 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-resolution home location prediction from tweets using deep learning with dynamic structure
Feb 03, 2019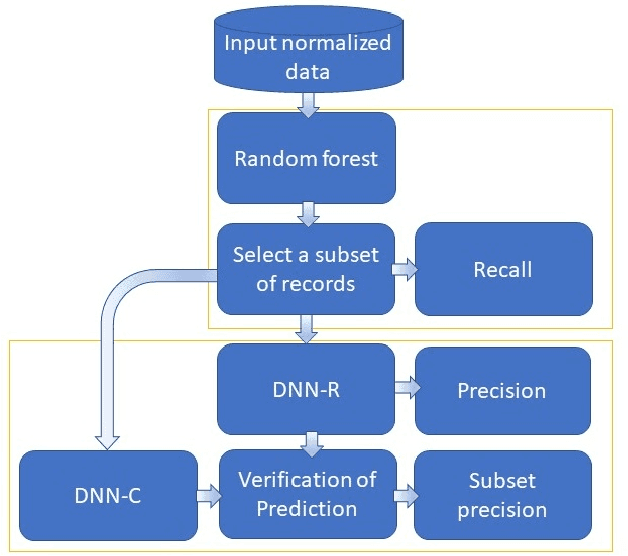

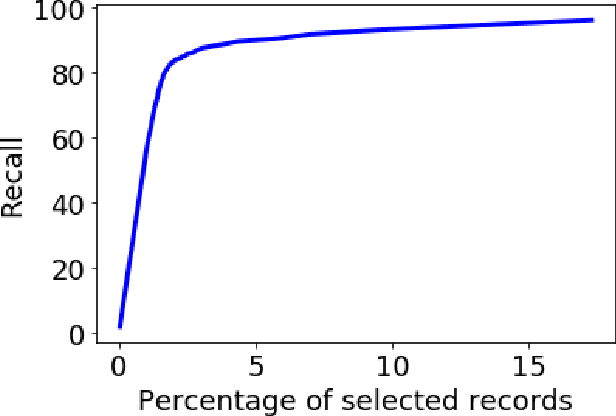
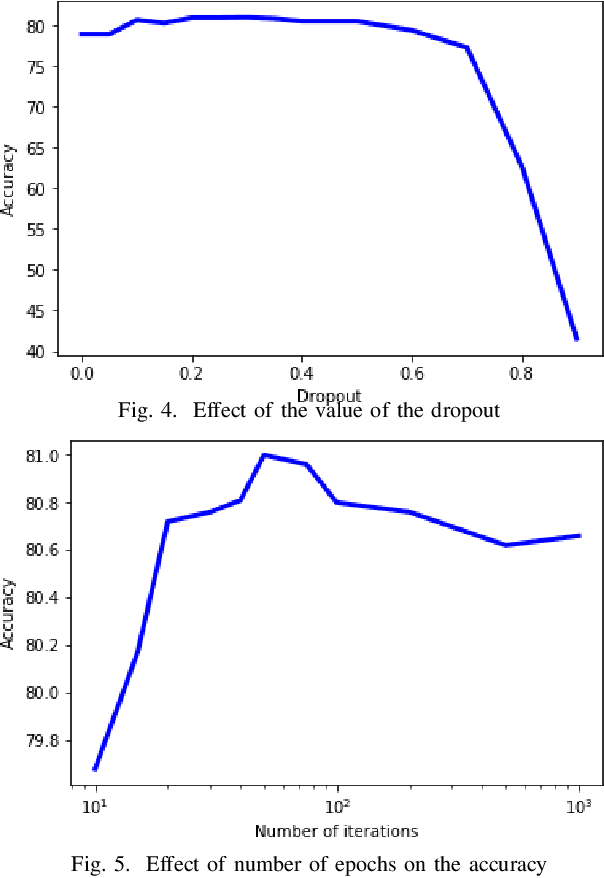
High-resolution prediction of the home location of people has applications in diverse fields, including agriculture, transportation, and public health. The goal here is to obtain an accurate estimate of home locations of a sufficiently large subset of the population to subsequently use in models for the application domain. Conventional data sources, such as census and surveys, have a substantial time-lag and cannot capture seasonal trends. There has been much recent interest in the use of social media data to overcome this limitation. However, this data is usually sparse, noisy and user's home location is just one of several check-in locations. Due to these constraints, much of previous research has aimed at a coarse spatial resolution, such as at the time zone, state, and city levels. This is inadequate for important applications. For example, vector control to prevent epidemics would benefit from 200m resolution. Recent work has used a Support Vector Classifier on Twitter meta-data for such resolution, obtaining 70% accuracy for a 76% subset of the test population with 100m resolution. In contrast, we developed a deep learning model for this problem, applying a dynamic structure consisting of a random forest in the first phase and two fully connected deep neural networks in the second phase. We obtained over 90% on 30% subset of the test population. Given the large user base for Twitter, this is a sufficiently large subset for use in the modeling applications that we target. We believe that ours is the highest accuracy obtained for high-resolution home location prediction from Twitter data for both the entire sample and for its subsets. The primary contribution of this work lies in developing a deep-learning solution that uses a dynamic structure to deal with sparse and noisy social media data to yield accurate high resolution home locations from Twitter data.
Improving image watermarking based on Tabu search by Chaos
Sep 16, 2015



With the fast development of communication and multimedia technology, the rights of the owners of multimedia products is vulnerable to the unauthorized copies and watermarking is one of the best known methods for proving the ownership of a product. In this paper we prosper the previous watermarking method which was based on Tabu search by Chaos. The modification applied in the permutation step of watermarking and the initial population generation of the Tabu search. We analyze our method on some well known images and experimental results shows the improvement in the quality and speed of the proposed watermarking method.
Generating Graphical Chain by Mutual Matching of Bayesian Network and Extracted Rules of Bayesian Network Using Genetic Algorithm
Dec 15, 2014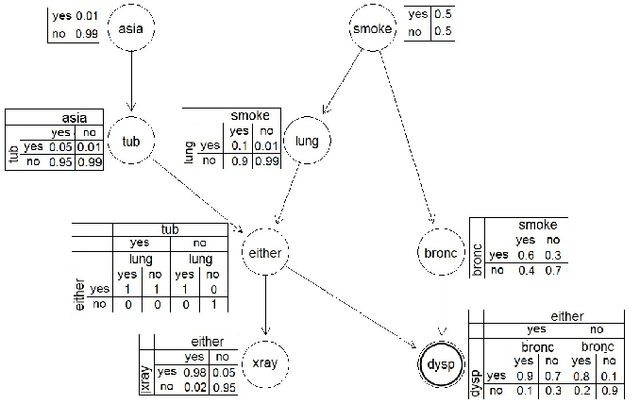
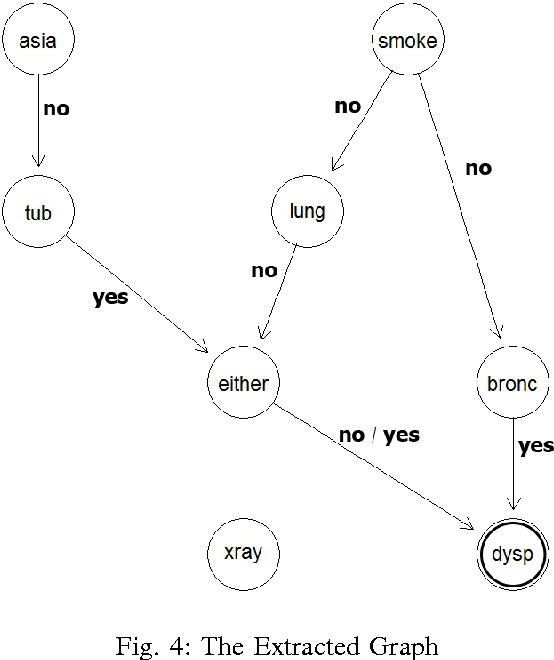
With the technology development, the need of analyze and extraction of useful information is increasing. Bayesian networks contain knowledge from data and experts that could be used for decision making processes But they are not easily understandable thus the rule extraction methods have been used but they have high computation costs. To overcome this problem we extract rules from Bayesian network using genetic algorithm. Then we generate the graphical chain by mutually matching the extracted rules and Bayesian network. This graphical chain could shows the sequence of events that lead to the target which could help the decision making process. The experimental results on small networks show that the proposed method has comparable results with brute force method which has a significantly higher computation cost.
Ambiguity-Driven Fuzzy C-Means Clustering: How to Detect Uncertain Clustered Records
Sep 09, 2014
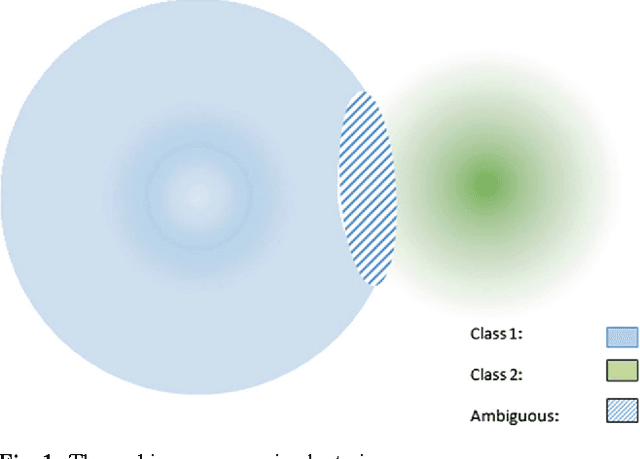
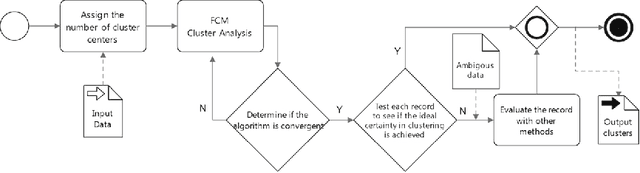

As a well-known clustering algorithm, Fuzzy C-Means (FCM) allows each input sample to belong to more than one cluster, providing more flexibility than non-fuzzy clustering methods. However, the accuracy of FCM is subject to false detections caused by noisy records, weak feature selection and low certainty of the algorithm in some cases. The false detections are very important in some decision-making application domains like network security and medical diagnosis, where weak decisions based on such false detections may lead to catastrophic outcomes. They are mainly emerged from making decisions about a subset of records that do not provide enough evidence to make a good decision. In this paper, we propose a method for detecting such ambiguous records in FCM by introducing a certainty factor to decrease invalid detections. This approach enables us to send the detected ambiguous records to another discrimination method for a deeper investigation, thus increasing the accuracy by lowering the error rate. Most of the records are still processed quickly and with low error rate which prevents performance loss compared to similar hybrid methods. Experimental results of applying the proposed method on several datasets from different domains show a significant decrease in error rate as well as improved sensitivity of the algorithm.