 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraPLUS: Graph-based Placement Using Semantics for Image Composition
Mar 20, 2025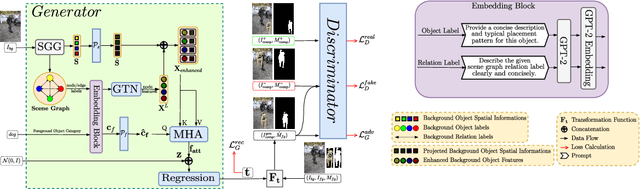
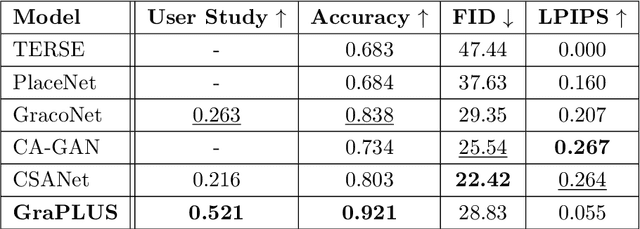
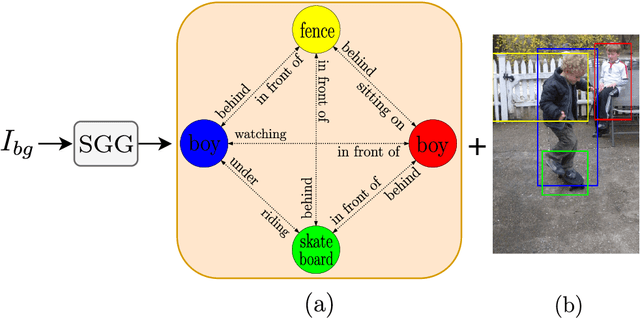
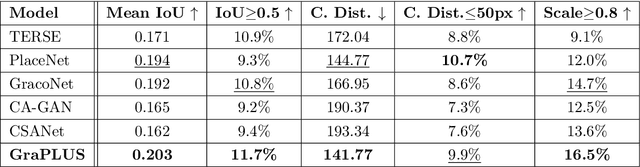
We present GraPLUS (Graph-based Placement Using Semantics), a novel framework for plausible object placement in images that leverages scene graphs and large language models. Our approach uniquely combines graph-structured scene representation with semantic understanding to determine contextually appropriate object positions. The framework employs GPT-2 to transform categorical node and edge labels into rich semantic embeddings that capture both definitional characteristics and typical spatial contexts, enabling nuanced understanding of object relationships and placement patterns. GraPLUS achieves placement accuracy of 92.1% and an FID score of 28.83 on the OPA dataset, outperforming state-of-the-art methods by 8.1% while maintaining competitive visual quality. In human evaluation studies involving 964 samples assessed by 19 participants, our method was preferred in 52.1% of cases, significantly outperforming previous approaches. The framework's key innovations include: (i) leveraging pre-trained scene graph models that transfer knowledge from other domains, (ii) edge-aware graph neural networks that process scene semantics through structured relationships, (iii) a cross-modal attention mechanism that aligns categorical embeddings with enhanced scene features, and (iv) a multiobjective training strategy incorporating semantic consistency constraints.