 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Bayesian Federated Learning with Wasserstein Barycenter Aggregation
May 20, 2025Personalized Bayesian federated learning (PBFL) handles non-i.i.d. client data and quantifies uncertainty by combining personalization with Bayesian inference. However, existing PBFL methods face two limitations: restrictive parametric assumptions in client posterior inference and naive parameter averaging for server aggregation. To overcome these issues, we propose FedWBA, a novel PBFL method that enhances both local inference and global aggregation. At the client level, we use particle-based variational inference for nonparametric posterior representation. At the server level, we introduce particle-based Wasserstein barycenter aggregation, offering a more geometrically meaningful approach. Theoretically, we provide local and global convergence guarantees for FedWBA. Locally, we prove a KL divergence decrease lower bound per iteration for variational inference convergence. Globally, we show that the Wasserstein barycenter converges to the true parameter as the client data size increases. Empirically, experiments show that FedWBA outperforms baselines in prediction accuracy, uncertainty calibration, and convergence rate, with ablation studies confirming its robustness.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023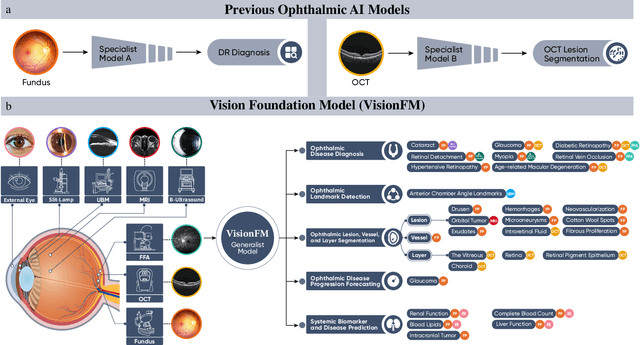
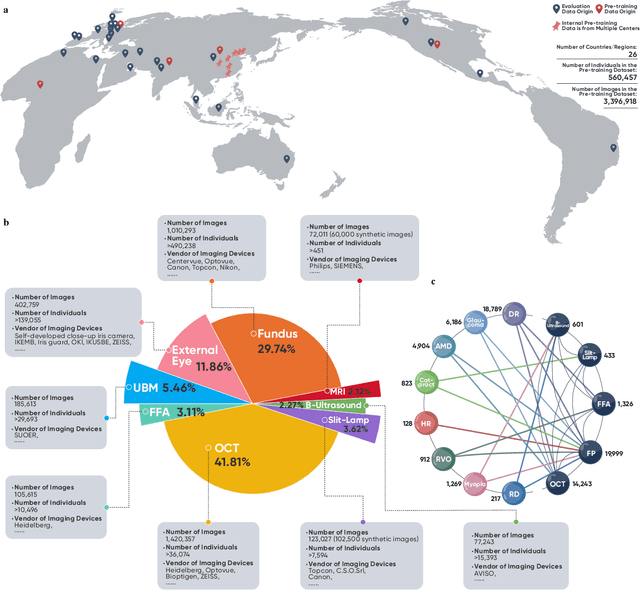

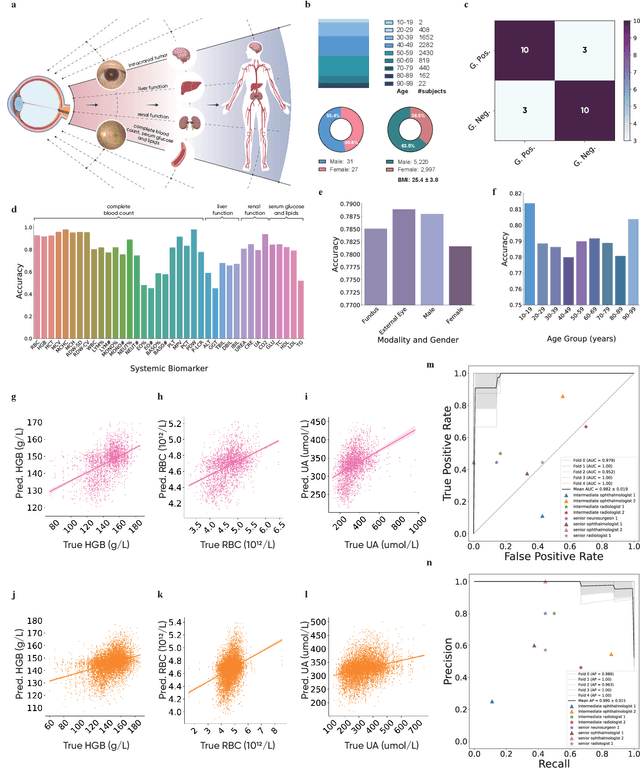
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
A Joint Model for Aspect-Category Sentiment Analysis with Contextualized Aspect Embedding
Aug 29, 2019
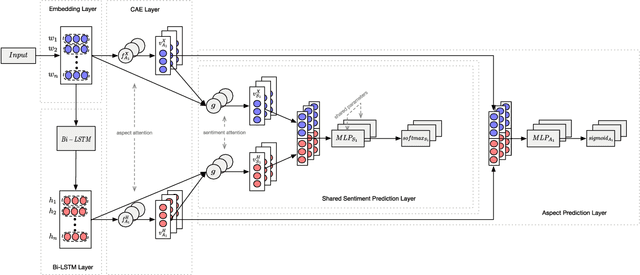


Aspect-category sentiment analysis (ACSA) aims to identify all the aspect categories mentioned in the text and their corresponding sentiment polarities. Some joint models have been proposed to address this task. However, these joint models do not solve the following two problems well: mismatching between the aspect categories and the sentiment words, and data deficiency of some aspect categories. To solve them, we propose a novel joint model which contains a contextualized aspect embedding layer and a shared sentiment prediction layer. The contextualized aspect embedding layer extracts the aspect category related information, which is used to generate aspect-specific representations for sentiment classification like traditional context-independent aspect embedding (CIAE) and is therefore called contextualized aspect embedding (CAE). The CAE can mitigate the mismatching problem because it is semantically more related to sentiment words than CIAE. The shared sentiment prediction layer transfers sentiment knowledge between aspect categories and alleviates the problem caused by data deficiency. Experiments conducted on SemEval 2016 Datasets show that our proposed model achieves state-of-the-art performance.