 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgoal-based Reward Shaping to Improve Efficiency in Reinforcement Learning
Paper and Code
Apr 13, 2021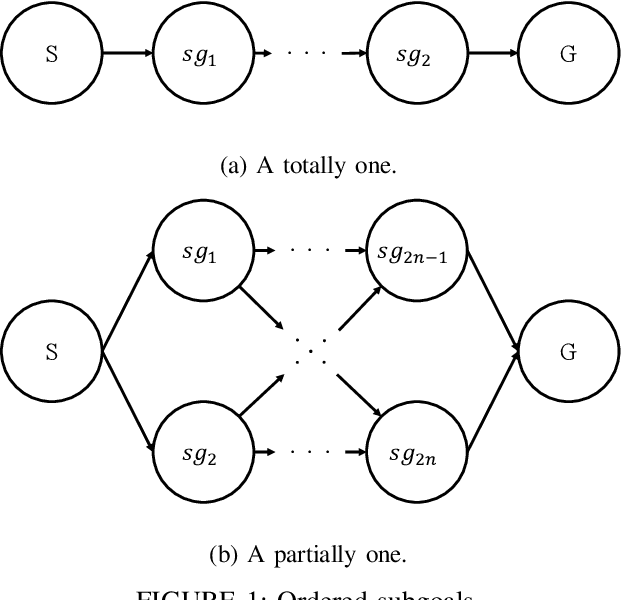
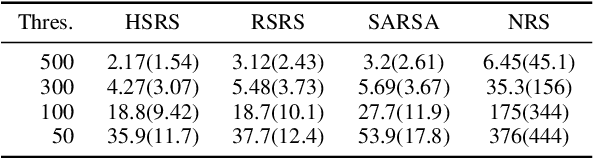
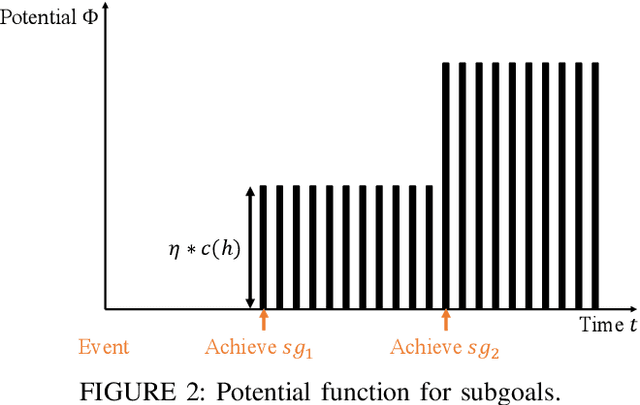

Reinforcement learning, which acquires a policy maximizing long-term rewards, has been actively studied. Unfortunately, this learning type is too slow and difficult to use in practical situations because the state-action space becomes huge in real environments. Many studies have incorporated human knowledge into reinforcement Learning. Though human knowledge on trajectories is often used, a human could be asked to control an AI agent, which can be difficult. Knowledge on subgoals may lessen this requirement because humans need only to consider a few representative states on an optimal trajectory in their minds. The essential factor for learning efficiency is rewards. Potential-based reward shaping is a basic method for enriching rewards. However, it is often difficult to incorporate subgoals for accelerating learning over potential-based reward shaping. This is because the appropriate potentials are not intuitive for humans. We extend potential-based reward shaping and propose a subgoal-based reward shaping. The method makes it easier for human trainers to share their knowledge of subgoals. To evaluate our method, we obtained a subgoal series from participants and conducted experiments in three domains, four-rooms(discrete states and discrete actions), pinball(continuous and discrete), and picking(both continuous). We compared our method with a baseline reinforcement learning algorithm and other subgoal-based methods, including random subgoal and naive subgoal-based reward shaping. As a result, we found out that our reward shaping outperformed all other methods in learning efficiency.