 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Strategic Steering Improves Performance of Interactive Optimization
May 04, 2020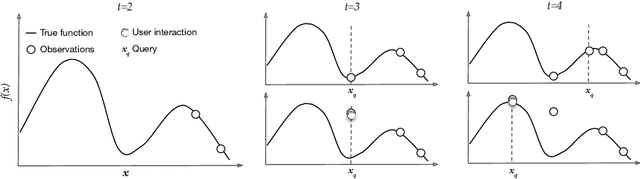
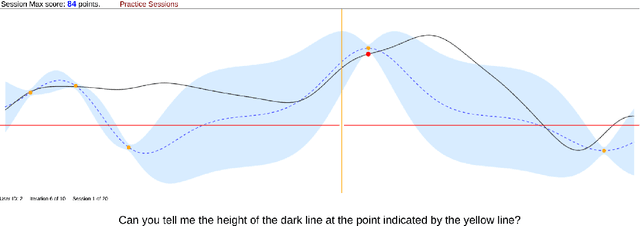
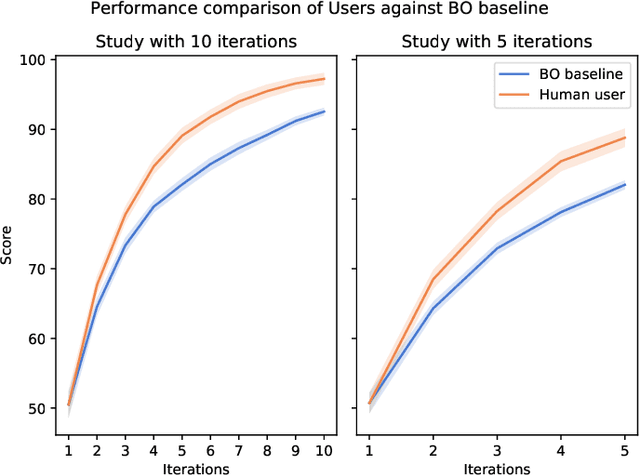
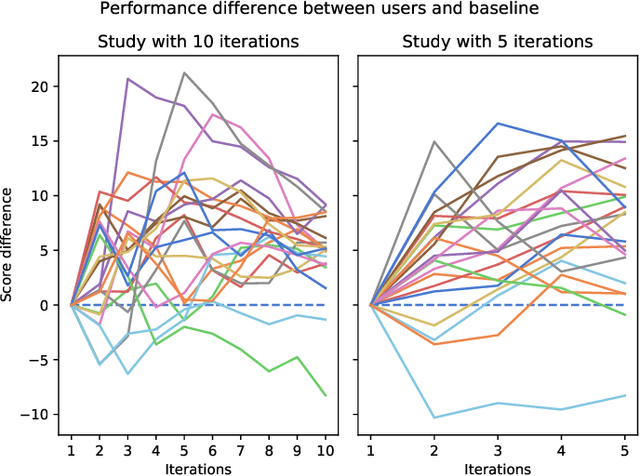
A central concern in an interactive intelligent system is optimization of its actions, to be maximally helpful to its human user. In recommender systems for instance, the action is to choose what to recommend, and the optimization task is to recommend items the user prefers. The optimization is done based on earlier user's feedback (e.g. "likes" and "dislikes"), and the algorithms assume the feedback to be faithful. That is, when the user clicks "like," they actually prefer the item. We argue that this fundamental assumption can be extensively violated by human users, who are not passive feedback sources. Instead, they are in control, actively steering the system towards their goal. To verify this hypothesis, that humans steer and are able to improve performance by steering, we designed a function optimization task where a human and an optimization algorithm collaborate to find the maximum of a 1-dimensional function. At each iteration, the optimization algorithm queries the user for the value of a hidden function $f$ at a point $x$, and the user, who sees the hidden function, provides an answer about $f(x)$. Our study on 21 participants shows that users who understand how the optimization works, strategically provide biased answers (answers not equal to $f(x)$), which results in the algorithm finding the optimum significantly faster. Our work highlights that next-generation intelligent systems will need user models capable of helping users who steer systems to pursue their goals.
Probabilistic Formulation of the Take The Best Heuristic
Nov 01, 2019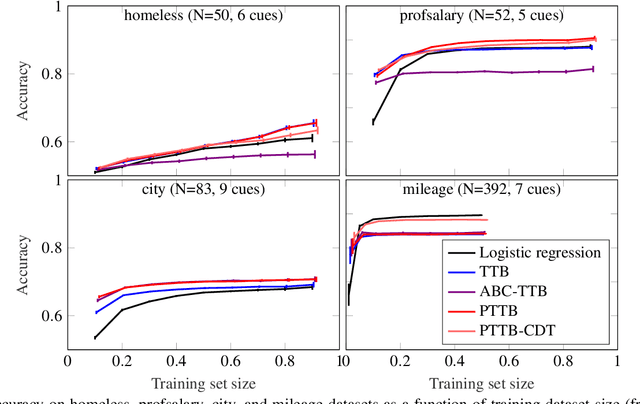
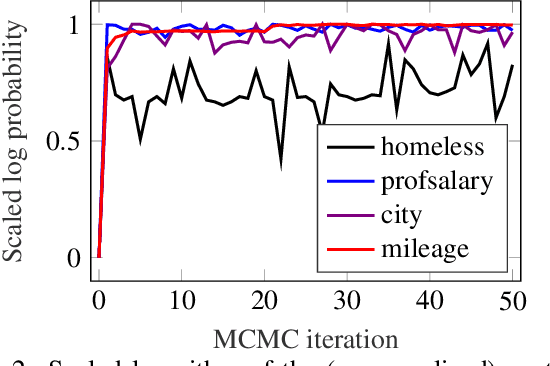
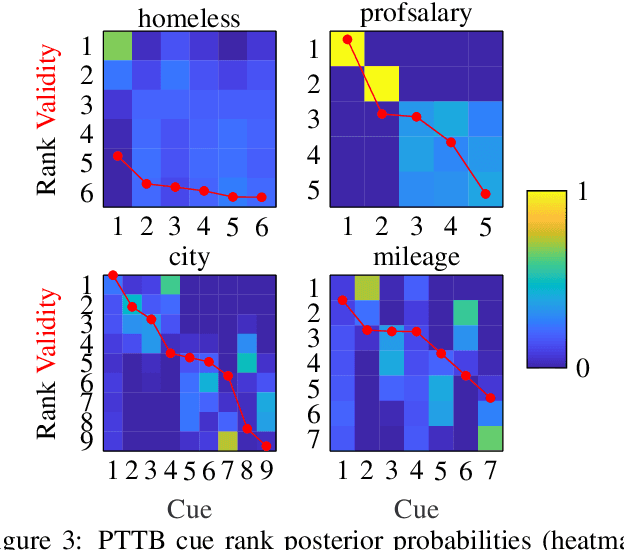

The framework of cognitively bounded rationality treats problem solving as fundamentally rational, but emphasises that it is constrained by cognitive architecture and the task environment. This paper investigates a simple decision making heuristic, Take The Best (TTB), within that framework. We formulate TTB as a likelihood-based probabilistic model, where the decision strategy arises by probabilistic inference based on the training data and the model constraints. The strengths of the probabilistic formulation, in addition to providing a bounded rational account of the learning of the heuristic, include natural extensibility with additional cognitively plausible constraints and prior information, and the possibility to embed the heuristic as a subpart of a larger probabilistic model. We extend the model to learn cue discrimination thresholds for continuous-valued cues and experiment with using the model to account for biased preference feedback from a boundedly rational agent in a simulated interactive machine learning task.