 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Implementation of a Model of Category-Theoretic Metaphor Comprehension
Apr 11, 2026In this study, we developed a computational implementation for a model of metaphor comprehension based on the theory of indeterminate natural transformation (TINT) proposed by Fuyama et al. We simplified the algorithms implementing the model to be closer to the original theory and verified it through data fitting and simulations. The outputs of the algorithms are evaluated with three measures: data-fitting with experimental data, the systematicity of the metaphor comprehension result, and the novelty of the comprehension (i.e. the correspondence of the associative structure of the source and target of the metaphor). The improved algorithm outperformed the existing ones in all the three measures.
Investigating the structure of emotions by analyzing similarity and association of emotion words
Feb 06, 2026In the field of natural language processing, some studies have attempted sentiment analysis on text by handling emotions as explanatory or response variables. One of the most popular emotion models used in this context is the wheel of emotion proposed by Plutchik. This model schematizes human emotions in a circular structure, and represents them in two or three dimensions. However, the validity of Plutchik's wheel of emotion has not been sufficiently examined. This study investigated the validity of the wheel by creating and analyzing a semantic networks of emotion words. Through our experiments, we collected data of similarity and association of ordered pairs of emotion words, and constructed networks using these data. We then analyzed the structure of the networks through community detection, and compared it with that of the wheel of emotion. The results showed that each network's structure was, for the most part, similar to that of the wheel of emotion, but locally different.
Neural Risk-sensitive Satisficing in Contextual Bandits
Jan 15, 2025



The contextual bandit problem, which is a type of reinforcement learning tasks, provides an effective framework for solving challenges in recommendation systems, such as satisfying real-time requirements, enabling personalization, addressing cold-start problems. However, contextual bandit algorithms face challenges since they need to handle large state-action spaces sequentially. These challenges include the high costs for learning and balancing exploration and exploitation, as well as large variations in performance that depend on the domain of application. To address these challenges, Tsuboya et~al. proposed the Regional Linear Risk-sensitive Satisficing (RegLinRS) algorithm. RegLinRS switches between exploration and exploitation based on how well the agent has achieved the target. However, the reward expectations in RegLinRS are linearly approximated based on features, which limits its applicability when the relationship between features and reward expectations is non-linear. To handle more complex environments, we proposed Neural Risk-sensitive Satisficing (NeuralRS), which incorporates neural networks into RegLinRS, and demonstrated its utility.
Reinforcement Learning with a Focus on Adjusting Policies to Reach Targets
Dec 23, 2024The objective of a reinforcement learning agent is to discover better actions through exploration. However, typical exploration techniques aim to maximize rewards, often incurring high costs in both exploration and learning processes. We propose a novel deep reinforcement learning method, which prioritizes achieving an aspiration level over maximizing expected return. This method flexibly adjusts the degree of exploration based on the proportion of target achievement. Through experiments on a motion control task and a navigation task, this method achieved returns equal to or greater than other standard methods. The results of the analysis showed two things: our method flexibly adjusts the exploration scope, and it has the potential to enable the agent to adapt to non-stationary environments. These findings indicated that this method may have effectiveness in improving exploration efficiency in practical applications of reinforcement learning.
Contextual Exploration Using a Linear Approximation Method Based on Satisficing
Dec 13, 2021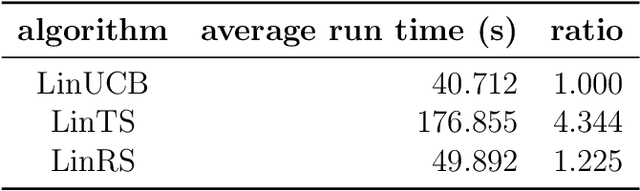
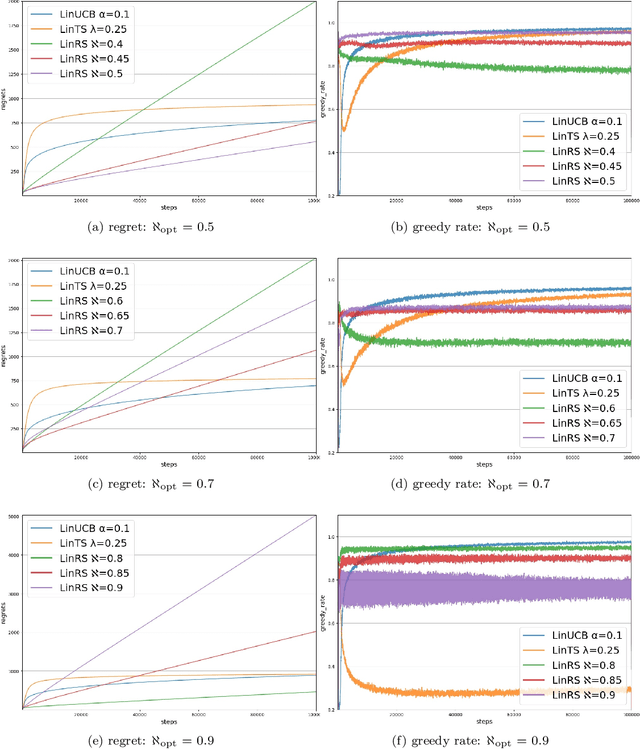

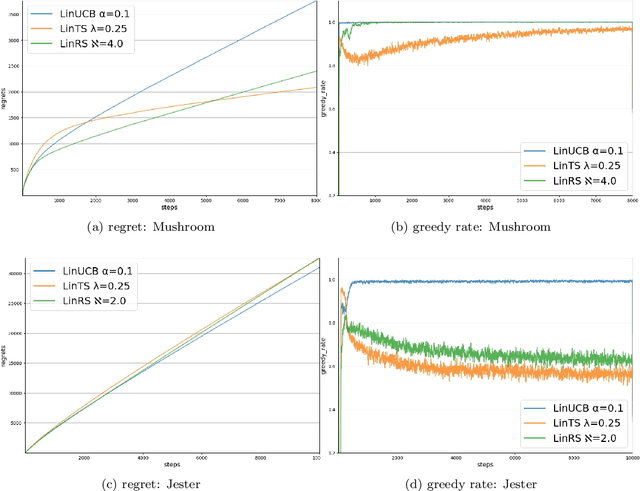
Deep reinforcement learning has enabled human-level or even super-human performance in various types of games. However, the amount of exploration required for learning is often quite large. Deep reinforcement learning also has super-human performance in that no human being would be able to achieve such amounts of exploration. To address this problem, we focus on the \textit{satisficing} policy, which is a qualitatively different approach from that of existing optimization algorithms. Thus, we propose Linear RS (LinRS), which is a type of satisficing algorithm and a linear extension of risk-sensitive satisficing (RS), for application to a wider range of tasks. The generalization of RS provides an algorithm to reduce the volume of exploratory actions by adopting a different approach from existing optimization algorithms. LinRS utilizes linear regression and multiclass classification to linearly approximate both the action value and proportion of action selections required in the RS calculation. The results of our experiments indicate that LinRS reduced the number of explorations and run time compared to those of existing algorithms in contextual bandit problems. These results suggest that a further generalization of satisficing algorithms may be useful for complex environments, including those that are to be handled with deep reinforcement learning.
Guaranteed satisficing and finite regret: Analysis of a cognitive satisficing value function
Dec 14, 2018


As reinforcement learning algorithms are being applied to increasingly complicated and realistic tasks, it is becoming increasingly difficult to solve such problems within a practical time frame. Hence, we focus on a \textit{satisficing} strategy that looks for an action whose value is above the aspiration level (analogous to the break-even point), rather than the optimal action. In this paper, we introduce a simple mathematical model called risk-sensitive satisficing ($RS$) that implements a satisficing strategy by integrating risk-averse and risk-prone attitudes under the greedy policy. We apply the proposed model to the $K$-armed bandit problems, which constitute the most basic class of reinforcement learning tasks, and prove two propositions. The first is that $RS$ is guaranteed to find an action whose value is above the aspiration level. The second is that the regret (expected loss) of $RS$ is upper bounded by a finite value, given that the aspiration level is set to an "optimal level" so that satisficing implies optimizing. We confirm the results through numerical simulations and compare the performance of $RS$ with that of other representative algorithms for the $K$-armed bandit problems.
Bayesian Inference of Self-intention Attributed by Observer
Oct 12, 2018
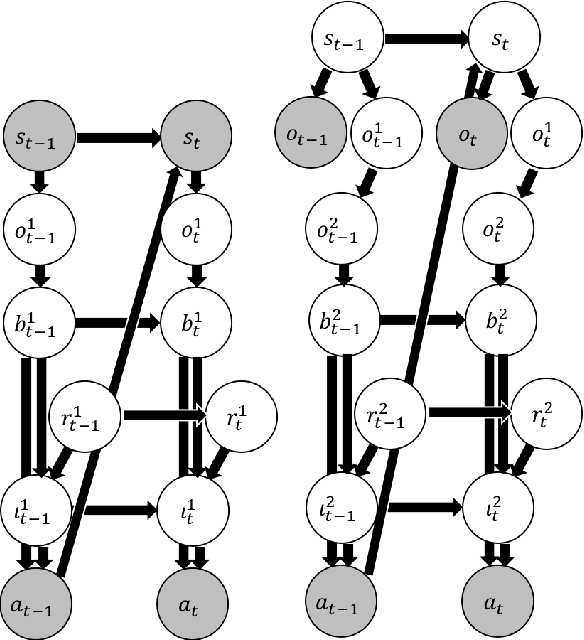
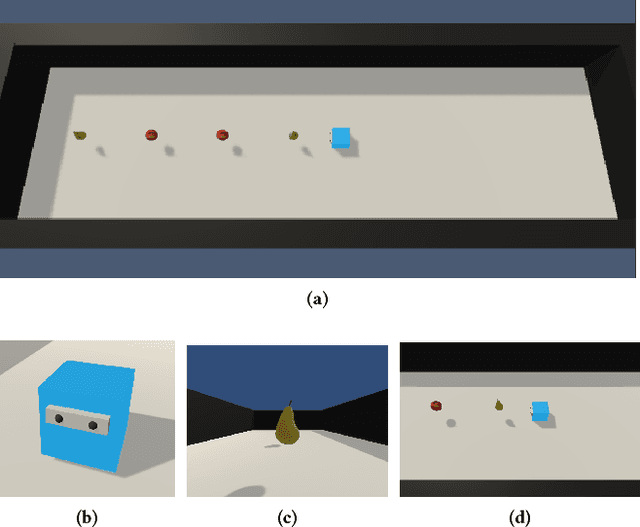
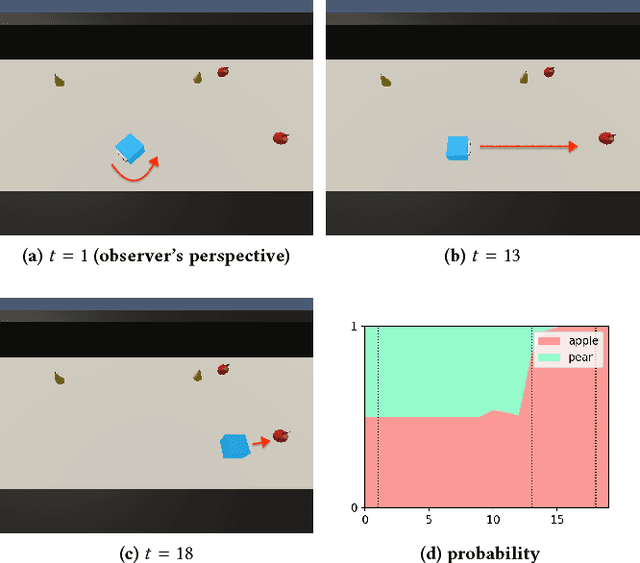
Most of agents that learn policy for tasks with reinforcement learning (RL) lack the ability to communicate with people, which makes human-agent collaboration challenging. We believe that, in order for RL agents to comprehend utterances from human colleagues, RL agents must infer the mental states that people attribute to them because people sometimes infer an interlocutor's mental states and communicate on the basis of this mental inference. This paper proposes PublicSelf model, which is a model of a person who infers how the person's own behavior appears to their colleagues. We implemented the PublicSelf model for an RL agent in a simulated environment and examined the inference of the model by comparing it with people's judgment. The results showed that the agent's intention that people attributed to the agent's movement was correctly inferred by the model in scenes where people could find certain intentionality from the agent's behavior.