 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Active Learning for Bayesian Decision-Making
Jun 08, 2021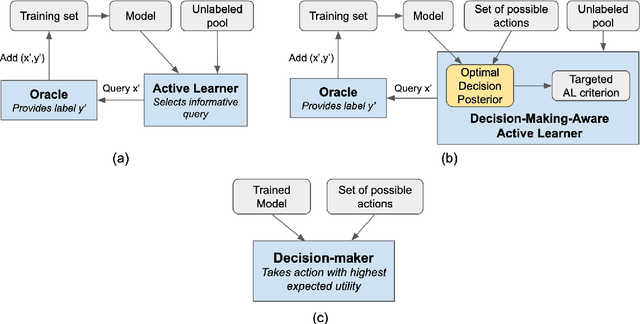
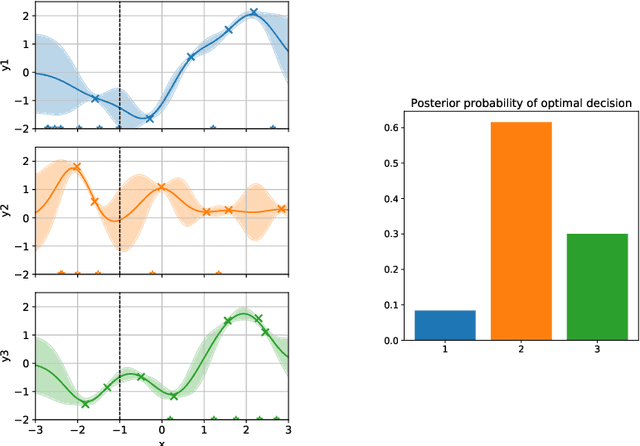
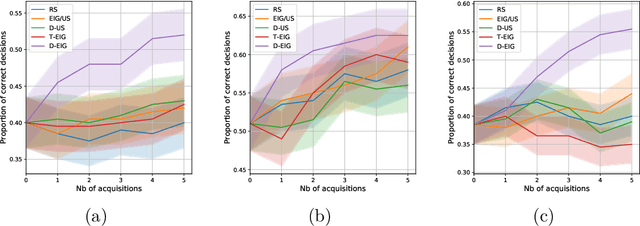
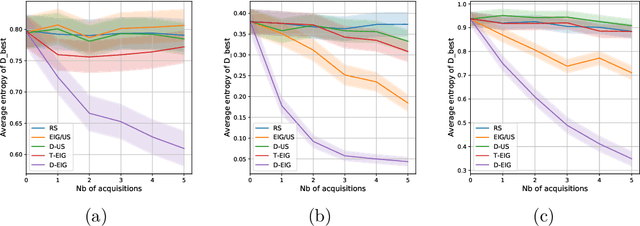
Active learning is usually applied to acquire labels of informative data points in supervised learning, to maximize accuracy in a sample-efficient way. However, maximizing the accuracy is not the end goal when the results are used for decision-making, for example in personalized medicine or economics. We argue that when acquiring samples sequentially, separating learning and decision-making is sub-optimal, and we introduce a novel active learning strategy which takes the down-the-line decision problem into account. Specifically, we introduce a novel active learning criterion which maximizes the expected information gain on the posterior distribution of the optimal decision. We compare our decision-making-aware active learning strategy to existing alternatives on both simulated and real data, and show improved performance in decision-making accuracy.
Active Learning for Decision-Making from Imbalanced Observational Data
Apr 10, 2019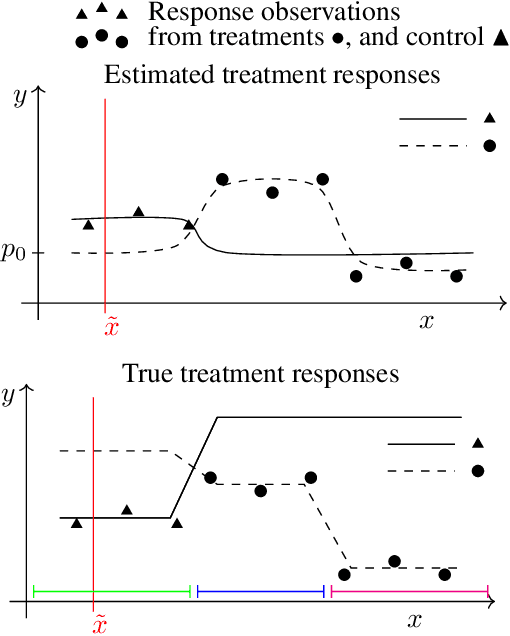
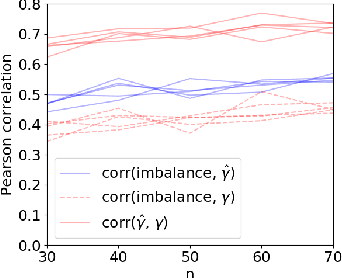
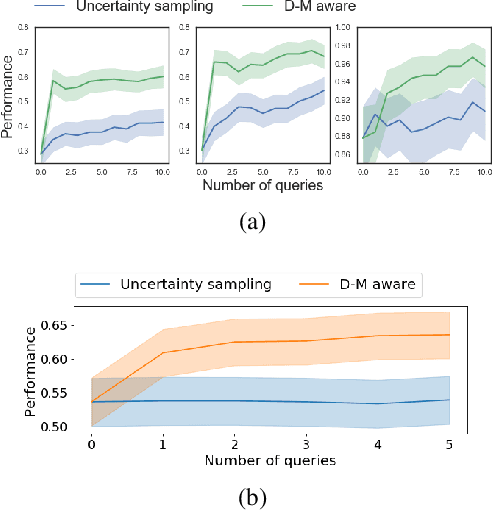
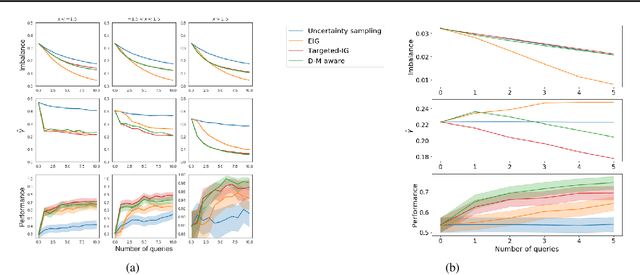
Machine learning can help personalized decision support by learning models to predict individual treatment effects (ITE). This work studies the reliability of prediction-based decision-making in a task of deciding which action $a$ to take for a target unit after observing its covariates $\tilde{x}$ and predicted outcomes $\hat{p}(\tilde{y} \mid \tilde{x}, a)$. An example case is personalized medicine and the decision of which treatment to give to a patient. A common problem when learning these models from observational data is imbalance, that is, difference in treated/control covariate distributions, which is known to increase the upper bound of the expected ITE estimation error. We propose to assess the decision-making reliability by estimating the ITE model's Type S error rate, which is the probability of the model inferring the sign of the treatment effect wrong. Furthermore, we use the estimated reliability as a criterion for active learning, in order to collect new (possibly expensive) observations, instead of making a forced choice based on unreliable predictions. We demonstrate the effectiveness of this decision-making aware active learning in two decision-making tasks: in simulated data with binary outcomes and in a medical dataset with synthetic and continuous treatment outcomes.
Improving drug sensitivity predictions in precision medicine through active expert knowledge elicitation
May 09, 2017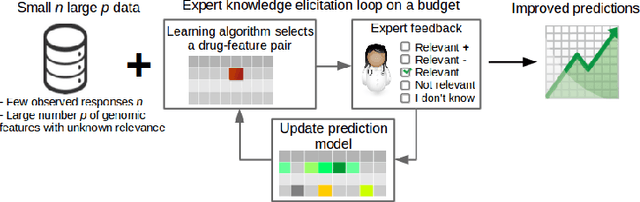

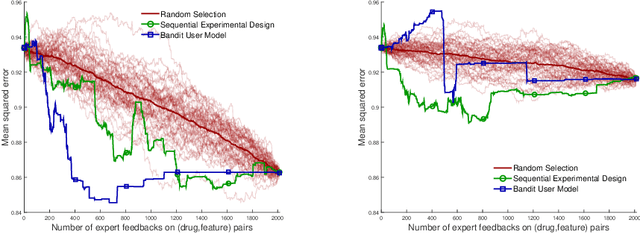

Predicting the efficacy of a drug for a given individual, using high-dimensional genomic measurements, is at the core of precision medicine. However, identifying features on which to base the predictions remains a challenge, especially when the sample size is small. Incorporating expert knowledge offers a promising alternative to improve a prediction model, but collecting such knowledge is laborious to the expert if the number of candidate features is very large. We introduce a probabilistic model that can incorporate expert feedback about the impact of genomic measurements on the sensitivity of a cancer cell for a given drug. We also present two methods to intelligently collect this feedback from the expert, using experimental design and multi-armed bandit models. In a multiple myeloma blood cancer data set (n=51), expert knowledge decreased the prediction error by 8%. Furthermore, the intelligent approaches can be used to reduce the workload of feedback collection to less than 30% on average compared to a naive approach.
Interactive Elicitation of Knowledge on Feature Relevance Improves Predictions in Small Data Sets
Jan 16, 2017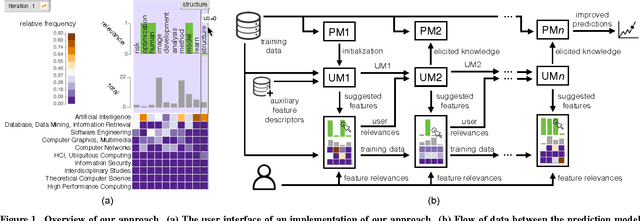

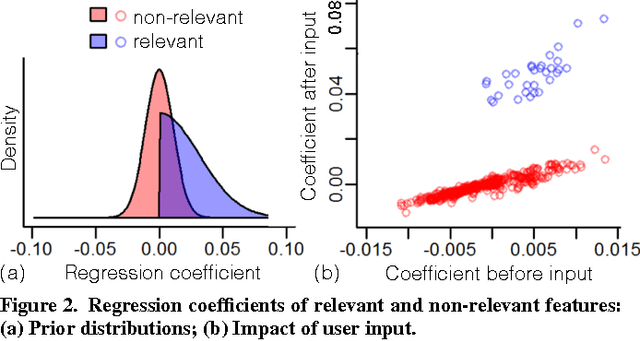
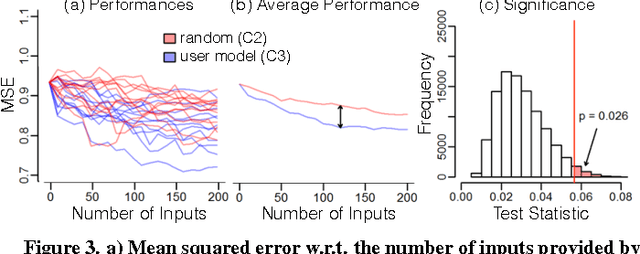
Providing accurate predictions is challenging for machine learning algorithms when the number of features is larger than the number of samples in the data. Prior knowledge can improve machine learning models by indicating relevant variables and parameter values. Yet, this prior knowledge is often tacit and only available from domain experts. We present a novel approach that uses interactive visualization to elicit the tacit prior knowledge and uses it to improve the accuracy of prediction models. The main component of our approach is a user model that models the domain expert's knowledge of the relevance of different features for a prediction task. In particular, based on the expert's earlier input, the user model guides the selection of the features on which to elicit user's knowledge next. The results of a controlled user study show that the user model significantly improves prior knowledge elicitation and prediction accuracy, when predicting the relative citation counts of scientific documents in a specific domain.