 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAST Model: Deciding About Semantic Complexity of a Text
Paper and Code
Oct 01, 2019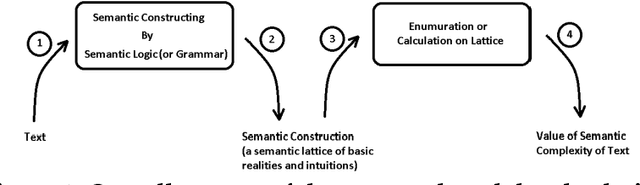
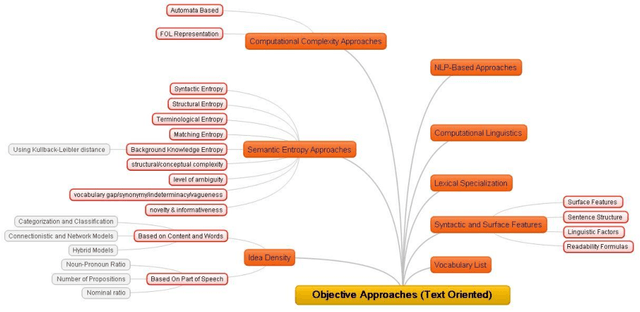
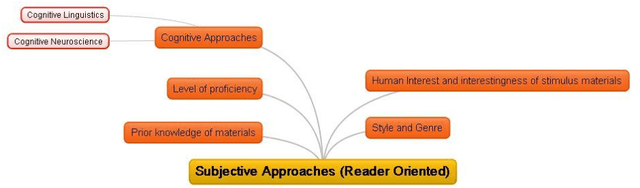
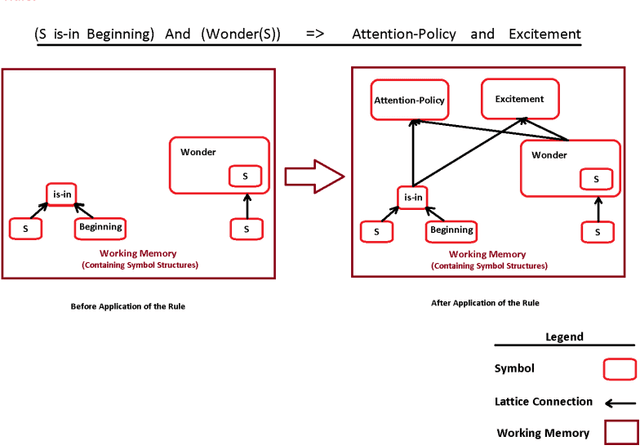
Measuring text complexity is an essential task in several fields and applications (such as NLP, semantic web, smart education, etc.). The semantic layer of text is more tacit than its syntactic structure and, as a result, calculation of semantic complexity is more difficult than syntactic complexity. While there are famous and powerful academic and commercial syntactic complexity measures, the problem of measuring semantic complexity is still a challenging one. In this paper, we introduce the DAST model, which stands for Deciding About Semantic Complexity of a Text. DAST proposes an intuitionistic approach to semantics that lets us have a well-defined model for the semantics of a text and its complexity: semantic is considered as a lattice of intuitions and, as a result, semantic complexity is defined as the result of a calculation on this lattice. A set theoretic formal definition of semantic complexity, as a 6-tuple formal system, is provided. By using this formal system, a method for measuring semantic complexity is presented. The evaluation of the proposed approach is done by a set of three human-judgment experiments. The results show that DAST model is capable of deciding about semantic complexity of text. Furthermore, the analysis of the results leads us to introduce a Markovian model for the process of common-sense, multiple-steps and semantic-complexity reasoning in people. The results of Experiments demonstrate that our method outperforms the random baseline with improvement in precision and accuracy.