 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping with Dynamic Trajectory Aggregation
Paper and Code
Apr 13, 2021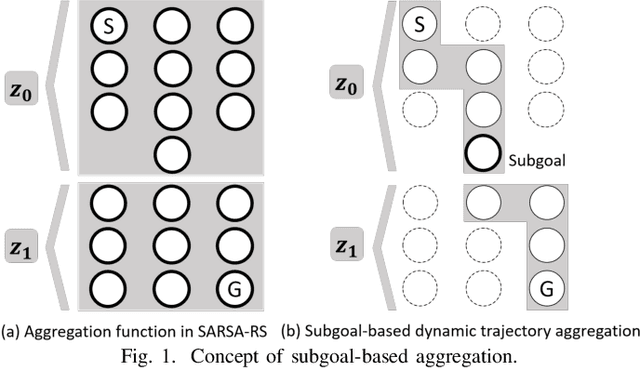
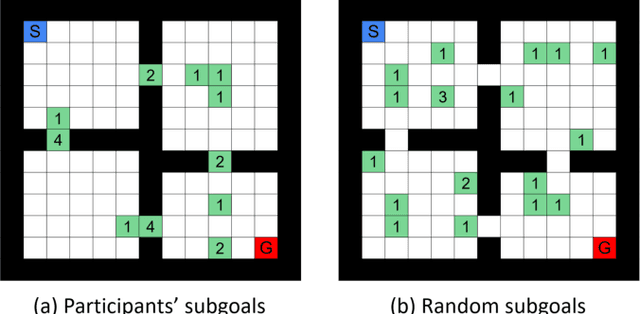
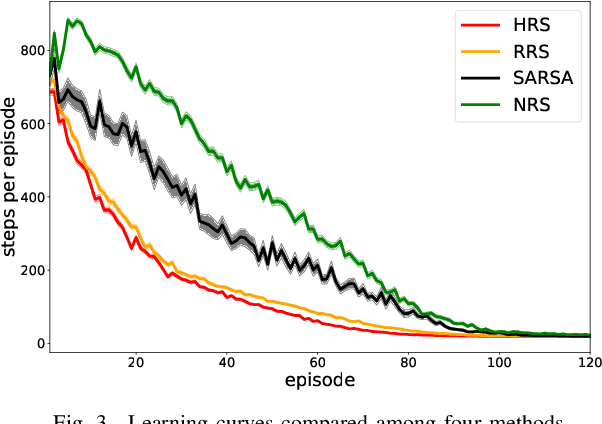
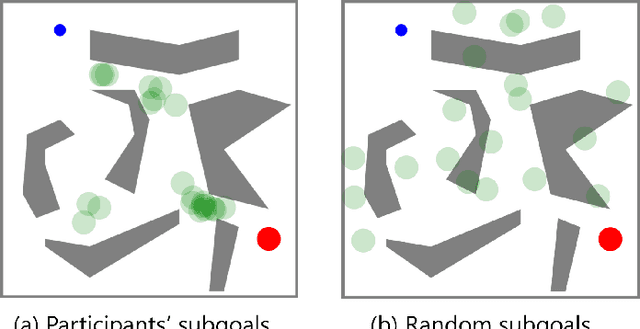
Reinforcement learning, which acquires a policy maximizing long-term rewards, has been actively studied. Unfortunately, this learning type is too slow and difficult to use in practical situations because the state-action space becomes huge in real environments. The essential factor for learning efficiency is rewards. Potential-based reward shaping is a basic method for enriching rewards. This method is required to define a specific real-value function called a potential function for every domain. It is often difficult to represent the potential function directly. SARSA-RS learns the potential function and acquires it. However, SARSA-RS can only be applied to the simple environment. The bottleneck of this method is the aggregation of states to make abstract states since it is almost impossible for designers to build an aggregation function for all states. We propose a trajectory aggregation that uses subgoal series. This method dynamically aggregates states in an episode during trial and error with only the subgoal series and subgoal identification function. It makes designer effort minimal and the application to environments with high-dimensional observations possible. We obtained subgoal series from participants for experiments. We conducted the experiments in three domains, four-rooms(discrete states and discrete actions), pinball(continuous and discrete), and picking(both continuous). We compared our method with a baseline reinforcement learning algorithm and other subgoal-based methods, including random subgoal and naive subgoal-based reward shaping. As a result, our reward shaping outperformed all other methods in learning efficiency.