviate from target position. In this work, we propose a residual reinforcement learning based approach to build a wind resistance controller of a quadcopter. By learning only the residual that compensates the disturbance, we can continue using the cascaded PID controller as the base controller of the quadcopter but improve its performance against wind disturbances. To avoid unexpected crashes and destructions of quadcopters, our method does not require real hardware for data collection and training. The controller is trained only on a simulator and directly applied to the target hardware without extra finetuning process. We demonstrate the effectiveness of our approach through various experiments including an experiment in an outdoor scene with wind speed greater than 13 m/s. Despite its simplicity, our controller reduces the position deviation by approximately 50% compared to the quadcopter controlled with the conventional cascaded PID controller. Furthermore, trained controller is robust and preserves its performance even though the quadcopter's mass and propeller's lift coefficient is changed between 50% to 150% from original training time.
Skill-Critic: Refining Learned Skills for Reinforcement Learning
Jun 16, 2023Hierarchical reinforcement learning (RL) can accelerate long-horizon decision-making by temporally abstracting a policy into multiple levels. Promising results in sparse reward environments have been seen with skills, i.e. sequences of primitive actions. Typically, a skill latent space and policy are discovered from offline data, but the resulting low-level policy can be unreliable due to low-coverage demonstrations or distribution shifts. As a solution, we propose fine-tuning the low-level policy in conjunction with high-level skill selection. Our Skill-Critic algorithm optimizes both the low and high-level policies; these policies are also initialized and regularized by the latent space learned from offline demonstrations to guide the joint policy optimization. We validate our approach in multiple sparse RL environments, including a new sparse reward autonomous racing task in Gran Turismo Sport. The experiments show that Skill-Critic's low-level policy fine-tuning and demonstration-guided regularization are essential for optimal performance. Images and videos are available at https://sites.google.com/view/skill-critic. We plan to open source the code with the final version.
Expert Human-Level Driving in Gran Turismo Sport Using Deep Reinforcement Learning with Image-based Representation
Nov 11, 2021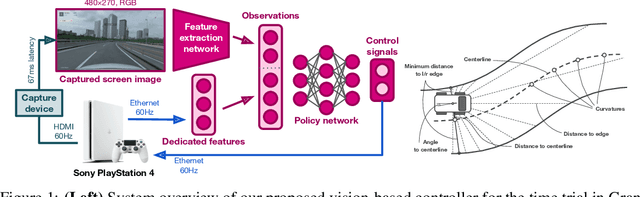

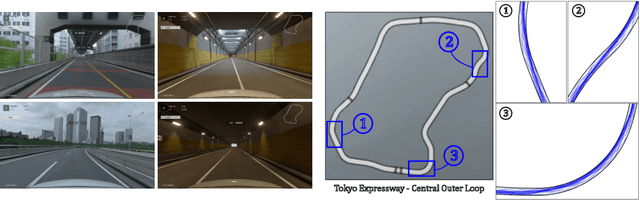
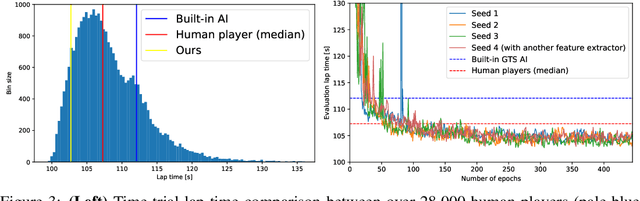
When humans play virtual racing games, they use visual environmental information on the game screen to understand the rules within the environments. In contrast, a state-of-the-art realistic racing game AI agent that outperforms human players does not use image-based environmental information but the compact and precise measurements provided by the environment. In this paper, a vision-based control algorithm is proposed and compared with human player performances under the same conditions in realistic racing scenarios using Gran Turismo Sport (GTS), which is known as a high-fidelity realistic racing simulator. In the proposed method, the environmental information that constitutes part of the observations in conventional state-of-the-art methods is replaced with feature representations extracted from game screen images. We demonstrate that the proposed method performs expert human-level vehicle control under high-speed driving scenarios even with game screen images as high-dimensional inputs. Additionally, it outperforms the built-in AI in GTS in a time trial task, and its score places it among the top 10% approximately 28,000 human players.