 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot can reduce superior's dominance in group discussions with human social hierarchy
Aug 12, 2025This study investigated whether robotic agents that deal with social hierarchical relationships can reduce the dominance of superiors and equalize participation among participants in discussions with hierarchical structures. Thirty doctors and students having hierarchical relationship were gathered as participants, and an intervention experiment was conducted using a robot that can encourage participants to speak depending on social hierarchy. These were compared with strategies that intervened equally for all participants without considering hierarchy and with a no-action. The robots performed follow actions, showing backchanneling to speech, and encourage actions, prompting speech from members with less speaking time, on the basis of the hierarchical relationships among group members to equalize participation. The experimental results revealed that the robot's actions could potentially influence the speaking time among members, but it could not be conclusively stated that there were significant differences between the robot's action conditions. However, the results suggested that it might be possible to influence speaking time without decreasing the satisfaction of superiors. This indicates that in discussion scenarios where experienced superiors are likely to dominate, controlling the robot's backchanneling behavior could potentially suppress dominance and equalize participation among group members.
Predicting Trust Dynamics with Dynamic SEM in Human-AI Cooperation
Jul 01, 2024



Humans' trust in AI constitutes a pivotal element in fostering a synergistic relationship between humans and AI. This is particularly significant in the context of systems that leverage AI technology, such as autonomous driving systems and human-robot interaction. Trust facilitates appropriate utilization of these systems, thereby optimizing their potential benefits. If humans over-trust or under-trust an AI, serious problems such as misuse and accidents occur. To prevent over/under-trust, it is necessary to predict trust dynamics. However, trust is an internal state of humans and hard to directly observe. Therefore, we propose a prediction model for trust dynamics using dynamic structure equation modeling, which extends SEM that can handle time-series data. A path diagram, which shows causalities between variables, is developed in an exploratory way and the resultant path diagram is optimized for effective path structures. Over/under-trust was predicted with 90\% accuracy in a drone simulator task,, and it was predicted with 99\% accuracy in an autonomous driving task. These results show that our proposed method outperformed the conventional method including an auto regression family.
Should XAI Nudge Human Decisions with Explanation Biasing?
Jun 11, 2024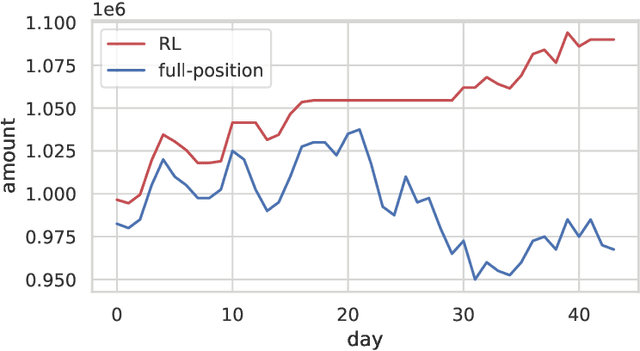

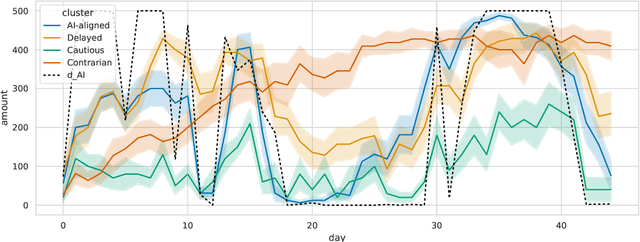
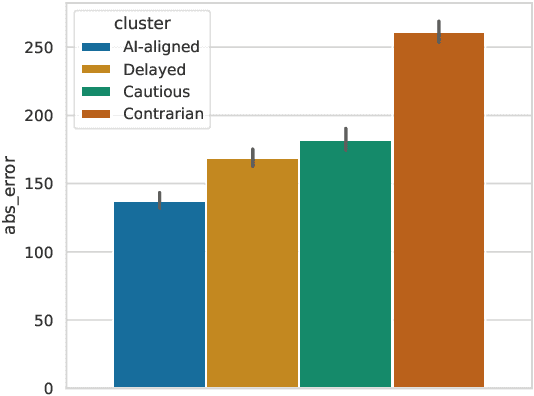
This paper reviews our previous trials of Nudge-XAI, an approach that introduces automatic biases into explanations from explainable AIs (XAIs) with the aim of leading users to better decisions, and it discusses the benefits and challenges. Nudge-XAI uses a user model that predicts the influence of providing an explanation or emphasizing it and attempts to guide users toward AI-suggested decisions without coercion. The nudge design is expected to enhance the autonomy of users, reduce the risk associated with an AI making decisions without users' full agreement, and enable users to avoid AI failures. To discuss the potential of Nudge-XAI, this paper reports a post-hoc investigation of previous experimental results using cluster analysis. The results demonstrate the diversity of user behavior in response to Nudge-XAI, which supports our aim of enhancing user autonomy. However, it also highlights the challenge of users who distrust AI and falsely make decisions contrary to AI suggestions, suggesting the need for personalized adjustment of the strength of nudges to make this approach work more generally.
Dynamic Explanation Emphasis in Human-XAI Interaction with Communication Robot
Mar 21, 2024Communication robots have the potential to contribute to effective human-XAI interaction as an interface that goes beyond textual or graphical explanations. One of their strengths is that they can use physical and vocal expressions to add detailed nuances to explanations. However, it is not clear how a robot can apply such expressions, or in particular, how we can develop a strategy to adaptively use such expressions depending on the task and user in dynamic interactions. To address this question, this paper proposes DynEmph, a method for a communication robot to decide where to emphasize XAI-generated explanations with physical expressions. It predicts the effect of emphasizing certain points on a user and aims to minimize the expected difference between predicted user decisions and AI-suggested ones. DynEmph features a strategy for deciding where to emphasize in a data-driven manner, relieving engineers from the need to manually design a strategy. We further conducted experiments to investigate how emphasis selection strategies affect the performance of user decisions. The results suggest that, while a naive strategy (emphasizing explanations for an AI's most probable class) does not necessarily work better, DynEmph effectively guides users to better decisions under the condition that the performance of the AI suggestion is high.
Dynamic Explanation Selection Towards Successful User-Decision Support with Explainable AI
Feb 28, 2024This paper addresses the problem of how to select explanations for XAI (Explainable AI)-based Intelligent Decision Support Systems (IDSSs). IDSSs have shown promise in improving user decisions through XAI-generated explanations along with AI predictions. As the development of XAI made various explanations available, we believe that IDSSs can be greatly improved if they can strategically select explanations that guide users to better decisions. This paper proposes X-Selector, a method for dynamically selecting explanations. X-Selector aims to guide users to better decisions by predicting the impact of different combinations of explanations on user decisions. We compared X-Selector's performance with two naive strategies (all possible explanations and explanations only for the most likely prediction) and two baselines (no explanation and no AI support). The results suggest the potential of X-Selector to guide users to recommended decisions and improve the performance when AI accuracy is high and a challenge when it is low.
Selectively Providing Reliance Calibration Cues With Reliance Prediction
Feb 20, 2023

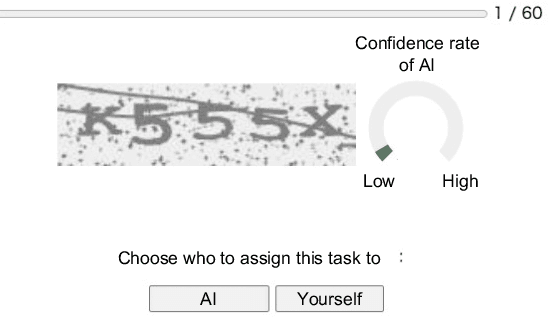

For effective collaboration between humans and intelligent agents that employ machine learning for decision-making, humans must understand what agents can and cannot do to avoid over/under-reliance. A solution to this problem is adjusting human reliance through communication using reliance calibration cues (RCCs) to help humans assess agents' capabilities. Previous studies typically attempted to calibrate reliance by continuously presenting RCCs, and when an agent should provide RCCs remains an open question. To answer this, we propose Pred-RC, a method for selectively providing RCCs. Pred-RC uses a cognitive reliance model to predict whether a human will assign a task to an agent. By comparing the prediction results for both cases with and without an RCC, Pred-RC evaluates the influence of the RCC on human reliance. We tested Pred-RC in a human-AI collaboration task and found that it can successfully calibrate human reliance with a reduced number of RCCs.
Modeling Trust and Reliance with Wait Time in a Human-Robot Interaction
Feb 16, 2023This study investigated how wait time influences trust in and reliance on a robot. Experiment 1 was conducted as an online experiment manipulating the wait time for the task partner's action from 1 to 20 seconds and the anthropomorphism of the partner. As a result, the anthropomorphism influenced trust in the partner and did not influence reliance on the partner. However, the wait time negatively influenced trust in and reliance on the partner. Moreover, a mediation effect of trust from the wait time on reliance on the partner was confirmed. Experiment 2 was conducted to confirm the effects of wait time on trust and reliance in a human-robot face-to-face situation. As a result, the same effects of wait time found in Experiment 1 were confirmed. This study revealed that wait time is a strong and controllable factor that influences trust in and reliance on a robot.
D-Graph: AI-Assisted Design Concept Exploration Graph
Jan 11, 2022We present an AI-assisted search tool, the "Design Concept Exploration Graph" ("D-Graph"). It assists automotive designers in creating an original design-concept phrase, that is, a combination of two adjectives that conveys product aesthetics. D-Graph retrieves adjectives from a ConceptNet knowledge graph as nodes and visualizes them in a dynamically scalable 3D graph as users explore words. The retrieval algorithm helps in finding unique words by ruling out overused words on the basis of word frequency from a large text corpus and words that are too similar between the two in a combination using the cosine similarity from ConceptNet Numberbatch word embeddings. Our experiment with participants in the automotive design field that used both the proposed D-Graph and a baseline tool for design-concept-phrase creation tasks suggested a positive difference in participants' self-evaluation on the phrases they created, though not significant. Experts' evaluations on the phrases did not show significant differences. Negative correlations between the cosine similarity of the two words in a design-concept phrase and the experts' evaluation were significant. Our qualitative analysis suggested the directions for further development of the tool that should help users in adhering to the strategy of creating compound phrases supported by computational linguistic principles.
Balancing Performance and Human Autonomy with Implicit Guidance Agent
Sep 01, 2021



The human-agent team, which is a problem in which humans and autonomous agents collaborate to achieve one task, is typical in human-AI collaboration. For effective collaboration, humans want to have an effective plan, but in realistic situations, they might have difficulty calculating the best plan due to cognitive limitations. In this case, guidance from an agent that has many computational resources may be useful. However, if an agent guides the human behavior explicitly, the human may feel that they have lost autonomy and are being controlled by the agent. We therefore investigated implicit guidance offered by means of an agent's behavior. With this type of guidance, the agent acts in a way that makes it easy for the human to find an effective plan for a collaborative task, and the human can then improve the plan. Since the human improves their plan voluntarily, he or she maintains autonomy. We modeled a collaborative agent with implicit guidance by integrating the Bayesian Theory of Mind into existing collaborative-planning algorithms and demonstrated through a behavioral experiment that implicit guidance is effective for enabling humans to maintain a balance between improving their plans and retaining autonomy.
Empirical Investigation of Factors that Influence Human Presence and Agency in Telepresence Robot
May 25, 2021

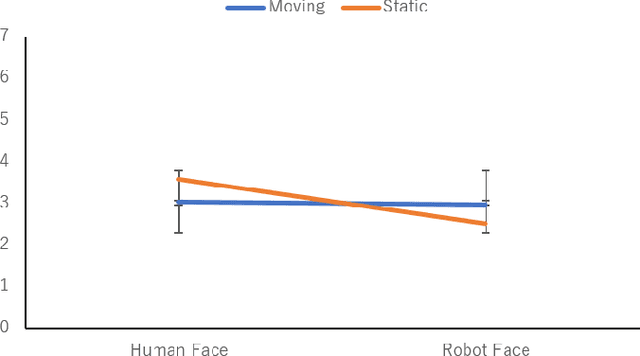

Nowadays, a community starts to find the need for human presence in an alternative way, there has been tremendous research and development in advancing telepresence robots. People tend to feel closer and more comfortable with telepresence robots as many senses a human presence in robots. In general, many people feel the sense of agency from the face of a robot, but some telepresence robots without arm and body motions tend to give a sense of human presence. It is important to identify and configure how the telepresence robots affect a sense of presence and agency to people by including human face and slight face and arm motions. Therefore, we carried out extensive research via web-based experiment to determine the prototype that can result in soothing human interaction with the robot. The experiments featured videos of a telepresence robot n = 128, 2 x 2 between-participant study robot face factor: video-conference, robot-like face; arm motion factor: moving vs. static) to investigate the factors significantly affecting human presence and agency with the robot. We used two telepresence robots: an affordable robot platform and a modified version for human interaction enhancements. The findings suggest that participants feel agency that is closer to human-likeness when the robot's face was replaced with a human's face and without a motion. The robot's motion invokes a feeling of human presence whether the face is human or robot-like.