 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Strategic Steering Improves Performance of Interactive Optimization
May 04, 2020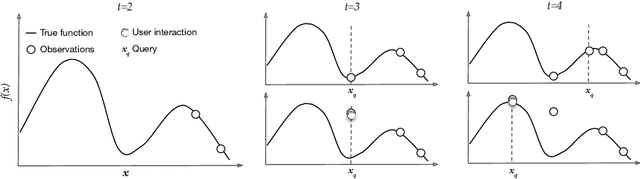
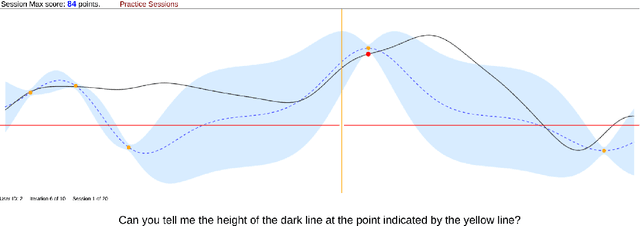
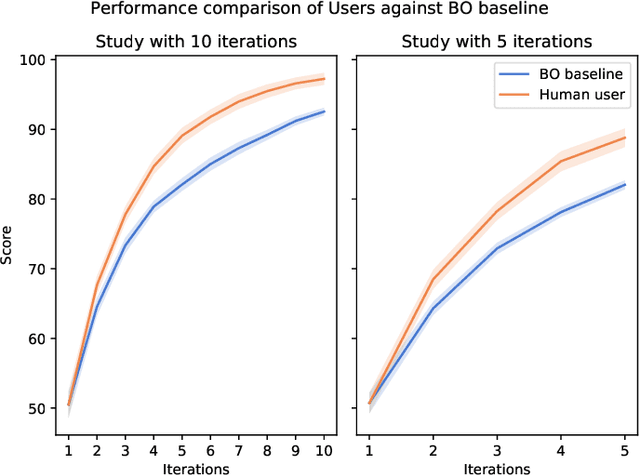
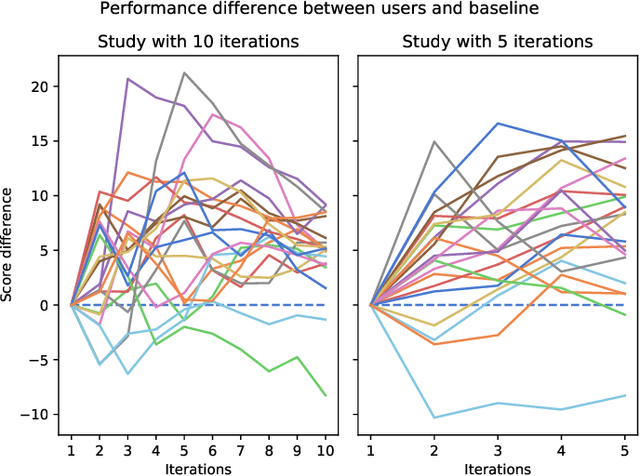
A central concern in an interactive intelligent system is optimization of its actions, to be maximally helpful to its human user. In recommender systems for instance, the action is to choose what to recommend, and the optimization task is to recommend items the user prefers. The optimization is done based on earlier user's feedback (e.g. "likes" and "dislikes"), and the algorithms assume the feedback to be faithful. That is, when the user clicks "like," they actually prefer the item. We argue that this fundamental assumption can be extensively violated by human users, who are not passive feedback sources. Instead, they are in control, actively steering the system towards their goal. To verify this hypothesis, that humans steer and are able to improve performance by steering, we designed a function optimization task where a human and an optimization algorithm collaborate to find the maximum of a 1-dimensional function. At each iteration, the optimization algorithm queries the user for the value of a hidden function $f$ at a point $x$, and the user, who sees the hidden function, provides an answer about $f(x)$. Our study on 21 participants shows that users who understand how the optimization works, strategically provide biased answers (answers not equal to $f(x)$), which results in the algorithm finding the optimum significantly faster. Our work highlights that next-generation intelligent systems will need user models capable of helping users who steer systems to pursue their goals.
Interactive AI with a Theory of Mind
Dec 01, 2019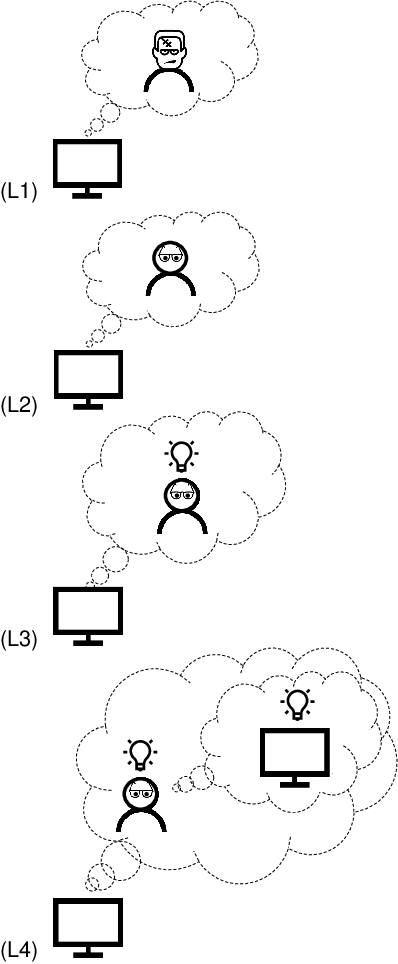
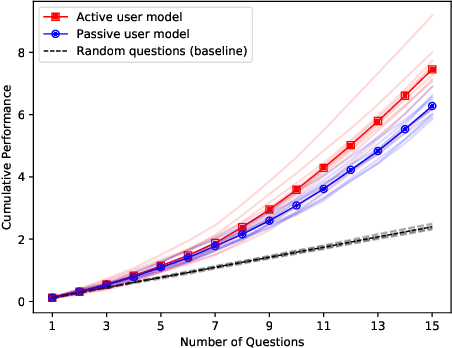
Understanding each other is the key to success in collaboration. For humans, attributing mental states to others, the theory of mind, provides the crucial advantage. We argue for formulating human--AI interaction as a multi-agent problem, endowing AI with a computational theory of mind to understand and anticipate the user. To differentiate the approach from previous work, we introduce a categorisation of user modelling approaches based on the level of agency learnt in the interaction. We describe our recent work in using nested multi-agent modelling to formulate user models for multi-armed bandit based interactive AI systems, including a proof-of-concept user study.
Modelling User's Theory of AI's Mind in Interactive Intelligent Systems
Sep 08, 2018
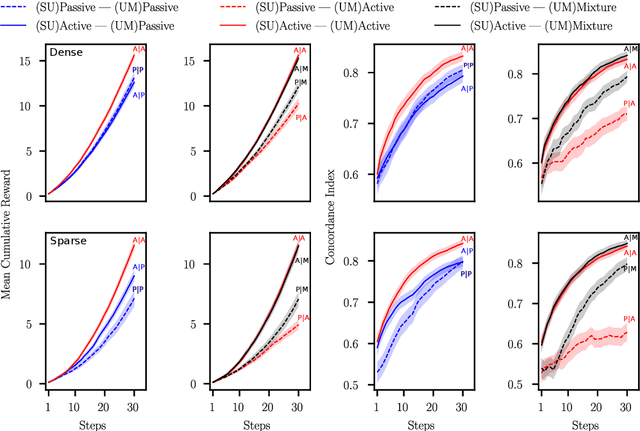
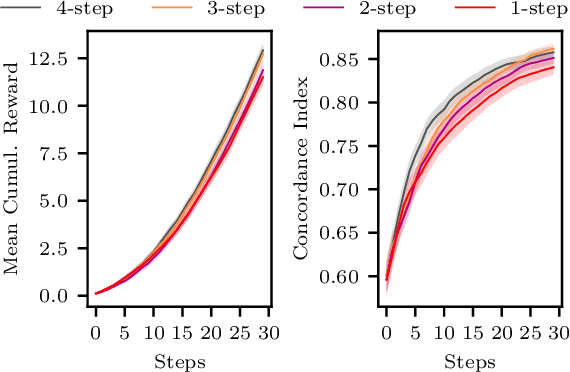
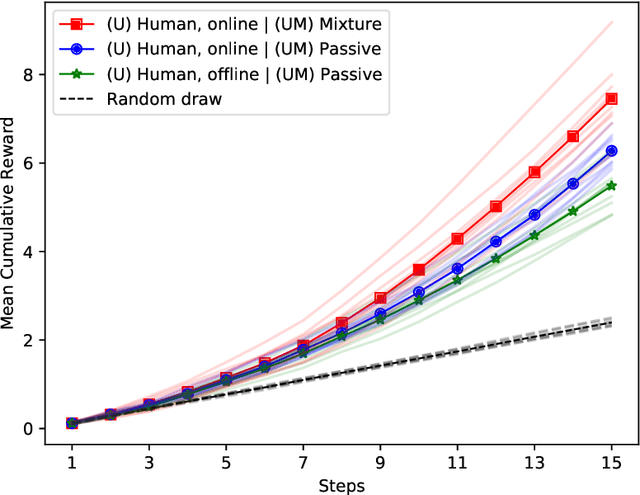
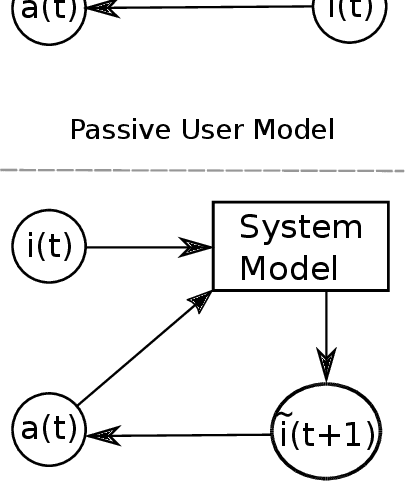
Many interactive intelligent systems, such as recommendation and information retrieval systems, treat users as a passive data source. Yet, users form mental models of systems and instead of passively providing feedback to the queries of the system, they will strategically plan their actions within the constraints of the mental model to steer the system and achieve their goals faster. We propose to explicitly account for the user's theory of the AI's mind in the user model: the intelligent system has a model of the user having a model of the intelligent system. We study a case where the system is a contextual bandit and the user model is a Markov decision process that plans based on a simpler model of the bandit. Inference in the model can be reduced to probabilistic inverse reinforcement learning, with the nested bandit model defining the transition dynamics, and is implemented using probabilistic programming. Our results show that improved performance is achieved if users can form accurate mental models that the system can capture, implying predictability of the interactive intelligent system is important not only for the user experience but also for the design of the system's statistical models.
User Modelling for Avoiding Overfitting in Interactive Knowledge Elicitation for Prediction
Mar 09, 2018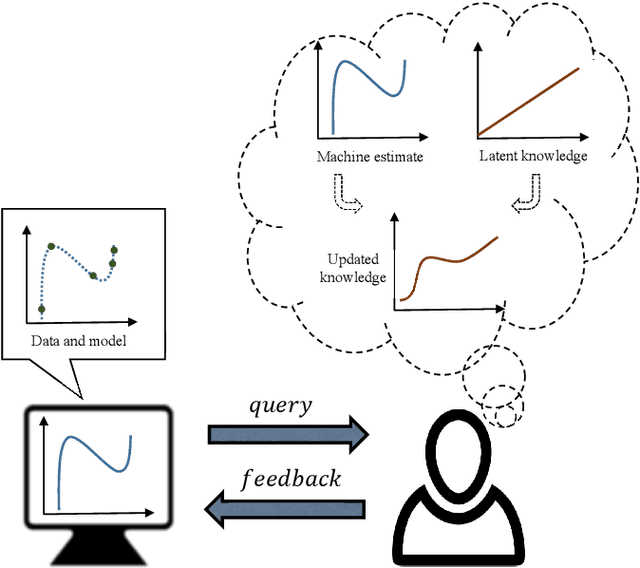

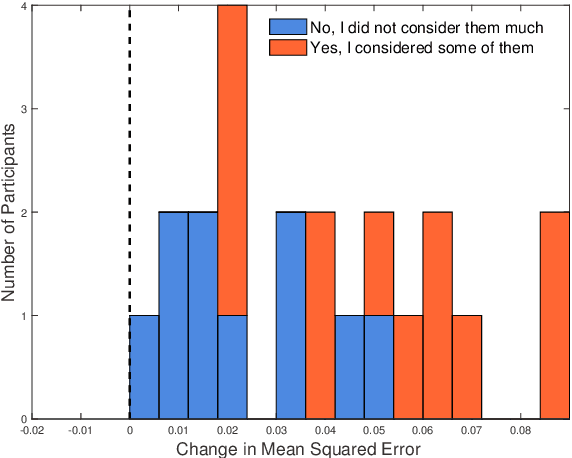
In human-in-the-loop machine learning, the user provides information beyond that in the training data. Many algorithms and user interfaces have been designed to optimize and facilitate this human--machine interaction; however, fewer studies have addressed the potential defects the designs can cause. Effective interaction often requires exposing the user to the training data or its statistics. The design of the system is then critical, as this can lead to double use of data and overfitting, if the user reinforces noisy patterns in the data. We propose a user modelling methodology, by assuming simple rational behaviour, to correct the problem. We show, in a user study with 48 participants, that the method improves predictive performance in a sparse linear regression sentiment analysis task, where graded user knowledge on feature relevance is elicited. We believe that the key idea of inferring user knowledge with probabilistic user models has general applicability in guarding against overfitting and improving interactive machine learning.
Knowledge Elicitation via Sequential Probabilistic Inference for High-Dimensional Prediction
Jul 13, 2017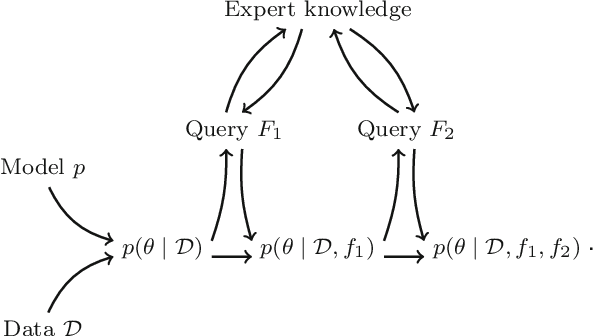

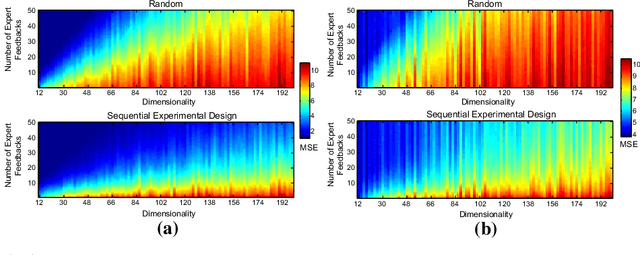

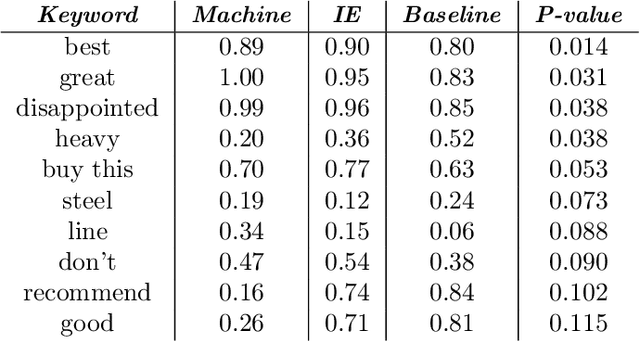
Prediction in a small-sized sample with a large number of covariates, the "small n, large p" problem, is challenging. This setting is encountered in multiple applications, such as precision medicine, where obtaining additional samples can be extremely costly or even impossible, and extensive research effort has recently been dedicated to finding principled solutions for accurate prediction. However, a valuable source of additional information, domain experts, has not yet been efficiently exploited. We formulate knowledge elicitation generally as a probabilistic inference process, where expert knowledge is sequentially queried to improve predictions. In the specific case of sparse linear regression, where we assume the expert has knowledge about the values of the regression coefficients or about the relevance of the features, we propose an algorithm and computational approximation for fast and efficient interaction, which sequentially identifies the most informative features on which to query expert knowledge. Evaluations of our method in experiments with simulated and real users show improved prediction accuracy already with a small effort from the expert.
Improving drug sensitivity predictions in precision medicine through active expert knowledge elicitation
May 09, 2017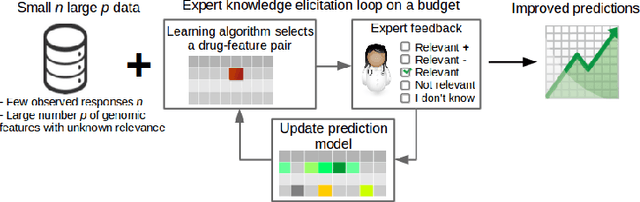

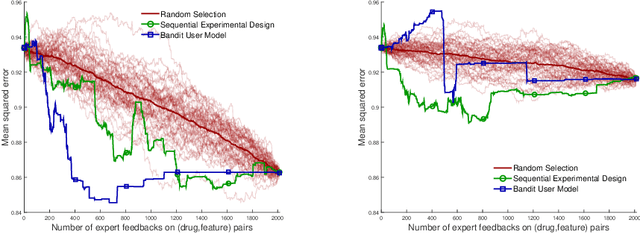

Predicting the efficacy of a drug for a given individual, using high-dimensional genomic measurements, is at the core of precision medicine. However, identifying features on which to base the predictions remains a challenge, especially when the sample size is small. Incorporating expert knowledge offers a promising alternative to improve a prediction model, but collecting such knowledge is laborious to the expert if the number of candidate features is very large. We introduce a probabilistic model that can incorporate expert feedback about the impact of genomic measurements on the sensitivity of a cancer cell for a given drug. We also present two methods to intelligently collect this feedback from the expert, using experimental design and multi-armed bandit models. In a multiple myeloma blood cancer data set (n=51), expert knowledge decreased the prediction error by 8%. Furthermore, the intelligent approaches can be used to reduce the workload of feedback collection to less than 30% on average compared to a naive approach.