 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatteGAN: Visually Guided Language Attention for Multi-Turn Text-Conditioned Image Manipulation
Dec 28, 2021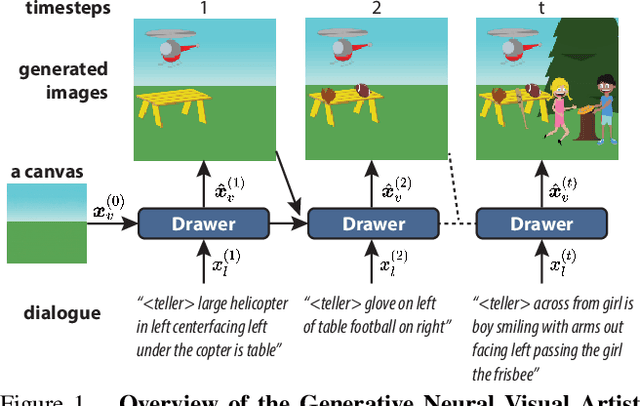
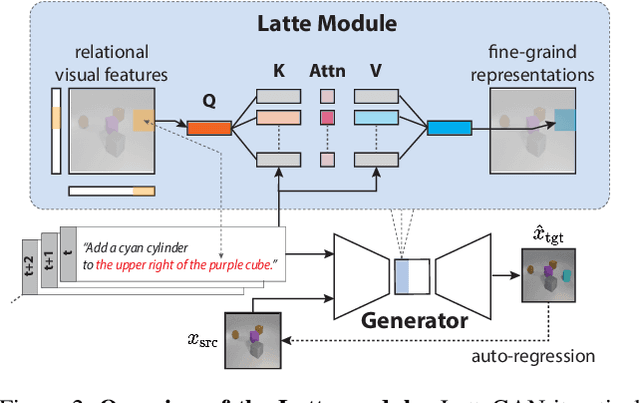
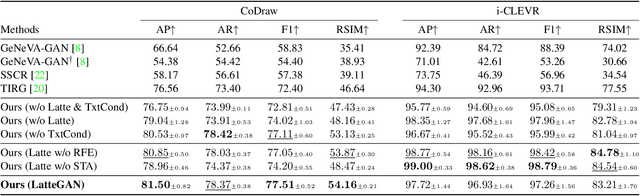
Text-guided image manipulation tasks have recently gained attention in the vision-and-language community. While most of the prior studies focused on single-turn manipulation, our goal in this paper is to address the more challenging multi-turn image manipulation (MTIM) task. Previous models for this task successfully generate images iteratively, given a sequence of instructions and a previously generated image. However, this approach suffers from under-generation and a lack of generated quality of the objects that are described in the instructions, which consequently degrades the overall performance. To overcome these problems, we present a novel architecture called a Visually Guided Language Attention GAN (LatteGAN). Here, we address the limitations of the previous approaches by introducing a Visually Guided Language Attention (Latte) module, which extracts fine-grained text representations for the generator, and a Text-Conditioned U-Net discriminator architecture, which discriminates both the global and local representations of fake or real images. Extensive experiments on two distinct MTIM datasets, CoDraw and i-CLEVR, demonstrate the state-of-the-art performance of the proposed model.
Unified Questioner Transformer for Descriptive Question Generation in Goal-Oriented Visual Dialogue
Jun 29, 2021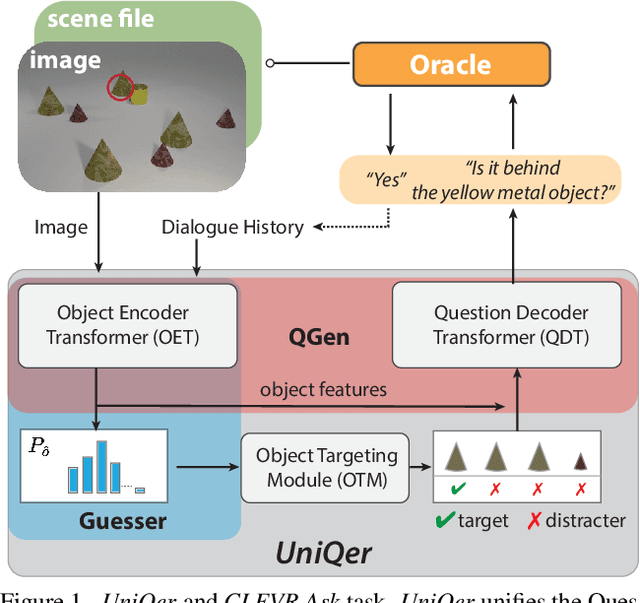
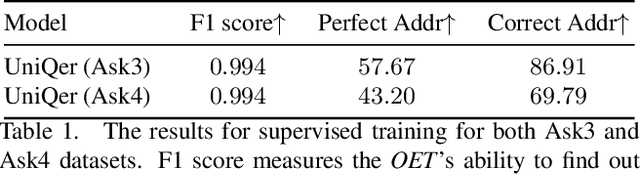
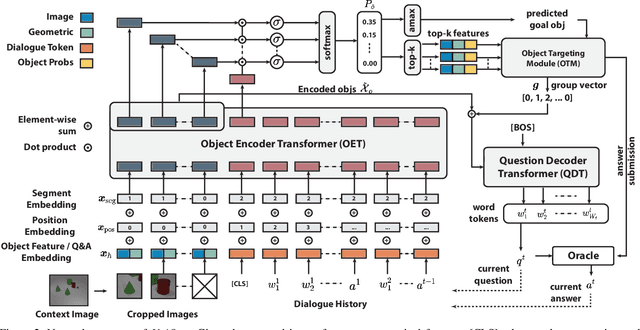
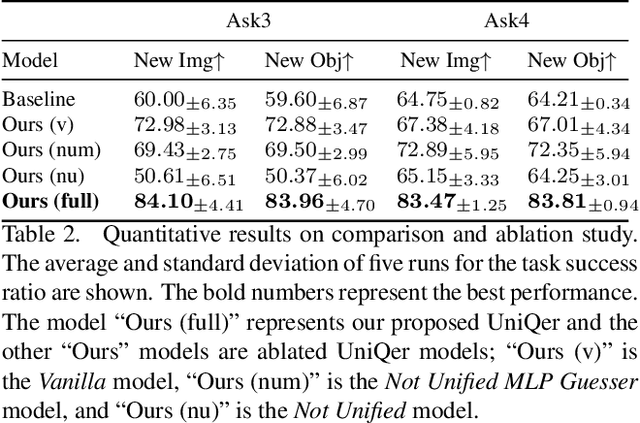
Building an interactive artificial intelligence that can ask questions about the real world is one of the biggest challenges for vision and language problems. In particular, goal-oriented visual dialogue, where the aim of the agent is to seek information by asking questions during a turn-taking dialogue, has been gaining scholarly attention recently. While several existing models based on the GuessWhat?! dataset have been proposed, the Questioner typically asks simple category-based questions or absolute spatial questions. This might be problematic for complex scenes where the objects share attributes or in cases where descriptive questions are required to distinguish objects. In this paper, we propose a novel Questioner architecture, called Unified Questioner Transformer (UniQer), for descriptive question generation with referring expressions. In addition, we build a goal-oriented visual dialogue task called CLEVR Ask. It synthesizes complex scenes that require the Questioner to generate descriptive questions. We train our model with two variants of CLEVR Ask datasets. The results of the quantitative and qualitative evaluations show that UniQer outperforms the baseline.