 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatteGAN: Visually Guided Language Attention for Multi-Turn Text-Conditioned Image Manipulation
Dec 28, 2021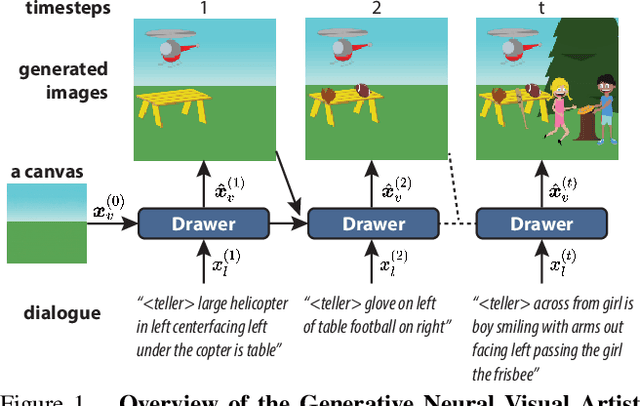
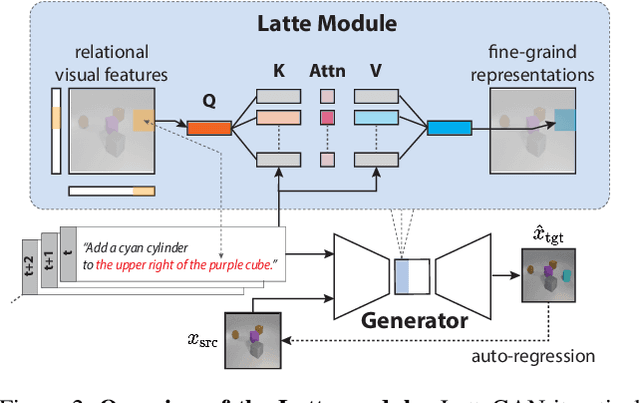
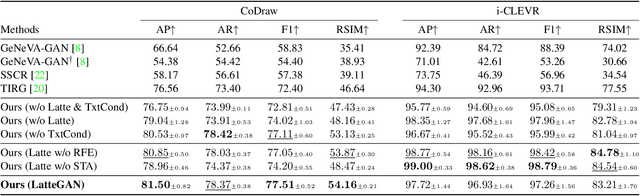
Text-guided image manipulation tasks have recently gained attention in the vision-and-language community. While most of the prior studies focused on single-turn manipulation, our goal in this paper is to address the more challenging multi-turn image manipulation (MTIM) task. Previous models for this task successfully generate images iteratively, given a sequence of instructions and a previously generated image. However, this approach suffers from under-generation and a lack of generated quality of the objects that are described in the instructions, which consequently degrades the overall performance. To overcome these problems, we present a novel architecture called a Visually Guided Language Attention GAN (LatteGAN). Here, we address the limitations of the previous approaches by introducing a Visually Guided Language Attention (Latte) module, which extracts fine-grained text representations for the generator, and a Text-Conditioned U-Net discriminator architecture, which discriminates both the global and local representations of fake or real images. Extensive experiments on two distinct MTIM datasets, CoDraw and i-CLEVR, demonstrate the state-of-the-art performance of the proposed model.
d3rlpy: An Offline Deep Reinforcement Learning Library
Nov 06, 2021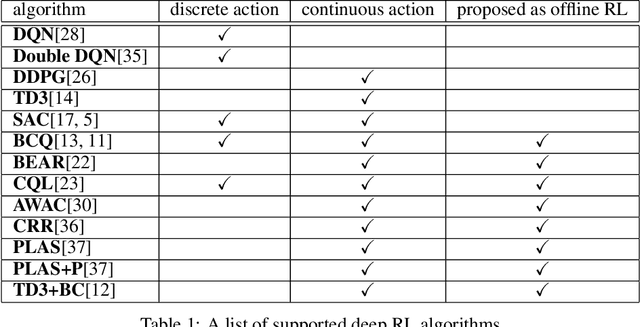
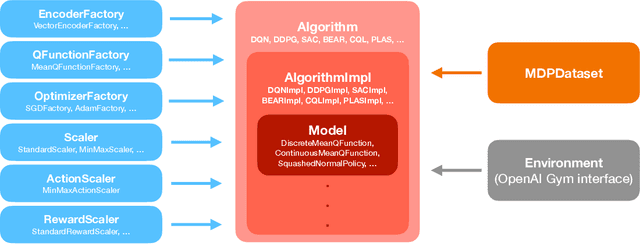
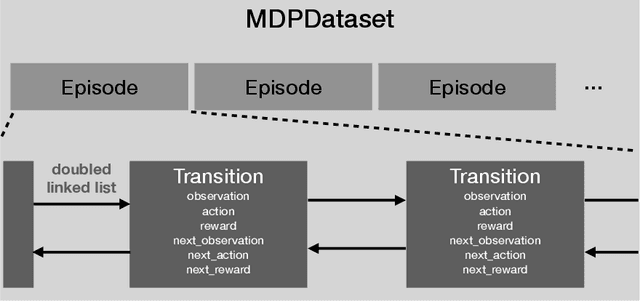
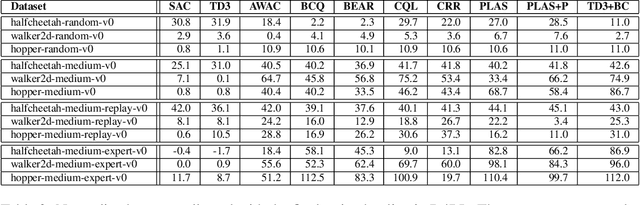
In this paper, we introduce d3rlpy, an open-sourced offline deep reinforcement learning (RL) library for Python. d3rlpy supports a number of offline deep RL algorithms as well as online algorithms via a user-friendly API. To assist deep RL research and development projects, d3rlpy provides practical and unique features such as data collection, exporting policies for deployment, preprocessing and postprocessing, distributional Q-functions, multi-step learning and a convenient command-line interface. Furthermore, d3rlpy additionally provides a novel graphical interface that enables users to train offline RL algorithms without coding programs. Lastly, the implemented algorithms are benchmarked with D4RL datasets to ensure the implementation quality. The d3rlpy source code can be found on GitHub: \url{https://github.com/takuseno/d3rlpy}.
Unified Questioner Transformer for Descriptive Question Generation in Goal-Oriented Visual Dialogue
Jun 29, 2021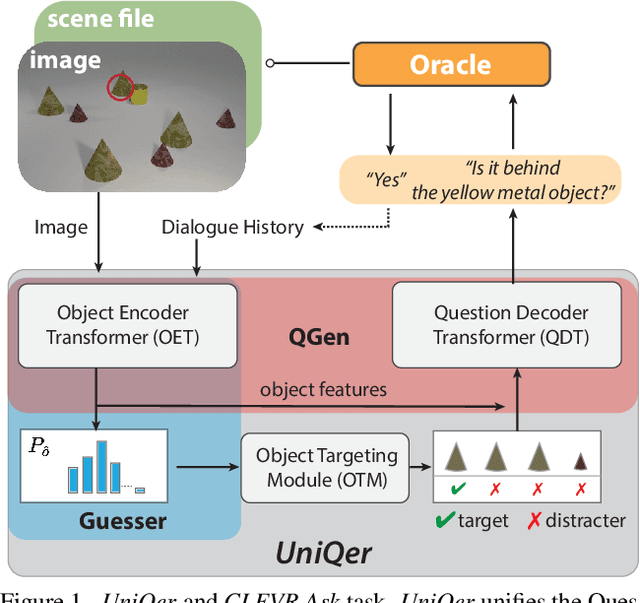
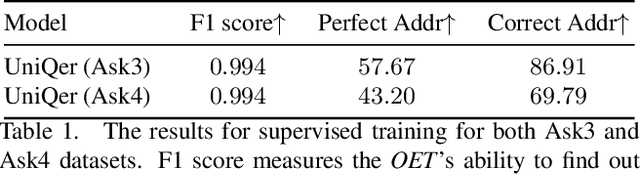
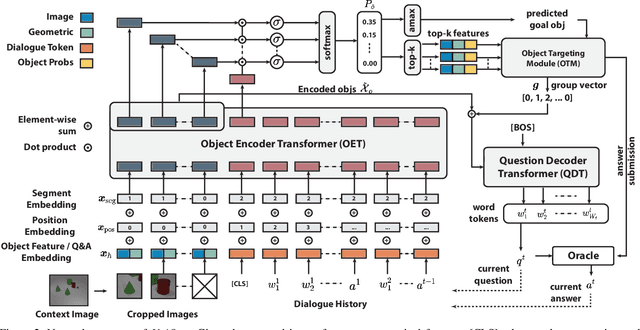
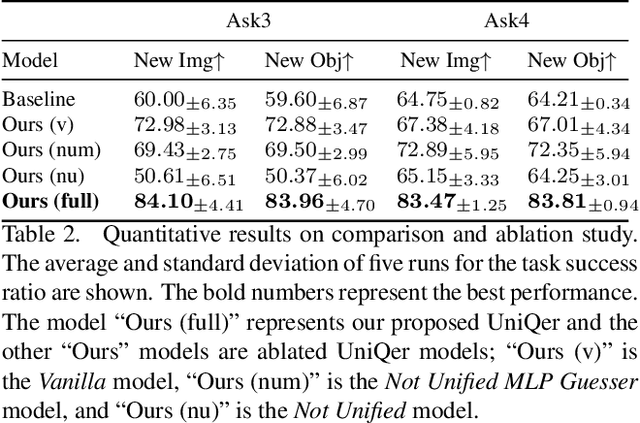
Building an interactive artificial intelligence that can ask questions about the real world is one of the biggest challenges for vision and language problems. In particular, goal-oriented visual dialogue, where the aim of the agent is to seek information by asking questions during a turn-taking dialogue, has been gaining scholarly attention recently. While several existing models based on the GuessWhat?! dataset have been proposed, the Questioner typically asks simple category-based questions or absolute spatial questions. This might be problematic for complex scenes where the objects share attributes or in cases where descriptive questions are required to distinguish objects. In this paper, we propose a novel Questioner architecture, called Unified Questioner Transformer (UniQer), for descriptive question generation with referring expressions. In addition, we build a goal-oriented visual dialogue task called CLEVR Ask. It synthesizes complex scenes that require the Questioner to generate descriptive questions. We train our model with two variants of CLEVR Ask datasets. The results of the quantitative and qualitative evaluations show that UniQer outperforms the baseline.
SLAM-Inspired Simultaneous Contextualization and Interpreting for Incremental Conversation Sentences
May 29, 2020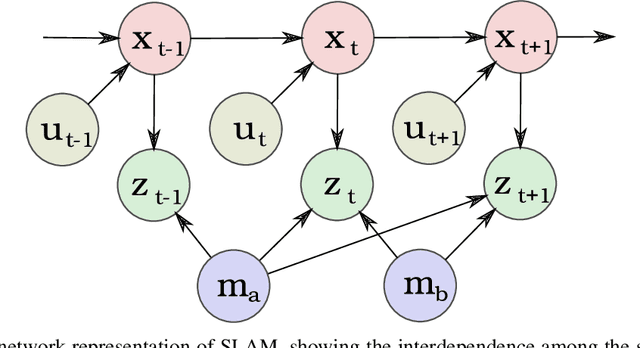
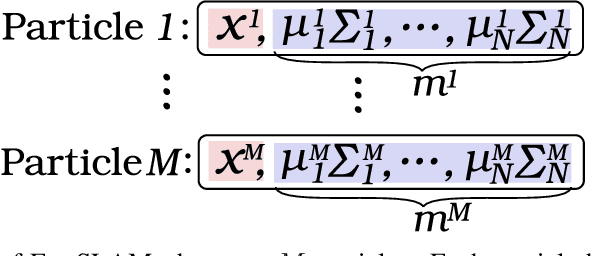
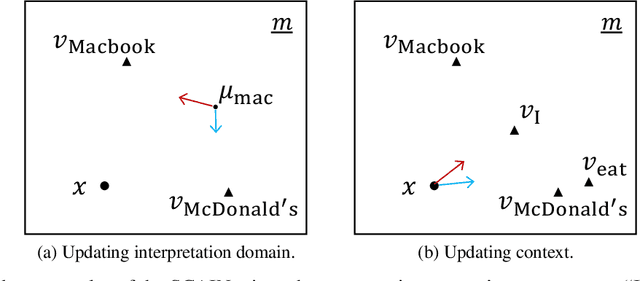
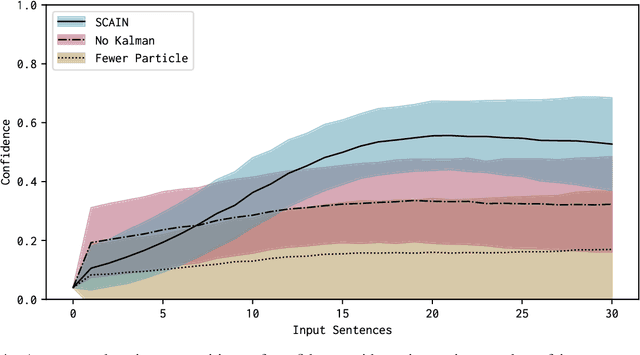
Distributed representation of words has improved the performance for many natural language tasks. In many methods, however, only one meaning is considered for one label of a word, and multiple meanings of polysemous words depending on the context are rarely handled. Although research works have dealt with polysemous words, they determine the meanings of such words according to a batch of large documents. Hence, there are two problems with applying these methods to sequential sentences, as in a conversation that contains ambiguous expressions. The first problem is that the methods cannot sequentially deal with the interdependence between context and word interpretation, in which context is decided by word interpretations and the word interpretations are decided by the context. Context estimation must thus be performed in parallel to pursue multiple interpretations. The second problem is that the previous methods use large-scale sets of sentences for offline learning of new interpretations, and the steps of learning and inference are clearly separated. Such methods using offline learning cannot obtain new interpretations during a conversation. Hence, to dynamically estimate the conversation context and interpretations of polysemous words in sequential sentences, we propose a method of Simultaneous Contextualization And INterpreting (SCAIN) based on the traditional Simultaneous Localization And Mapping (SLAM) algorithm. By using the SCAIN algorithm, we can sequentially optimize the interdependence between context and word interpretation while obtaining new interpretations online. For experimental evaluation, we created two datasets: one from Wikipedia's disambiguation pages and the other from real conversations. For both datasets, the results confirmed that SCAIN could effectively achieve sequential optimization of the interdependence and acquisition of new interpretations.
Autonomous Self-Explanation of Behavior for Interactive Reinforcement Learning Agents
Oct 20, 2018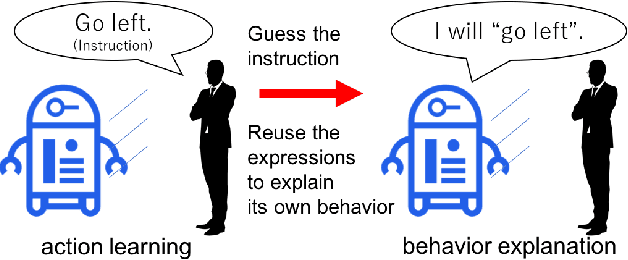
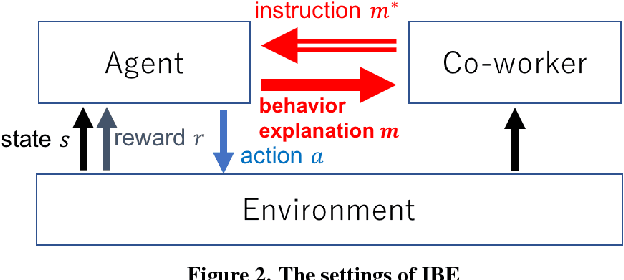

In cooperation, the workers must know how co-workers behave. However, an agent's policy, which is embedded in a statistical machine learning model, is hard to understand, and requires much time and knowledge to comprehend. Therefore, it is difficult for people to predict the behavior of machine learning robots, which makes Human Robot Cooperation challenging. In this paper, we propose Instruction-based Behavior Explanation (IBE), a method to explain an autonomous agent's future behavior. In IBE, an agent can autonomously acquire the expressions to explain its own behavior by reusing the instructions given by a human expert to accelerate the learning of the agent's policy. IBE also enables a developmental agent, whose policy may change during the cooperation, to explain its own behavior with sufficient time granularity.
Bayesian Inference of Self-intention Attributed by Observer
Oct 12, 2018
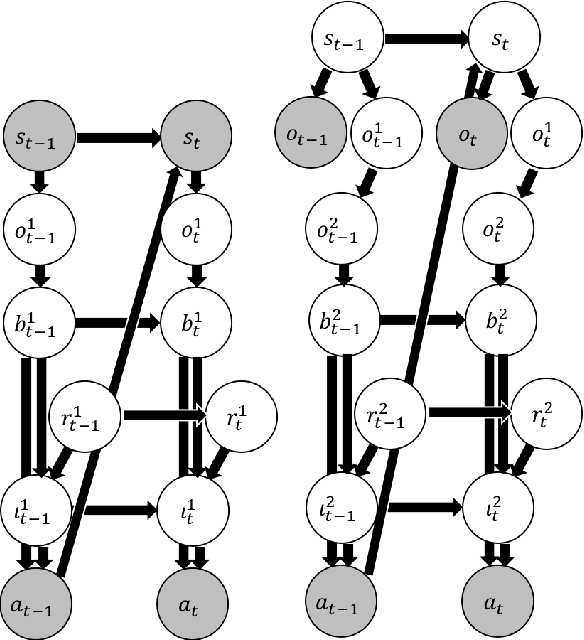
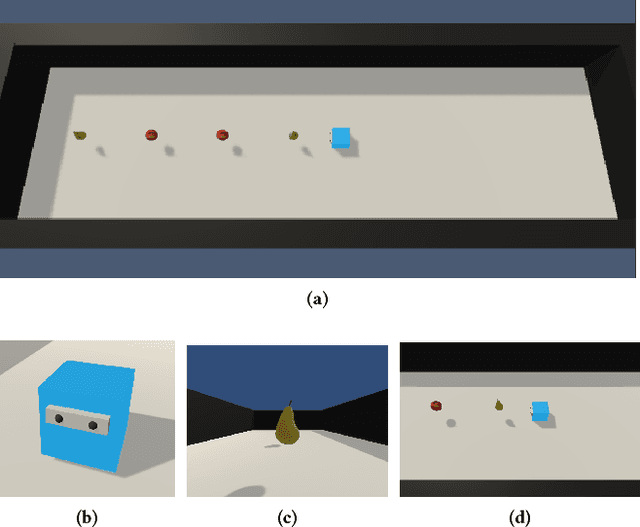
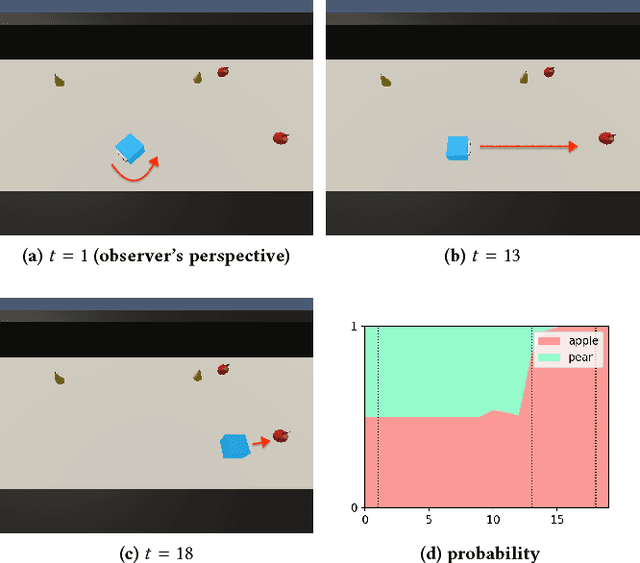
Most of agents that learn policy for tasks with reinforcement learning (RL) lack the ability to communicate with people, which makes human-agent collaboration challenging. We believe that, in order for RL agents to comprehend utterances from human colleagues, RL agents must infer the mental states that people attribute to them because people sometimes infer an interlocutor's mental states and communicate on the basis of this mental inference. This paper proposes PublicSelf model, which is a model of a person who infers how the person's own behavior appears to their colleagues. We implemented the PublicSelf model for an RL agent in a simulated environment and examined the inference of the model by comparing it with people's judgment. The results showed that the agent's intention that people attributed to the agent's movement was correctly inferred by the model in scenes where people could find certain intentionality from the agent's behavior.