 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Utility of Grounding Documents with Reference-Free LLM-based Metrics
Jan 30, 2026Retrieval Augmented Generation (RAG)'s success depends on the utility the LLM derives from the content used for grounding. Quantifying content utility does not have a definitive specification and existing metrics ignore model-specific capabilities and/or rely on costly annotations. In this paper, we propose Grounding Generation Utility (GroGU), a model-specific and reference-free metric that defines utility as a function of the downstream LLM's generation confidence based on entropy. Despite having no annotation requirements, GroGU is largely faithful in distinguishing ground-truth documents while capturing nuances ignored by LLM-agnostic metrics. We apply GroGU to train a query-rewriter for RAG by identifying high-utility preference data for Direct Preference Optimization. Experiments show improvements by up to 18.2 points in Mean Reciprocal Rank and up to 9.4 points in answer accuracy.
Active Learning for Decision-Making from Imbalanced Observational Data
Apr 10, 2019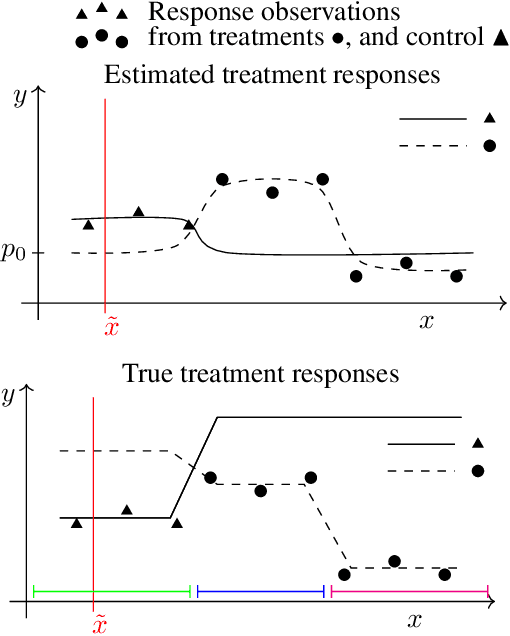
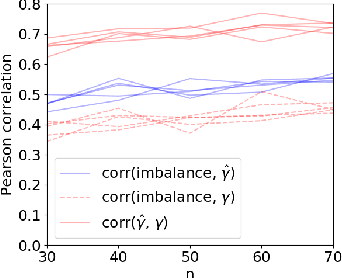
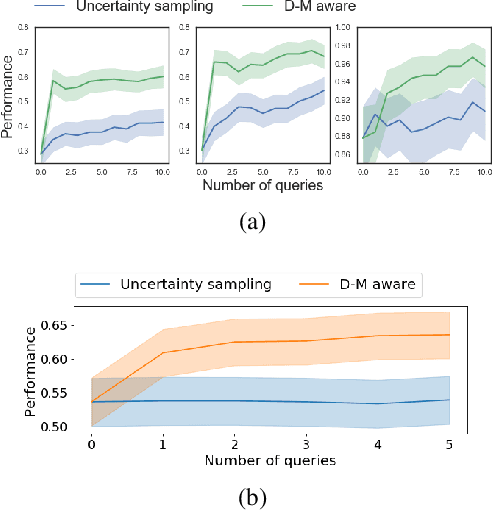
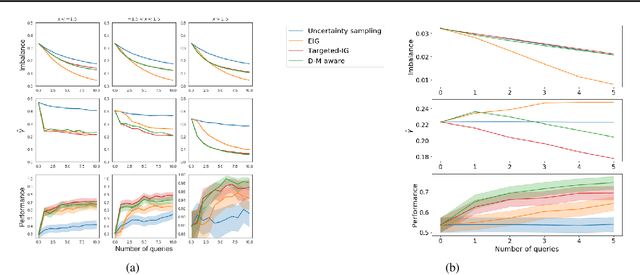
Machine learning can help personalized decision support by learning models to predict individual treatment effects (ITE). This work studies the reliability of prediction-based decision-making in a task of deciding which action $a$ to take for a target unit after observing its covariates $\tilde{x}$ and predicted outcomes $\hat{p}(\tilde{y} \mid \tilde{x}, a)$. An example case is personalized medicine and the decision of which treatment to give to a patient. A common problem when learning these models from observational data is imbalance, that is, difference in treated/control covariate distributions, which is known to increase the upper bound of the expected ITE estimation error. We propose to assess the decision-making reliability by estimating the ITE model's Type S error rate, which is the probability of the model inferring the sign of the treatment effect wrong. Furthermore, we use the estimated reliability as a criterion for active learning, in order to collect new (possibly expensive) observations, instead of making a forced choice based on unreliable predictions. We demonstrate the effectiveness of this decision-making aware active learning in two decision-making tasks: in simulated data with binary outcomes and in a medical dataset with synthetic and continuous treatment outcomes.
Auditing Pointwise Reliability Subsequent to Training
Jan 02, 2019


To use machine learning in high stakes applications (e.g. medicine), we need tools for building confidence in the system and evaluating whether it is reliable. Methods to improve model reliability are often applied at train time (e.g. using Bayesian inference to obtain uncertainty estimates). An alternative is to audit a fixed model subsequent to training. In this paper, we describe resampling uncertainty estimation (RUE), an algorithm to audit the pointwise reliability of predictions. Intuitively, RUE estimates the amount that a single prediction would change if the model had been fit on different training data drawn from the same distribution by using the gradient and Hessian of the model's loss on training data. Experimentally, we show that RUE more effectively detects inaccurate predictions than existing tools for auditing reliability subsequent to training. We also show that RUE can create predictive distributions that are competitive with state-of-the-art methods like Monte Carlo dropout, probabilistic backpropagation, and deep ensembles, but does not depend on specific algorithms at train-time like these methods do.
Learning Predictive Models That Transport
Dec 11, 2018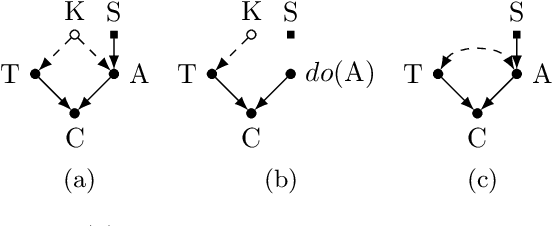
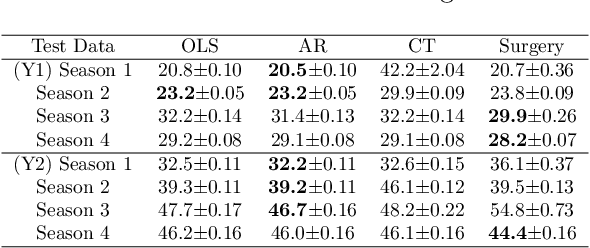
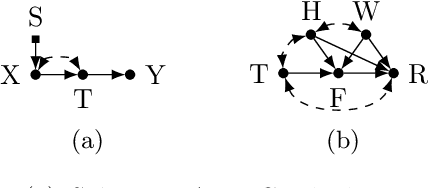
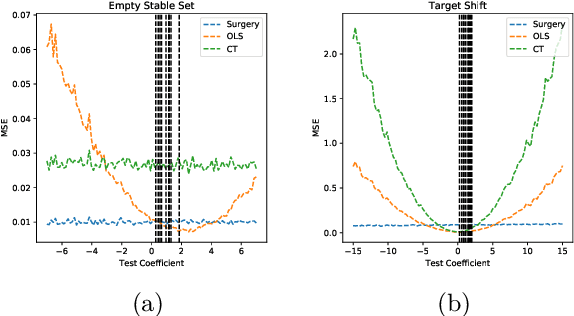
Classical supervised learning produces unreliable models when training and target distributions differ, with most existing solutions requiring samples from the target domain. We propose a proactive approach which learns a relationship in the training domain that will generalize to the target domain by incorporating prior knowledge of aspects of the data generating process that are expected to differ as expressed in a causal selection diagram. Specifically, we remove variables generated by unstable mechanisms from the joint factorization to yield the Graph Surgery Estimator---an interventional distribution that is invariant to the differences across domains. We prove that the surgery estimator finds stable relationships in strictly more scenarios than previous approaches which only consider conditional relationships, and demonstrate this in simulated experiments. We also evaluate on real world data for which the true causal diagram is unknown, performing competitively against entirely data-driven approaches.
Machine Learning for Health (ML4H) Workshop at NeurIPS 2018
Nov 24, 2018This volume represents the accepted submissions from the Machine Learning for Health (ML4H) workshop at the conference on Neural Information Processing Systems (NeurIPS) 2018, held on December 8, 2018 in Montreal, Canada.
Opportunities in Machine Learning for Healthcare
Jun 05, 2018Healthcare is a natural arena for the application of machine learning, especially as modern electronic health records (EHRs) provide increasingly large amounts of data to answer clinically meaningful questions. However, clinical data and practice present unique challenges that complicate the use of common methodologies. This article serves as a primer on addressing these challenges and highlights opportunities for members of the machine learning and data science communities to contribute to this growing domain.
Reliable Decision Support using Counterfactual Models
Feb 01, 2018

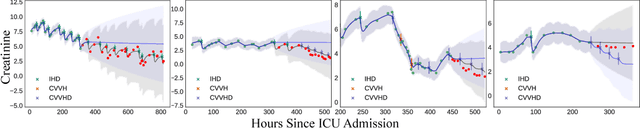
Decision-makers are faced with the challenge of estimating what is likely to happen when they take an action. For instance, if I choose not to treat this patient, are they likely to die? Practitioners commonly use supervised learning algorithms to fit predictive models that help decision-makers reason about likely future outcomes, but we show that this approach is unreliable, and sometimes even dangerous. The key issue is that supervised learning algorithms are highly sensitive to the policy used to choose actions in the training data, which causes the model to capture relationships that do not generalize. We propose using a different learning objective that predicts counterfactuals instead of predicting outcomes under an existing action policy as in supervised learning. To support decision-making in temporal settings, we introduce the Counterfactual Gaussian Process (CGP) to predict the counterfactual future progression of continuous-time trajectories under sequences of future actions. We demonstrate the benefits of the CGP on two important decision-support tasks: risk prediction and "what if?" reasoning for individualized treatment planning.
Disease Trajectory Maps
Jun 29, 2016

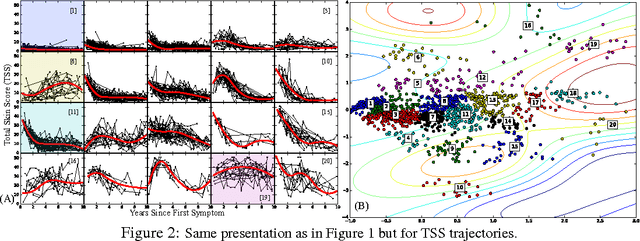

Medical researchers are coming to appreciate that many diseases are in fact complex, heterogeneous syndromes composed of subpopulations that express different variants of a related complication. Time series data extracted from individual electronic health records (EHR) offer an exciting new way to study subtle differences in the way these diseases progress over time. In this paper, we focus on answering two questions that can be asked using these databases of time series. First, we want to understand whether there are individuals with similar disease trajectories and whether there are a small number of degrees of freedom that account for differences in trajectories across the population. Second, we want to understand how important clinical outcomes are associated with disease trajectories. To answer these questions, we propose the Disease Trajectory Map (DTM), a novel probabilistic model that learns low-dimensional representations of sparse and irregularly sampled time series. We propose a stochastic variational inference algorithm for learning the DTM that allows the model to scale to large modern medical datasets. To demonstrate the DTM, we analyze data collected on patients with the complex autoimmune disease, scleroderma. We find that DTM learns meaningful representations of disease trajectories and that the representations are significantly associated with important clinical outcomes.
A Framework for Individualizing Predictions of Disease Trajectories by Exploiting Multi-Resolution Structure
Jan 21, 2016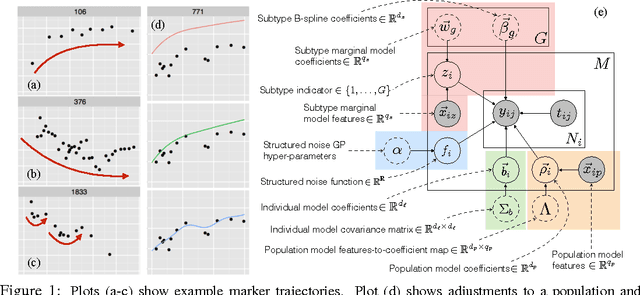


For many complex diseases, there is a wide variety of ways in which an individual can manifest the disease. The challenge of personalized medicine is to develop tools that can accurately predict the trajectory of an individual's disease, which can in turn enable clinicians to optimize treatments. We represent an individual's disease trajectory as a continuous-valued continuous-time function describing the severity of the disease over time. We propose a hierarchical latent variable model that individualizes predictions of disease trajectories. This model shares statistical strength across observations at different resolutions--the population, subpopulation and the individual level. We describe an algorithm for learning population and subpopulation parameters offline, and an online procedure for dynamically learning individual-specific parameters. Finally, we validate our model on the task of predicting the course of interstitial lung disease, a leading cause of death among patients with the autoimmune disease scleroderma. We compare our approach against state-of-the-art and demonstrate significant improvements in predictive accuracy.