 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgoal-based Reward Shaping to Improve Efficiency in Reinforcement Learning
Apr 13, 2021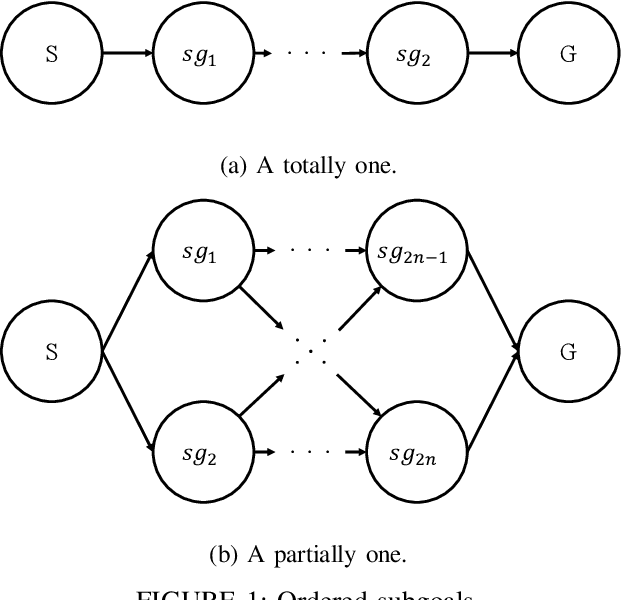
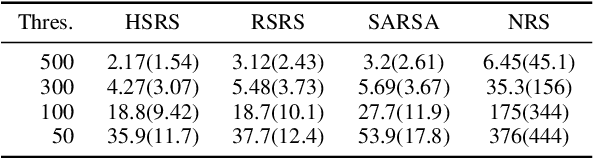
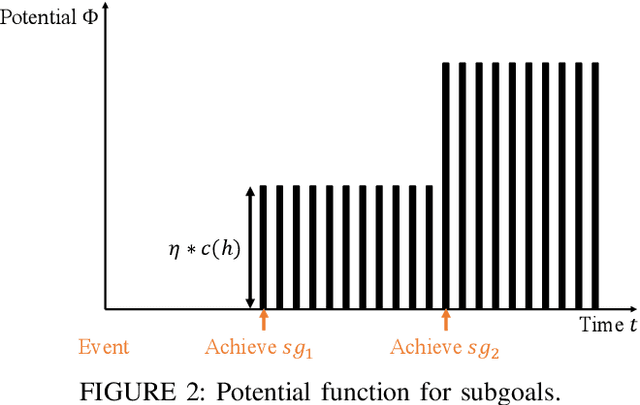

Reinforcement learning, which acquires a policy maximizing long-term rewards, has been actively studied. Unfortunately, this learning type is too slow and difficult to use in practical situations because the state-action space becomes huge in real environments. Many studies have incorporated human knowledge into reinforcement Learning. Though human knowledge on trajectories is often used, a human could be asked to control an AI agent, which can be difficult. Knowledge on subgoals may lessen this requirement because humans need only to consider a few representative states on an optimal trajectory in their minds. The essential factor for learning efficiency is rewards. Potential-based reward shaping is a basic method for enriching rewards. However, it is often difficult to incorporate subgoals for accelerating learning over potential-based reward shaping. This is because the appropriate potentials are not intuitive for humans. We extend potential-based reward shaping and propose a subgoal-based reward shaping. The method makes it easier for human trainers to share their knowledge of subgoals. To evaluate our method, we obtained a subgoal series from participants and conducted experiments in three domains, four-rooms(discrete states and discrete actions), pinball(continuous and discrete), and picking(both continuous). We compared our method with a baseline reinforcement learning algorithm and other subgoal-based methods, including random subgoal and naive subgoal-based reward shaping. As a result, we found out that our reward shaping outperformed all other methods in learning efficiency.
Reward Shaping with Subgoals for Social Navigation
Apr 13, 2021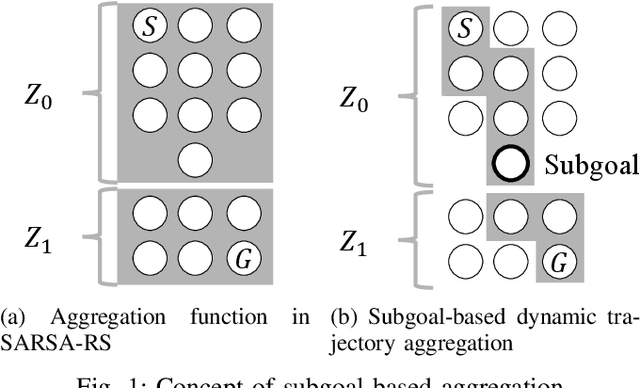
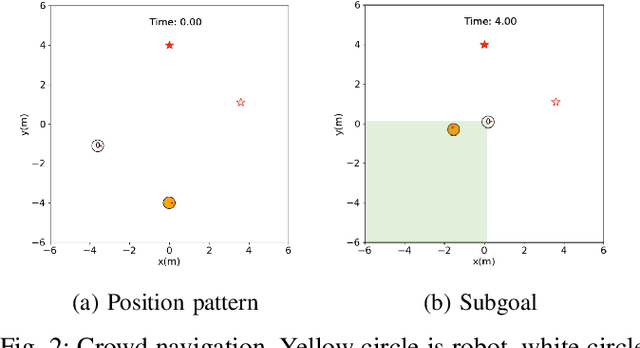
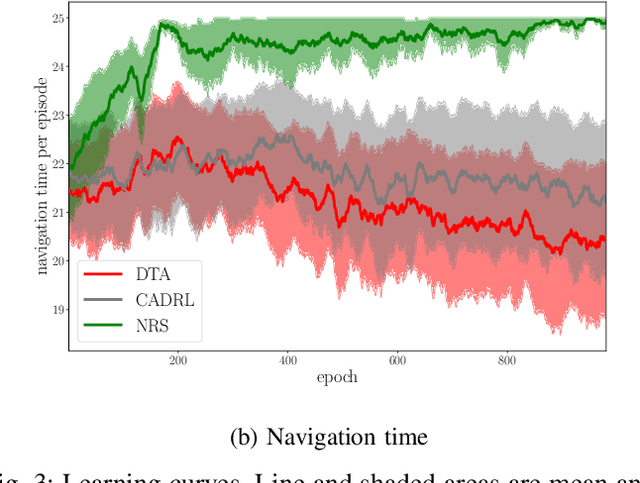
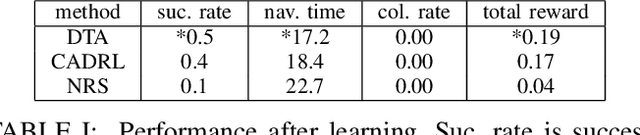
Social navigation has been gaining attentions with the growth in machine intelligence. Since reinforcement learning can select an action in the prediction phase at a low computational cost, it has been formulated in a social navigation tasks. However, reinforcement learning takes an enormous number of iterations until acquiring a behavior policy in the learning phase. This negatively affects the learning of robot behaviors in the real world. In particular, social navigation includes humans who are unpredictable moving obstacles in an environment. We proposed a reward shaping method with subgoals to accelerate learning. The main part is an aggregation method that use subgoals to shape a reinforcement learning algorithm. We performed a learning experiment with a social navigation task in which a robot avoided collisions and then reached its goal. The experimental results show that our method improved the learning efficiency from a base algorithm in the task.
Reward Shaping with Dynamic Trajectory Aggregation
Apr 13, 2021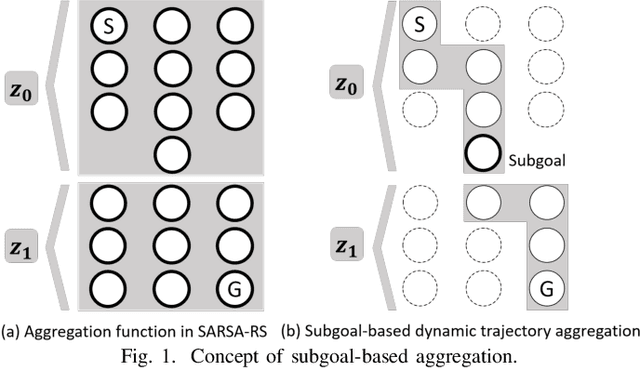
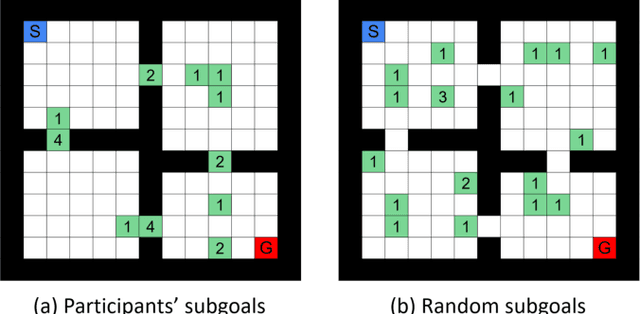
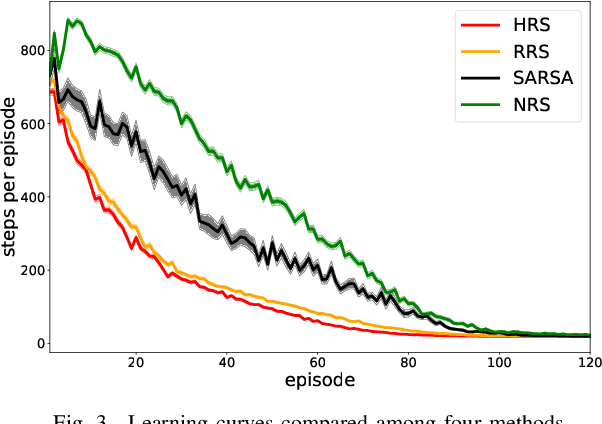
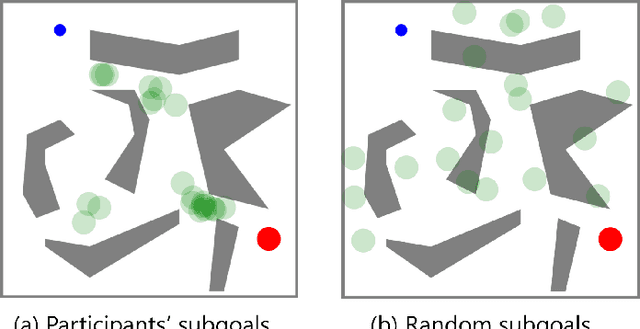
Reinforcement learning, which acquires a policy maximizing long-term rewards, has been actively studied. Unfortunately, this learning type is too slow and difficult to use in practical situations because the state-action space becomes huge in real environments. The essential factor for learning efficiency is rewards. Potential-based reward shaping is a basic method for enriching rewards. This method is required to define a specific real-value function called a potential function for every domain. It is often difficult to represent the potential function directly. SARSA-RS learns the potential function and acquires it. However, SARSA-RS can only be applied to the simple environment. The bottleneck of this method is the aggregation of states to make abstract states since it is almost impossible for designers to build an aggregation function for all states. We propose a trajectory aggregation that uses subgoal series. This method dynamically aggregates states in an episode during trial and error with only the subgoal series and subgoal identification function. It makes designer effort minimal and the application to environments with high-dimensional observations possible. We obtained subgoal series from participants for experiments. We conducted the experiments in three domains, four-rooms(discrete states and discrete actions), pinball(continuous and discrete), and picking(both continuous). We compared our method with a baseline reinforcement learning algorithm and other subgoal-based methods, including random subgoal and naive subgoal-based reward shaping. As a result, our reward shaping outperformed all other methods in learning efficiency.