 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Risk-sensitive Satisficing in Contextual Bandits
Jan 15, 2025



The contextual bandit problem, which is a type of reinforcement learning tasks, provides an effective framework for solving challenges in recommendation systems, such as satisfying real-time requirements, enabling personalization, addressing cold-start problems. However, contextual bandit algorithms face challenges since they need to handle large state-action spaces sequentially. These challenges include the high costs for learning and balancing exploration and exploitation, as well as large variations in performance that depend on the domain of application. To address these challenges, Tsuboya et~al. proposed the Regional Linear Risk-sensitive Satisficing (RegLinRS) algorithm. RegLinRS switches between exploration and exploitation based on how well the agent has achieved the target. However, the reward expectations in RegLinRS are linearly approximated based on features, which limits its applicability when the relationship between features and reward expectations is non-linear. To handle more complex environments, we proposed Neural Risk-sensitive Satisficing (NeuralRS), which incorporates neural networks into RegLinRS, and demonstrated its utility.
Reinforcement Learning with a Focus on Adjusting Policies to Reach Targets
Dec 23, 2024The objective of a reinforcement learning agent is to discover better actions through exploration. However, typical exploration techniques aim to maximize rewards, often incurring high costs in both exploration and learning processes. We propose a novel deep reinforcement learning method, which prioritizes achieving an aspiration level over maximizing expected return. This method flexibly adjusts the degree of exploration based on the proportion of target achievement. Through experiments on a motion control task and a navigation task, this method achieved returns equal to or greater than other standard methods. The results of the analysis showed two things: our method flexibly adjusts the exploration scope, and it has the potential to enable the agent to adapt to non-stationary environments. These findings indicated that this method may have effectiveness in improving exploration efficiency in practical applications of reinforcement learning.
Contextual Exploration Using a Linear Approximation Method Based on Satisficing
Dec 13, 2021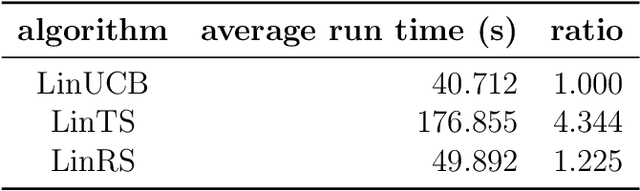
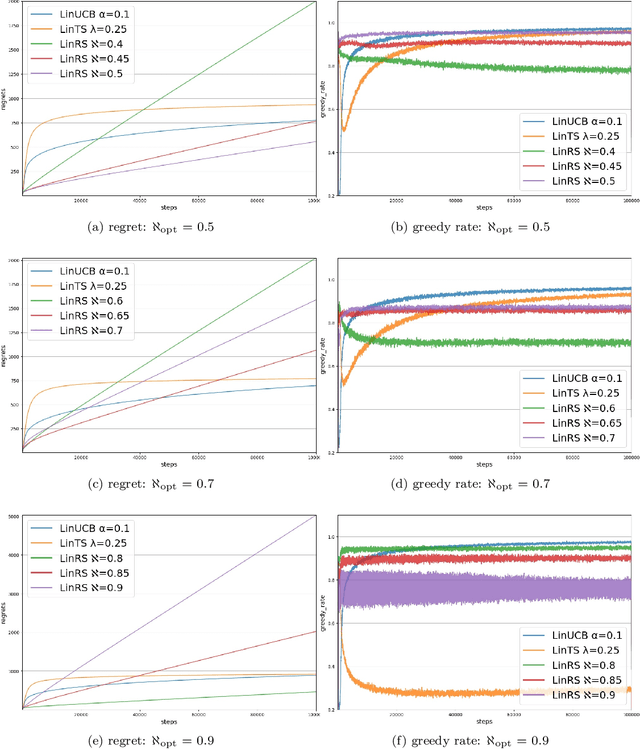

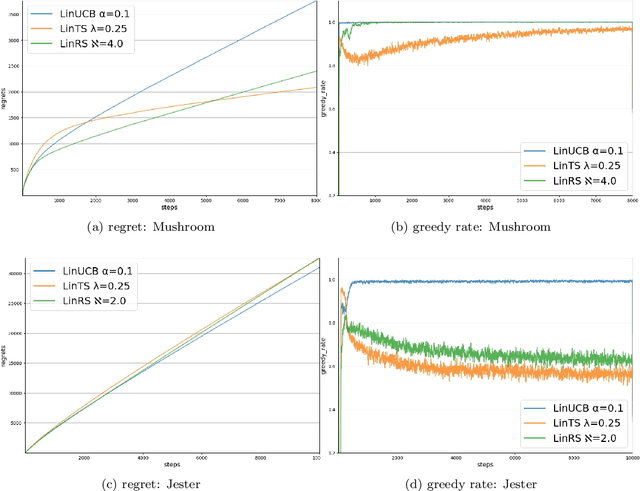
Deep reinforcement learning has enabled human-level or even super-human performance in various types of games. However, the amount of exploration required for learning is often quite large. Deep reinforcement learning also has super-human performance in that no human being would be able to achieve such amounts of exploration. To address this problem, we focus on the \textit{satisficing} policy, which is a qualitatively different approach from that of existing optimization algorithms. Thus, we propose Linear RS (LinRS), which is a type of satisficing algorithm and a linear extension of risk-sensitive satisficing (RS), for application to a wider range of tasks. The generalization of RS provides an algorithm to reduce the volume of exploratory actions by adopting a different approach from existing optimization algorithms. LinRS utilizes linear regression and multiclass classification to linearly approximate both the action value and proportion of action selections required in the RS calculation. The results of our experiments indicate that LinRS reduced the number of explorations and run time compared to those of existing algorithms in contextual bandit problems. These results suggest that a further generalization of satisficing algorithms may be useful for complex environments, including those that are to be handled with deep reinforcement learning.