 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatteGAN: Visually Guided Language Attention for Multi-Turn Text-Conditioned Image Manipulation
Paper and Code
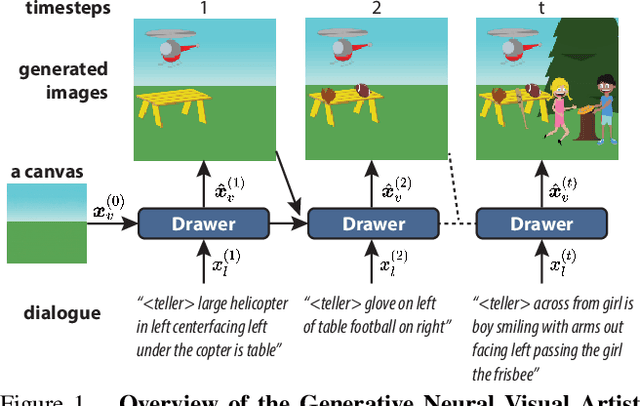
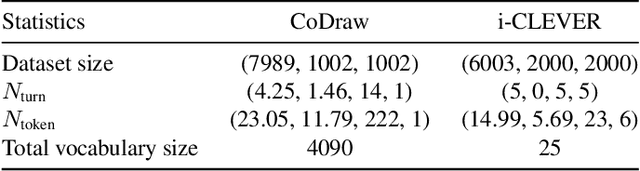
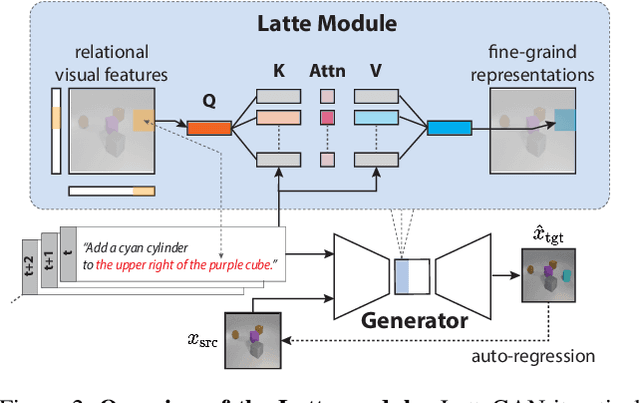
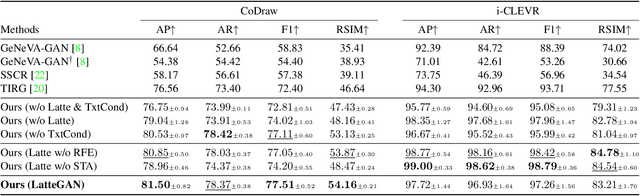
Text-guided image manipulation tasks have recently gained attention in the vision-and-language community. While most of the prior studies focused on single-turn manipulation, our goal in this paper is to address the more challenging multi-turn image manipulation (MTIM) task. Previous models for this task successfully generate images iteratively, given a sequence of instructions and a previously generated image. However, this approach suffers from under-generation and a lack of generated quality of the objects that are described in the instructions, which consequently degrades the overall performance. To overcome these problems, we present a novel architecture called a Visually Guided Language Attention GAN (LatteGAN). Here, we address the limitations of the previous approaches by introducing a Visually Guided Language Attention (Latte) module, which extracts fine-grained text representations for the generator, and a Text-Conditioned U-Net discriminator architecture, which discriminates both the global and local representations of fake or real images. Extensive experiments on two distinct MTIM datasets, CoDraw and i-CLEVR, demonstrate the state-of-the-art performance of the proposed model.