 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould XAI Nudge Human Decisions with Explanation Biasing?
Jun 11, 2024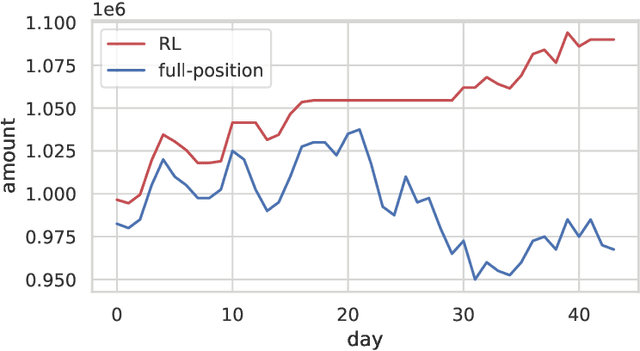

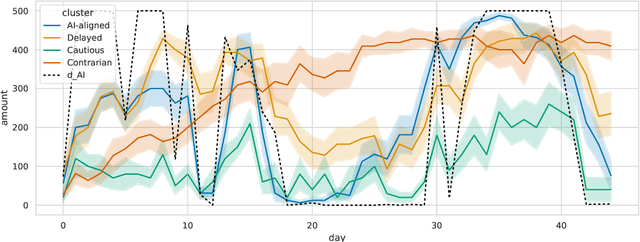
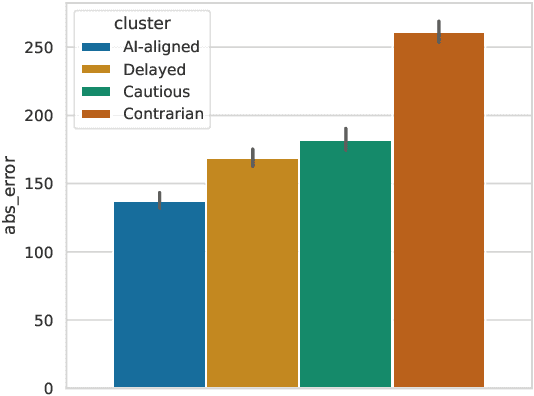
This paper reviews our previous trials of Nudge-XAI, an approach that introduces automatic biases into explanations from explainable AIs (XAIs) with the aim of leading users to better decisions, and it discusses the benefits and challenges. Nudge-XAI uses a user model that predicts the influence of providing an explanation or emphasizing it and attempts to guide users toward AI-suggested decisions without coercion. The nudge design is expected to enhance the autonomy of users, reduce the risk associated with an AI making decisions without users' full agreement, and enable users to avoid AI failures. To discuss the potential of Nudge-XAI, this paper reports a post-hoc investigation of previous experimental results using cluster analysis. The results demonstrate the diversity of user behavior in response to Nudge-XAI, which supports our aim of enhancing user autonomy. However, it also highlights the challenge of users who distrust AI and falsely make decisions contrary to AI suggestions, suggesting the need for personalized adjustment of the strength of nudges to make this approach work more generally.
Dynamic Explanation Emphasis in Human-XAI Interaction with Communication Robot
Mar 21, 2024Communication robots have the potential to contribute to effective human-XAI interaction as an interface that goes beyond textual or graphical explanations. One of their strengths is that they can use physical and vocal expressions to add detailed nuances to explanations. However, it is not clear how a robot can apply such expressions, or in particular, how we can develop a strategy to adaptively use such expressions depending on the task and user in dynamic interactions. To address this question, this paper proposes DynEmph, a method for a communication robot to decide where to emphasize XAI-generated explanations with physical expressions. It predicts the effect of emphasizing certain points on a user and aims to minimize the expected difference between predicted user decisions and AI-suggested ones. DynEmph features a strategy for deciding where to emphasize in a data-driven manner, relieving engineers from the need to manually design a strategy. We further conducted experiments to investigate how emphasis selection strategies affect the performance of user decisions. The results suggest that, while a naive strategy (emphasizing explanations for an AI's most probable class) does not necessarily work better, DynEmph effectively guides users to better decisions under the condition that the performance of the AI suggestion is high.
Dynamic Explanation Selection Towards Successful User-Decision Support with Explainable AI
Feb 28, 2024This paper addresses the problem of how to select explanations for XAI (Explainable AI)-based Intelligent Decision Support Systems (IDSSs). IDSSs have shown promise in improving user decisions through XAI-generated explanations along with AI predictions. As the development of XAI made various explanations available, we believe that IDSSs can be greatly improved if they can strategically select explanations that guide users to better decisions. This paper proposes X-Selector, a method for dynamically selecting explanations. X-Selector aims to guide users to better decisions by predicting the impact of different combinations of explanations on user decisions. We compared X-Selector's performance with two naive strategies (all possible explanations and explanations only for the most likely prediction) and two baselines (no explanation and no AI support). The results suggest the potential of X-Selector to guide users to recommended decisions and improve the performance when AI accuracy is high and a challenge when it is low.
Selectively Providing Reliance Calibration Cues With Reliance Prediction
Feb 20, 2023

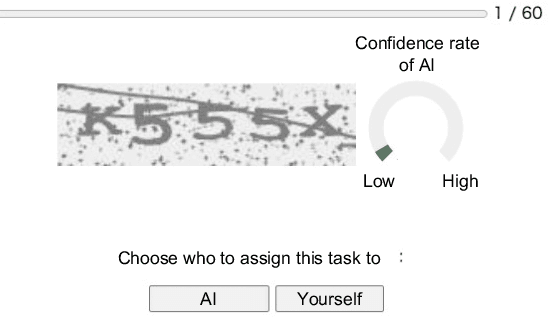

For effective collaboration between humans and intelligent agents that employ machine learning for decision-making, humans must understand what agents can and cannot do to avoid over/under-reliance. A solution to this problem is adjusting human reliance through communication using reliance calibration cues (RCCs) to help humans assess agents' capabilities. Previous studies typically attempted to calibrate reliance by continuously presenting RCCs, and when an agent should provide RCCs remains an open question. To answer this, we propose Pred-RC, a method for selectively providing RCCs. Pred-RC uses a cognitive reliance model to predict whether a human will assign a task to an agent. By comparing the prediction results for both cases with and without an RCC, Pred-RC evaluates the influence of the RCC on human reliance. We tested Pred-RC in a human-AI collaboration task and found that it can successfully calibrate human reliance with a reduced number of RCCs.
Unified Questioner Transformer for Descriptive Question Generation in Goal-Oriented Visual Dialogue
Jun 29, 2021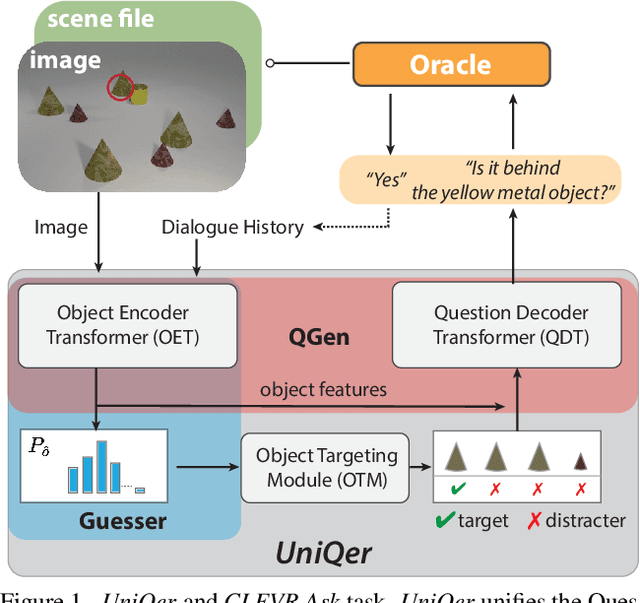
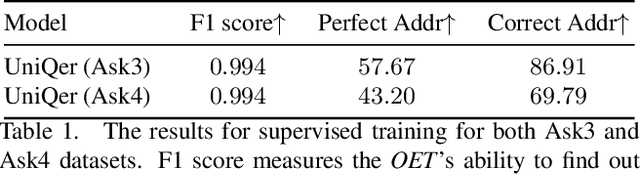
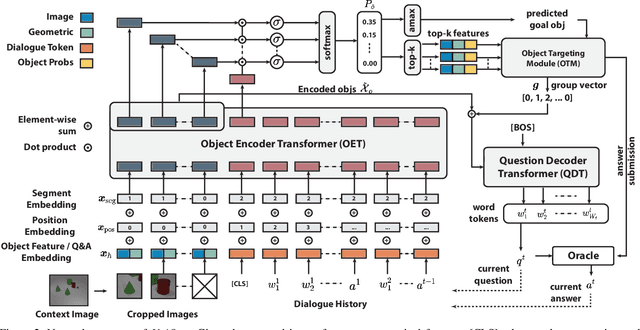
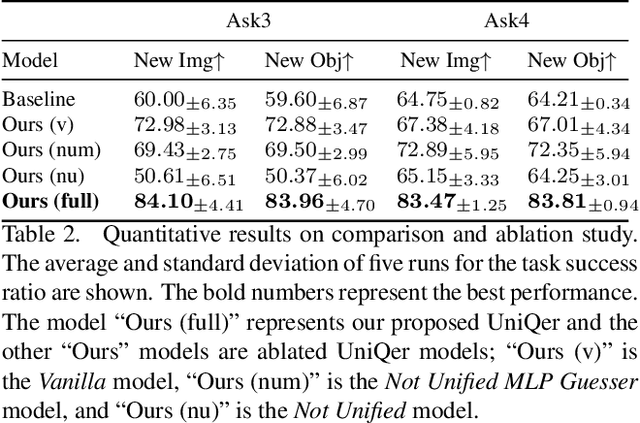
Building an interactive artificial intelligence that can ask questions about the real world is one of the biggest challenges for vision and language problems. In particular, goal-oriented visual dialogue, where the aim of the agent is to seek information by asking questions during a turn-taking dialogue, has been gaining scholarly attention recently. While several existing models based on the GuessWhat?! dataset have been proposed, the Questioner typically asks simple category-based questions or absolute spatial questions. This might be problematic for complex scenes where the objects share attributes or in cases where descriptive questions are required to distinguish objects. In this paper, we propose a novel Questioner architecture, called Unified Questioner Transformer (UniQer), for descriptive question generation with referring expressions. In addition, we build a goal-oriented visual dialogue task called CLEVR Ask. It synthesizes complex scenes that require the Questioner to generate descriptive questions. We train our model with two variants of CLEVR Ask datasets. The results of the quantitative and qualitative evaluations show that UniQer outperforms the baseline.
SLAM-Inspired Simultaneous Contextualization and Interpreting for Incremental Conversation Sentences
May 29, 2020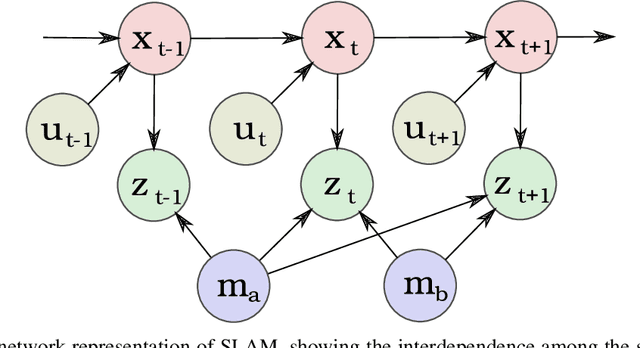
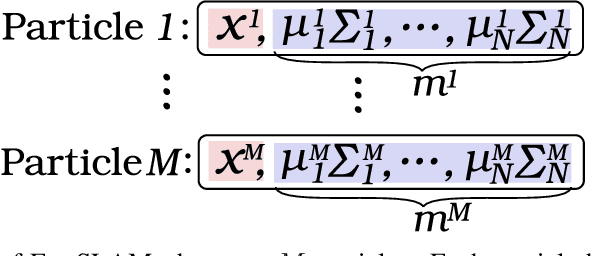
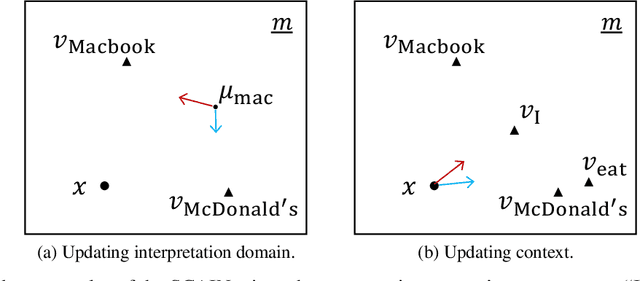
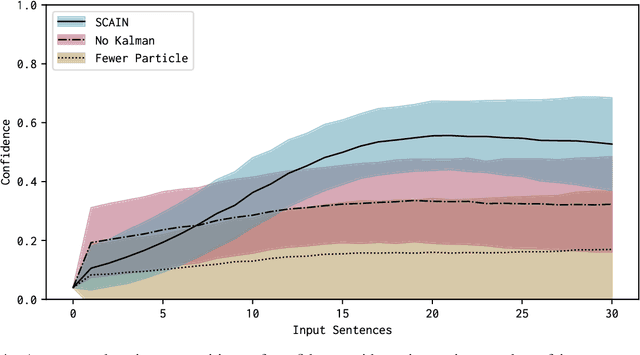
Distributed representation of words has improved the performance for many natural language tasks. In many methods, however, only one meaning is considered for one label of a word, and multiple meanings of polysemous words depending on the context are rarely handled. Although research works have dealt with polysemous words, they determine the meanings of such words according to a batch of large documents. Hence, there are two problems with applying these methods to sequential sentences, as in a conversation that contains ambiguous expressions. The first problem is that the methods cannot sequentially deal with the interdependence between context and word interpretation, in which context is decided by word interpretations and the word interpretations are decided by the context. Context estimation must thus be performed in parallel to pursue multiple interpretations. The second problem is that the previous methods use large-scale sets of sentences for offline learning of new interpretations, and the steps of learning and inference are clearly separated. Such methods using offline learning cannot obtain new interpretations during a conversation. Hence, to dynamically estimate the conversation context and interpretations of polysemous words in sequential sentences, we propose a method of Simultaneous Contextualization And INterpreting (SCAIN) based on the traditional Simultaneous Localization And Mapping (SLAM) algorithm. By using the SCAIN algorithm, we can sequentially optimize the interdependence between context and word interpretation while obtaining new interpretations online. For experimental evaluation, we created two datasets: one from Wikipedia's disambiguation pages and the other from real conversations. For both datasets, the results confirmed that SCAIN could effectively achieve sequential optimization of the interdependence and acquisition of new interpretations.
Autonomous Self-Explanation of Behavior for Interactive Reinforcement Learning Agents
Oct 20, 2018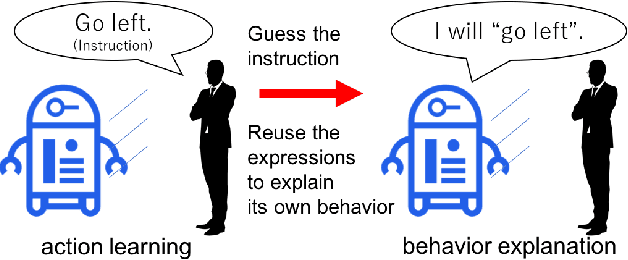
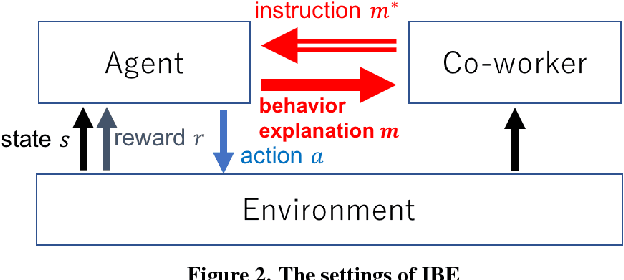

In cooperation, the workers must know how co-workers behave. However, an agent's policy, which is embedded in a statistical machine learning model, is hard to understand, and requires much time and knowledge to comprehend. Therefore, it is difficult for people to predict the behavior of machine learning robots, which makes Human Robot Cooperation challenging. In this paper, we propose Instruction-based Behavior Explanation (IBE), a method to explain an autonomous agent's future behavior. In IBE, an agent can autonomously acquire the expressions to explain its own behavior by reusing the instructions given by a human expert to accelerate the learning of the agent's policy. IBE also enables a developmental agent, whose policy may change during the cooperation, to explain its own behavior with sufficient time granularity.
Bayesian Inference of Self-intention Attributed by Observer
Oct 12, 2018
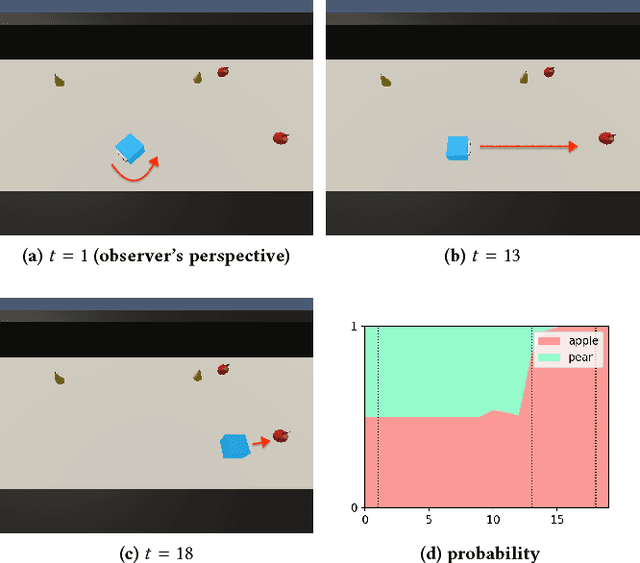
Most of agents that learn policy for tasks with reinforcement learning (RL) lack the ability to communicate with people, which makes human-agent collaboration challenging. We believe that, in order for RL agents to comprehend utterances from human colleagues, RL agents must infer the mental states that people attribute to them because people sometimes infer an interlocutor's mental states and communicate on the basis of this mental inference. This paper proposes PublicSelf model, which is a model of a person who infers how the person's own behavior appears to their colleagues. We implemented the PublicSelf model for an RL agent in a simulated environment and examined the inference of the model by comparing it with people's judgment. The results showed that the agent's intention that people attributed to the agent's movement was correctly inferred by the model in scenes where people could find certain intentionality from the agent's behavior.