 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Exploration Using a Linear Approximation Method Based on Satisficing
Paper and Code
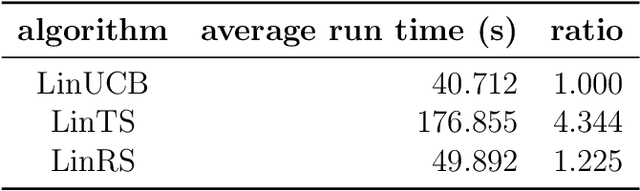
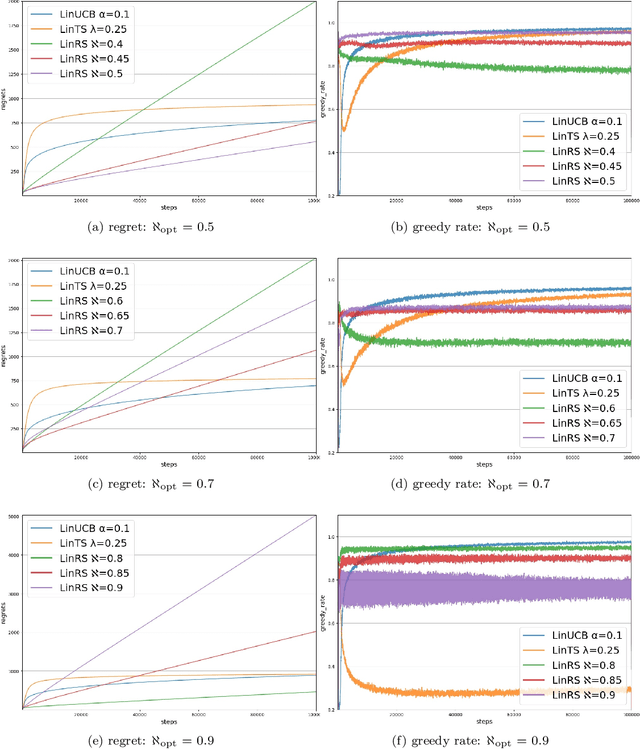

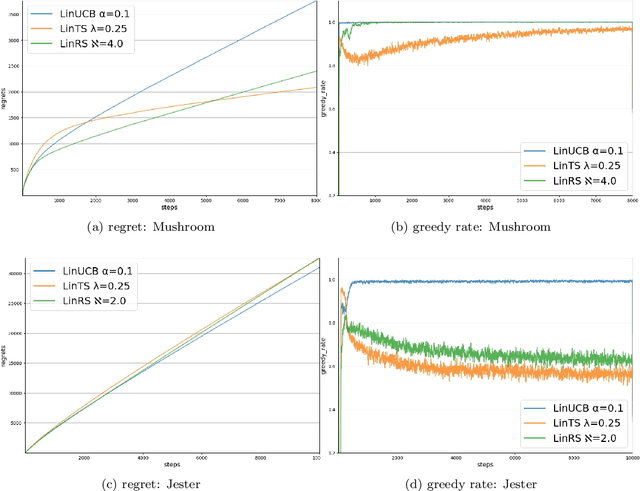
Deep reinforcement learning has enabled human-level or even super-human performance in various types of games. However, the amount of exploration required for learning is often quite large. Deep reinforcement learning also has super-human performance in that no human being would be able to achieve such amounts of exploration. To address this problem, we focus on the \textit{satisficing} policy, which is a qualitatively different approach from that of existing optimization algorithms. Thus, we propose Linear RS (LinRS), which is a type of satisficing algorithm and a linear extension of risk-sensitive satisficing (RS), for application to a wider range of tasks. The generalization of RS provides an algorithm to reduce the volume of exploratory actions by adopting a different approach from existing optimization algorithms. LinRS utilizes linear regression and multiclass classification to linearly approximate both the action value and proportion of action selections required in the RS calculation. The results of our experiments indicate that LinRS reduced the number of explorations and run time compared to those of existing algorithms in contextual bandit problems. These results suggest that a further generalization of satisficing algorithms may be useful for complex environments, including those that are to be handled with deep reinforcement learning.