 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Oct 27, 2023



The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
Predicting Three Types of Freezing of Gait Events Using Deep Learning Models
Oct 10, 2023



Freezing of gait is a Parkinson's Disease symptom that episodically inflicts a patient with the inability to step or turn while walking. While medical experts have discovered various triggers and alleviating actions for freezing of gait, the underlying causes and prediction models are still being explored today. Current freezing of gait prediction models that utilize machine learning achieve high sensitivity and specificity in freezing of gait predictions based on time-series data; however, these models lack specifications on the type of freezing of gait events. We develop various deep learning models using the transformer encoder architecture plus Bidirectional LSTM layers and different feature sets to predict the three different types of freezing of gait events. The best performing model achieves a score of 0.427 on testing data, which would rank top 5 in Kaggle's Freezing of Gait prediction competition, hosted by THE MICHAEL J. FOX FOUNDATION. However, we also recognize overfitting in training data that could be potentially improved through pseudo labelling on additional data and model architecture simplification.
A Machine Learning Approach to Detect Dehydration in Afghan Children
May 22, 2023Child dehydration is a significant health concern, especially among children under 5 years of age who are more susceptible to diarrhea and vomiting. In Afghanistan, severe diarrhea contributes to child mortality due to dehydration. However, there is no evidence of research exploring the potential of machine learning techniques in diagnosing dehydration in Afghan children under five. To fill this gap, this study leveraged various classifiers such as Random Forest, Multilayer Perceptron, Support Vector Machine, J48, and Logistic Regression to develop a predictive model using a dataset of sick children retrieved from the Afghanistan Demographic and Health Survey (ADHS). The primary objective was to determine the dehydration status of children under 5 years. Among all the classifiers, Random Forest proved to be the most effective, achieving an accuracy of 91.46%, precision of 91%, and AUC of 94%. This model can potentially assist healthcare professionals in promptly and accurately identifying dehydration in under five children, leading to timely interventions, and reducing the risk of severe health complications. Our study demonstrates the potential of machine learning techniques in improving the early diagnosis of dehydration in Afghan children.
Mutual Information and Ensemble Based Feature Recommender for Renal Cancer Stage Classification
Sep 28, 2022
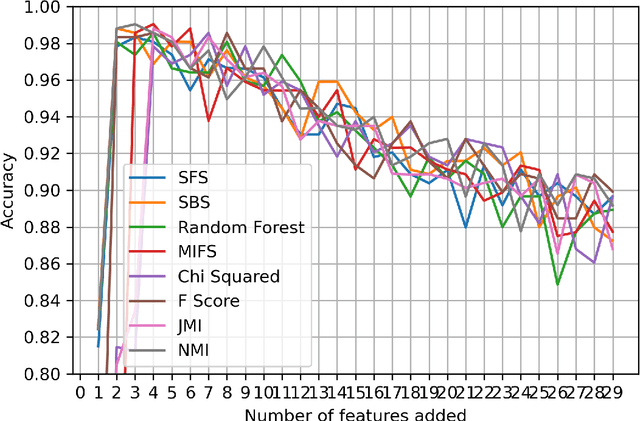
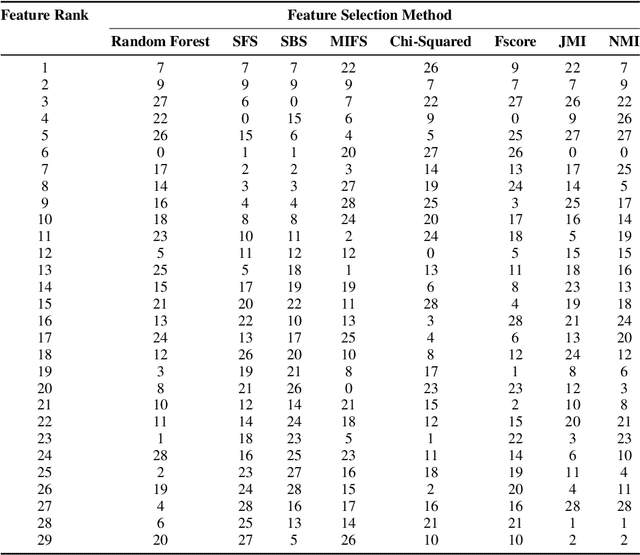
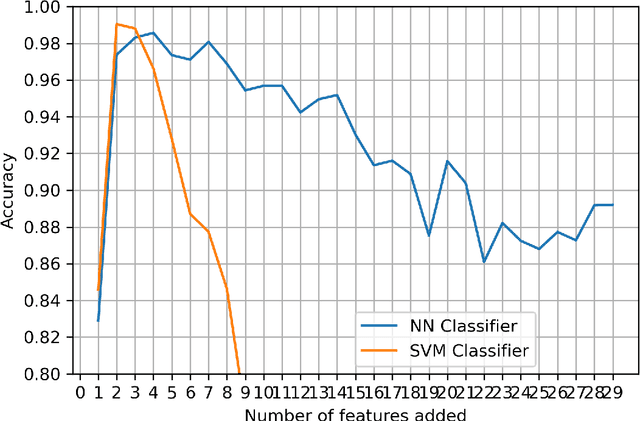
Kidney is an essential organ in human body. It maintains homeostasis and removes harmful substances through urine. Renal cell carcinoma (RCC) is the most common form of kidney cancer. Around 90\% of all kidney cancers are attributed to RCC. Most harmful type of RCC is clear cell renal cell carcinoma (ccRCC) that makes up about 80\% of all RCC cases. Early and accurate detection of ccRCC is necessary to prevent further spreading of the disease in other organs. In this article, a detailed experimentation is done to identify important features which can aid in diagnosing ccRCC at different stages. The ccRCC dataset is obtained from The Cancer Genome Atlas (TCGA). A novel mutual information and ensemble based feature ranking approach considering the order of features obtained from 8 popular feature selection methods is proposed. Performance of the proposed method is evaluated by overall classification accuracy obtained using 2 different classifiers (ANN and SVM). Experimental results show that the proposed feature ranking method is able to attain a higher accuracy (96.6\% and 98.6\% using SVM and NN, respectively) for classifying different stages of ccRCC with a reduced feature set as compared to existing work. It is also to be noted that, out of 3 distinguishing features as mentioned by the existing TNM system (proposed by AJCC and UICC), our proposed method was able to select two of them (size of tumour, metastasis status) as the top-most ones. This establishes the efficacy of our proposed approach.
Personality Type Based on Myers-Briggs Type Indicator with Text Posting Style by using Traditional and Deep Learning
Jan 21, 2022

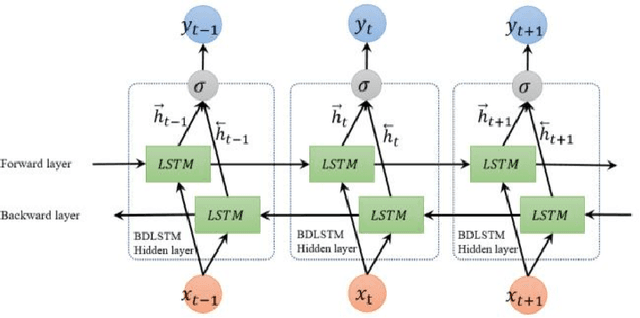
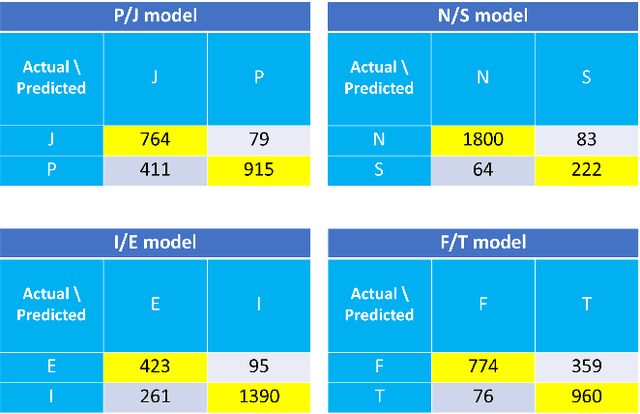
The term personality may be expressed in terms of the individual differences in characteristics pattern of thinking, feeling, and behavior. This work presents several machine learning techniques including Naive Bayes, Support Vector Machines, and Recurrent Neural Networks to predict people personality from text based on Myers-Briggs Type Indicator (MBTI). Furthermore, this project applies CRISP-DM, which stands for Cross-Industry Standard Process for Data Mining, to guide the learning process. Since, CRISP-DM is kind of iterative development, we have adopted it with agile methodology, which is a rapid iterative software development method, in order to reduce the development cycle to be minimal.
Combination of Transfer Learning, Recursive Learning and Ensemble Learning for Multi-Day Ahead COVID-19 Cases Prediction in India using Gated Recurrent Unit Networks
Aug 20, 2021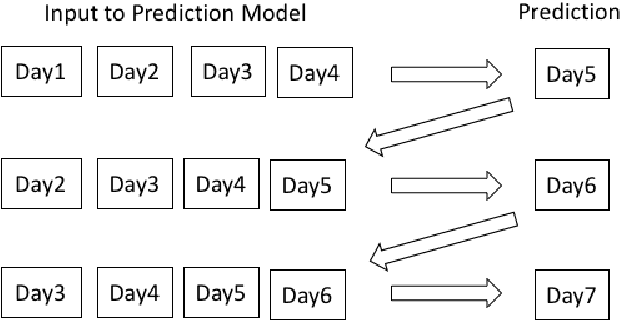



The current COVID-19 pandemic has put a huge challenge on the Indian health infrastructure. With more and more people getting affected during the second wave, the hospitals were over-burdened, running out of supplies and oxygen. In this scenario, prediction of the number of COVID-19 cases beforehand might have helped in the better utilization of limited resources and supplies. This manuscript deals with the prediction of new COVID-19 cases, new deaths and total active cases for multiple days in advance. The proposed method uses gated recurrent unit networks as the main predicting model. A study is conducted by building four models that are pre-trained on the data from four different countries (United States of America, Brazil, Spain and Bangladesh) and are fine-tuned or retrained on India's data. Since the four countries chosen have experienced different types of infection curves, the pre-training provides a transfer learning to the models incorporating diverse situations into account. Each of the four models then give a multiple days ahead predictions using recursive learning method for the Indian test data. The final prediction comes from an ensemble of the predictions of the combination of different models. This method with two countries, Spain and Brazil, is seen to achieve the best performance amongst all the combinations as well as compared to other traditional regression models.