 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoder based Hybrid Multi-Task Predictor Network for Daily Open-High-Low-Close Prices Prediction of Indian Stocks
Apr 28, 2022


Stock prices are highly volatile and sudden changes in trends are often very problematic for traditional forecasting models to handle. The standard Long Short Term Memory (LSTM) networks are regarded as the state-of-the-art models for such predictions. But, these models fail to handle sudden and drastic changes in the price trend. Moreover, there are some inherent constraints with the open, high, low and close (OHLC) prices of the stocks. Literature lacks the study on the inherent property of OHLC prices. We argue that predicting the OHLC prices for the next day is much more informative than predicting the trends of the stocks as the trend is mostly calculated using these OHLC prices only. The problem mainly is focused on Buy-Today Sell-Tomorrow (BTST) trading. In this regard, AEs when pre-trained with the stock prices, may be beneficial. A novel framework is proposed where a pre-trained encoder is cascaded in front of the multi-task predictor network. This hybrid network can leverage the power of a combination of networks and can both handle the OHLC constraints as well as capture any sudden drastic changes in the prices. It is seen that such a network is much more efficient at predicting stock prices. The experiments have been extended to recommend the most profitable and most overbought stocks on the next day. The model has been tested for multiple Indian companies and it is found that the recommendations from the proposed model have not resulted in a single loss for a test period of 300 days.
Improving the Robustness of Federated Learning for Severely Imbalanced Datasets
Apr 28, 2022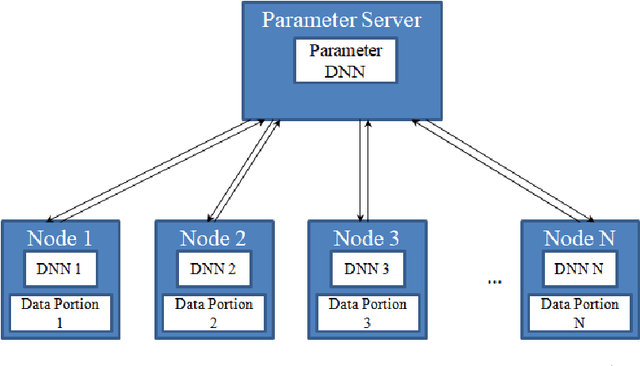


With the ever increasing data deluge and the success of deep neural networks, the research of distributed deep learning has become pronounced. Two common approaches to achieve this distributed learning is synchronous and asynchronous weight update. In this manuscript, we have explored very simplistic synchronous weight update mechanisms. It has been seen that with an increasing number of worker nodes, the performance degrades drastically. This effect has been studied in the context of extreme imbalanced classification (e.g. outlier detection). In practical cases, the assumed conditions of i.i.d. may not be fulfilled. There may also arise global class imbalance situations like that of outlier detection where the local servers receive severely imbalanced data and may not get any samples from the minority class. In that case, the DNNs in the local servers will get completely biased towards the majority class that they receive. This would highly impact the learning at the parameter server (which practically does not see any data). It has been observed that in a parallel setting if one uses the existing federated weight update mechanisms at the parameter server, the performance degrades drastically with the increasing number of worker nodes. This is mainly because, with the increasing number of nodes, there is a high chance that one worker node gets a very small portion of the data, either not enough to train the model without overfitting or having a highly imbalanced class distribution. The chapter, hence, proposes a workaround to this problem by introducing the concept of adaptive cost-sensitive momentum averaging. It is seen that for the proposed system, there was no to minimal degradation in performance while most of the other methods hit their bottom performance before that.
Unsupervised Change Detection in Hyperspectral Images using Feature Fusion Deep Convolutional Autoencoders
Sep 10, 2021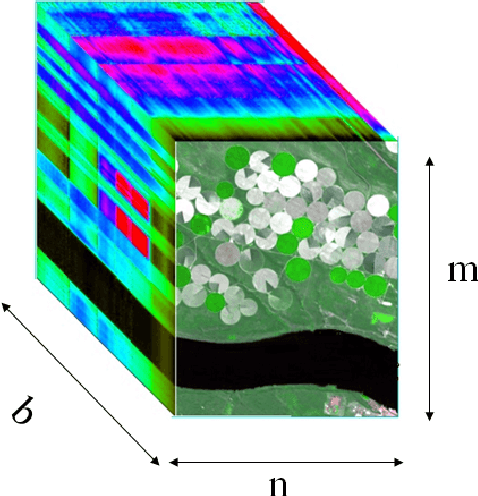

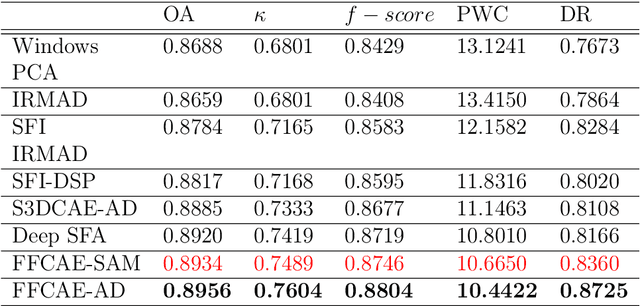
Binary change detection in bi-temporal co-registered hyperspectral images is a challenging task due to a large number of spectral bands present in the data. Researchers, therefore, try to handle it by reducing dimensions. The proposed work aims to build a novel feature extraction system using a feature fusion deep convolutional autoencoder for detecting changes between a pair of such bi-temporal co-registered hyperspectral images. The feature fusion considers features across successive levels and multiple receptive fields and therefore adds a competitive edge over the existing feature extraction methods. The change detection technique described is completely unsupervised and is much more elegant than other supervised or semi-supervised methods which require some amount of label information. Different methods have been applied to the extracted features to find the changes in the two images and it is found that the proposed method clearly outperformed the state of the art methods in unsupervised change detection for all the datasets.
Combination of Transfer Learning, Recursive Learning and Ensemble Learning for Multi-Day Ahead COVID-19 Cases Prediction in India using Gated Recurrent Unit Networks
Aug 20, 2021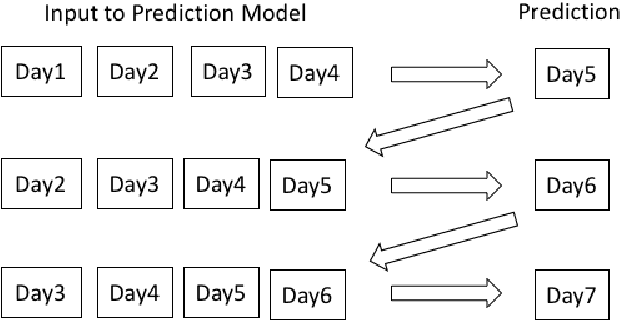



The current COVID-19 pandemic has put a huge challenge on the Indian health infrastructure. With more and more people getting affected during the second wave, the hospitals were over-burdened, running out of supplies and oxygen. In this scenario, prediction of the number of COVID-19 cases beforehand might have helped in the better utilization of limited resources and supplies. This manuscript deals with the prediction of new COVID-19 cases, new deaths and total active cases for multiple days in advance. The proposed method uses gated recurrent unit networks as the main predicting model. A study is conducted by building four models that are pre-trained on the data from four different countries (United States of America, Brazil, Spain and Bangladesh) and are fine-tuned or retrained on India's data. Since the four countries chosen have experienced different types of infection curves, the pre-training provides a transfer learning to the models incorporating diverse situations into account. Each of the four models then give a multiple days ahead predictions using recursive learning method for the Indian test data. The final prediction comes from an ensemble of the predictions of the combination of different models. This method with two countries, Spain and Brazil, is seen to achieve the best performance amongst all the combinations as well as compared to other traditional regression models.