 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping with Subgoals for Social Navigation
Paper and Code
Apr 13, 2021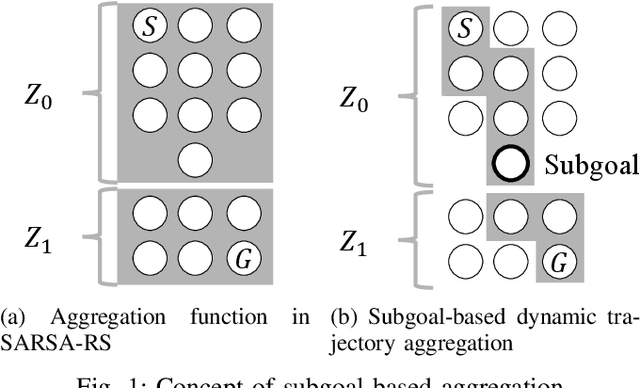
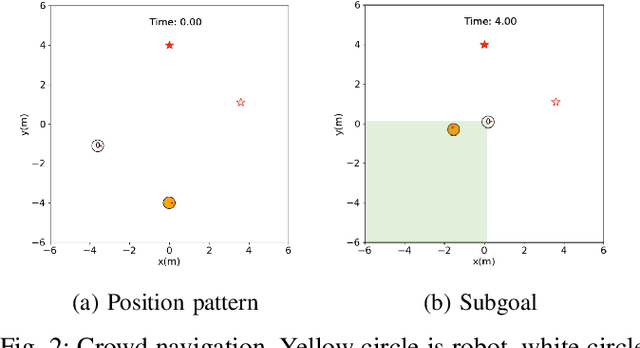
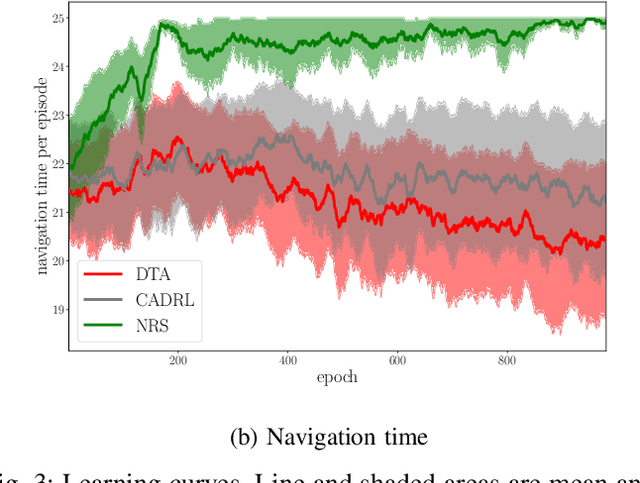
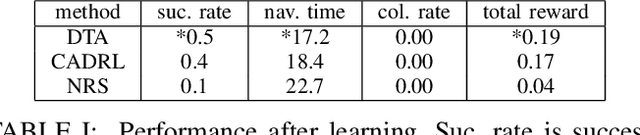
Social navigation has been gaining attentions with the growth in machine intelligence. Since reinforcement learning can select an action in the prediction phase at a low computational cost, it has been formulated in a social navigation tasks. However, reinforcement learning takes an enormous number of iterations until acquiring a behavior policy in the learning phase. This negatively affects the learning of robot behaviors in the real world. In particular, social navigation includes humans who are unpredictable moving obstacles in an environment. We proposed a reward shaping method with subgoals to accelerate learning. The main part is an aggregation method that use subgoals to shape a reinforcement learning algorithm. We performed a learning experiment with a social navigation task in which a robot avoided collisions and then reached its goal. The experimental results show that our method improved the learning efficiency from a base algorithm in the task.