 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Federated Learning for Severely Imbalanced Datasets
Paper and Code
Apr 28, 2022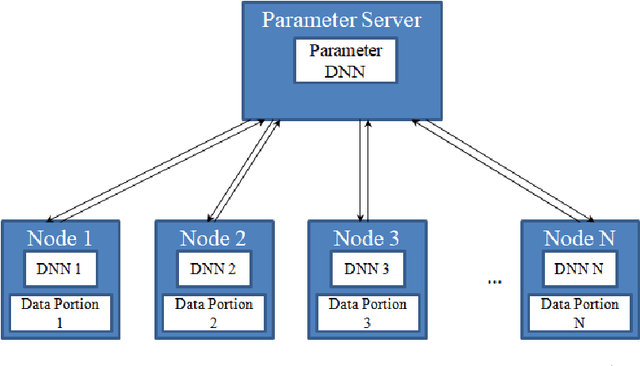
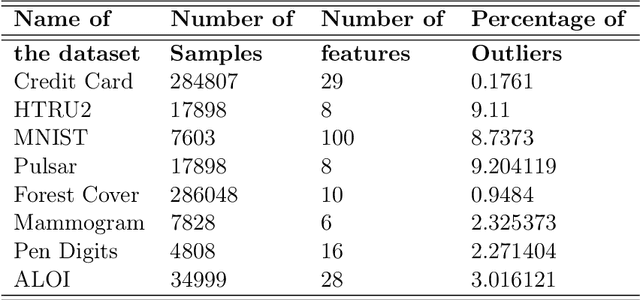


With the ever increasing data deluge and the success of deep neural networks, the research of distributed deep learning has become pronounced. Two common approaches to achieve this distributed learning is synchronous and asynchronous weight update. In this manuscript, we have explored very simplistic synchronous weight update mechanisms. It has been seen that with an increasing number of worker nodes, the performance degrades drastically. This effect has been studied in the context of extreme imbalanced classification (e.g. outlier detection). In practical cases, the assumed conditions of i.i.d. may not be fulfilled. There may also arise global class imbalance situations like that of outlier detection where the local servers receive severely imbalanced data and may not get any samples from the minority class. In that case, the DNNs in the local servers will get completely biased towards the majority class that they receive. This would highly impact the learning at the parameter server (which practically does not see any data). It has been observed that in a parallel setting if one uses the existing federated weight update mechanisms at the parameter server, the performance degrades drastically with the increasing number of worker nodes. This is mainly because, with the increasing number of nodes, there is a high chance that one worker node gets a very small portion of the data, either not enough to train the model without overfitting or having a highly imbalanced class distribution. The chapter, hence, proposes a workaround to this problem by introducing the concept of adaptive cost-sensitive momentum averaging. It is seen that for the proposed system, there was no to minimal degradation in performance while most of the other methods hit their bottom performance before that.