 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
ALoRE: Efficient Visual Adaptation via Aggregating Low Rank Experts
Dec 11, 2024



Parameter-efficient transfer learning (PETL) has become a promising paradigm for adapting large-scale vision foundation models to downstream tasks. Typical methods primarily leverage the intrinsic low rank property to make decomposition, learning task-specific weights while compressing parameter size. However, such approaches predominantly manipulate within the original feature space utilizing a single-branch structure, which might be suboptimal for decoupling the learned representations and patterns. In this paper, we propose ALoRE, a novel PETL method that reuses the hypercomplex parameterized space constructed by Kronecker product to Aggregate Low Rank Experts using a multi-branch paradigm, disentangling the learned cognitive patterns during training. Thanks to the artful design, ALoRE maintains negligible extra parameters and can be effortlessly merged into the frozen backbone via re-parameterization in a sequential manner, avoiding additional inference latency. We conduct extensive experiments on 24 image classification tasks using various backbone variants. Experimental results demonstrate that ALoRE outperforms the full fine-tuning strategy and other state-of-the-art PETL methods in terms of performance and parameter efficiency. For instance, ALoRE obtains 3.06% and 9.97% Top-1 accuracy improvement on average compared to full fine-tuning on the FGVC datasets and VTAB-1k benchmark by only updating 0.15M parameters.
ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding
Sep 05, 2024



Automatic chart understanding is crucial for content comprehension and document parsing. Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in chart understanding through domain-specific alignment and fine-tuning. However, the application of alignment training within the chart domain is still underexplored. To address this, we propose ChartMoE, which employs the mixture of expert (MoE) architecture to replace the traditional linear projector to bridge the modality gap. Specifically, we train multiple linear connectors through distinct alignment tasks, which are utilized as the foundational initialization parameters for different experts. Additionally, we introduce ChartMoE-Align, a dataset with over 900K chart-table-JSON-code quadruples to conduct three alignment tasks (chart-table/JSON/code). Combined with the vanilla connector, we initialize different experts in four distinct ways and adopt high-quality knowledge learning to further refine the MoE connector and LLM parameters. Extensive experiments demonstrate the effectiveness of the MoE connector and our initialization strategy, e.g., ChartMoE improves the accuracy of the previous state-of-the-art from 80.48% to 84.64% on the ChartQA benchmark.
IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
Mar 02, 2024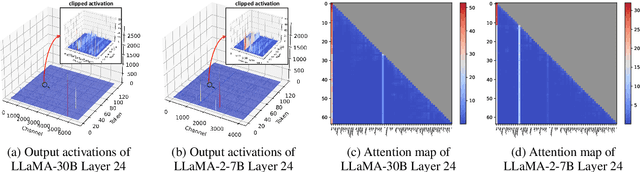
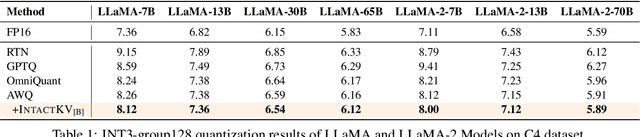

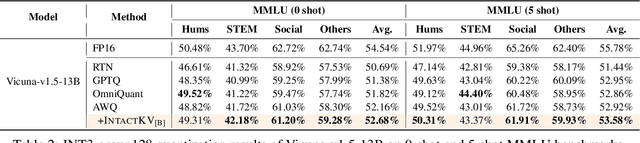
Large language models (LLMs) excel in natural language processing but demand intensive computation. To mitigate this, various quantization methods have been explored, yet they compromise LLM performance. This paper unveils a previously overlooked type of outlier in LLMs. Such outliers are found to allocate most of the attention scores on initial tokens of input, termed as pivot tokens, which is crucial to the performance of quantized LLMs. Given that, we propose IntactKV to generate the KV cache of pivot tokens losslessly from the full-precision model. The approach is simple and easy to combine with existing quantization solutions. Besides, IntactKV can be calibrated as additional LLM parameters to boost the quantized LLMs further. Mathematical analysis also proves that IntactKV effectively reduces the upper bound of quantization error. Empirical results show that IntactKV brings consistent improvement and achieves lossless weight-only INT4 quantization on various downstream tasks, leading to the new state-of-the-art for LLM quantization.
ChartBench: A Benchmark for Complex Visual Reasoning in Charts
Dec 26, 2023Multimodal Large Language Models (MLLMs) have demonstrated remarkable multimodal understanding and generation capabilities. However, their understanding of synthetic charts is limited, while existing benchmarks are simplistic and the charts deviate significantly from real-world examples, making it challenging to accurately assess MLLMs' chart comprehension abilities. Hence, a challenging benchmark is essential for investigating progress and uncovering the limitations of current MLLMs on chart data. In this work, we propose to examine chart comprehension through more complex visual logic and introduce ChartBench, a comprehensive chart benchmark to accurately measure MLLMs' fundamental chart comprehension and data reliability. Specifically, ChartBench consists of \textbf{41} categories, \textbf{2K} charts, and \textbf{16K} QA annotations. While significantly expanding chart types, ChartBench avoids direct labelling of data points, which requires MLLMs to infer values akin to humans by leveraging elements like color, legends, and coordinate systems. We also introduce an improved metric, \textit{Acc+}, which accurately reflects MLLMs' chart comprehension abilities while avoiding labor-intensive manual evaluations or costly GPT-based evaluations. We conduct evaluations on \textbf{12} mainstream open-source models and \textbf{2} outstanding proprietary models. Through extensive experiments, we reveal the limitations of MLLMs on charts and provide insights to inspire the community to pay closer attention to MLLMs' chart comprehension abilities. The benchmark and code will be publicly available for research.
Towards Effective Collaborative Learning in Long-Tailed Recognition
May 05, 2023



Real-world data usually suffers from severe class imbalance and long-tailed distributions, where minority classes are significantly underrepresented compared to the majority ones. Recent research prefers to utilize multi-expert architectures to mitigate the model uncertainty on the minority, where collaborative learning is employed to aggregate the knowledge of experts, i.e., online distillation. In this paper, we observe that the knowledge transfer between experts is imbalanced in terms of class distribution, which results in limited performance improvement of the minority classes. To address it, we propose a re-weighted distillation loss by comparing two classifiers' predictions, which are supervised by online distillation and label annotations, respectively. We also emphasize that feature-level distillation will significantly improve model performance and increase feature robustness. Finally, we propose an Effective Collaborative Learning (ECL) framework that integrates a contrastive proxy task branch to further improve feature quality. Quantitative and qualitative experiments on four standard datasets demonstrate that ECL achieves state-of-the-art performance and the detailed ablation studies manifest the effectiveness of each component in ECL.
Rethink Long-tailed Recognition with Vision Transforms
Feb 28, 2023In the real world, data tends to follow long-tailed distributions w.r.t. class or attribution, motivating the challenging Long-Tailed Recognition (LTR) problem. In this paper, we revisit recent LTR methods with promising Vision Transformers (ViT). We figure out that 1) ViT is hard to train with long-tailed data. 2) ViT learns generalized features in an unsupervised manner, like mask generative training, either on long-tailed or balanced datasets. Hence, we propose to adopt unsupervised learning to utilize long-tailed data. Furthermore, we propose the Predictive Distribution Calibration (PDC) as a novel metric for LTR, where the model tends to simply classify inputs into common classes. Our PDC can measure the model calibration of predictive preferences quantitatively. On this basis, we find many LTR approaches alleviate it slightly, despite the accuracy improvement. Extensive experiments on benchmark datasets validate that PDC reflects the model's predictive preference precisely, which is consistent with the visualization.
Learning Imbalanced Data with Vision Transformers
Dec 05, 2022



The real-world data tends to be heavily imbalanced and severely skew the data-driven deep neural networks, which makes Long-Tailed Recognition (LTR) a massive challenging task. Existing LTR methods seldom train Vision Transformers (ViTs) with Long-Tailed (LT) data, while the off-the-shelf pretrain weight of ViTs always leads to unfair comparisons. In this paper, we systematically investigate the ViTs' performance in LTR and propose LiVT to train ViTs from scratch only with LT data. With the observation that ViTs suffer more severe LTR problems, we conduct Masked Generative Pretraining (MGP) to learn generalized features. With ample and solid evidence, we show that MGP is more robust than supervised manners. In addition, Binary Cross Entropy (BCE) loss, which shows conspicuous performance with ViTs, encounters predicaments in LTR. We further propose the balanced BCE to ameliorate it with strong theoretical groundings. Specially, we derive the unbiased extension of Sigmoid and compensate extra logit margins to deploy it. Our Bal-BCE contributes to the quick convergence of ViTs in just a few epochs. Extensive experiments demonstrate that with MGP and Bal-BCE, LiVT successfully trains ViTs well without any additional data and outperforms comparable state-of-the-art methods significantly, e.g., our ViT-B achieves 81.0% Top-1 accuracy in iNaturalist 2018 without bells and whistles. Code is available at https://github.com/XuZhengzhuo/LiVT.
HyP$^2$ Loss: Beyond Hypersphere Metric Space for Multi-label Image Retrieval
Aug 14, 2022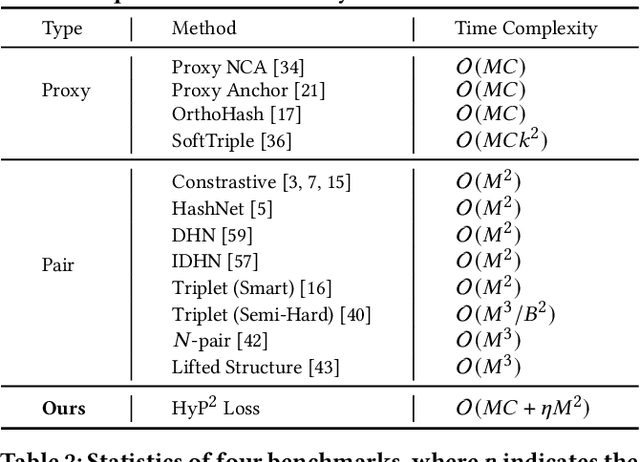
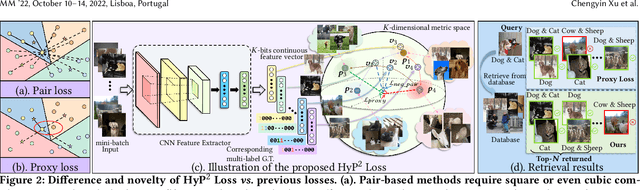
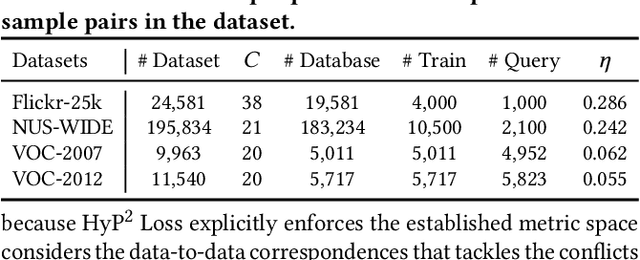
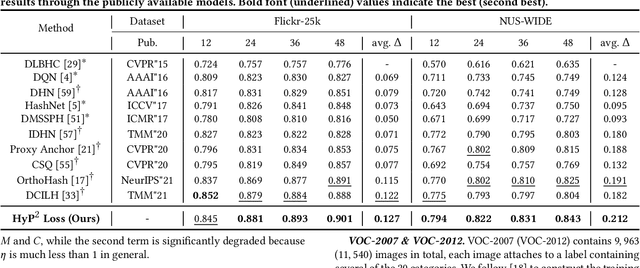
Image retrieval has become an increasingly appealing technique with broad multimedia application prospects, where deep hashing serves as the dominant branch towards low storage and efficient retrieval. In this paper, we carried out in-depth investigations on metric learning in deep hashing for establishing a powerful metric space in multi-label scenarios, where the pair loss suffers high computational overhead and converge difficulty, while the proxy loss is theoretically incapable of expressing the profound label dependencies and exhibits conflicts in the constructed hypersphere space. To address the problems, we propose a novel metric learning framework with Hybrid Proxy-Pair Loss (HyP$^2$ Loss) that constructs an expressive metric space with efficient training complexity w.r.t. the whole dataset. The proposed HyP$^2$ Loss focuses on optimizing the hypersphere space by learnable proxies and excavating data-to-data correlations of irrelevant pairs, which integrates sufficient data correspondence of pair-based methods and high-efficiency of proxy-based methods. Extensive experiments on four standard multi-label benchmarks justify the proposed method outperforms the state-of-the-art, is robust among different hash bits and achieves significant performance gains with a faster, more stable convergence speed. Our code is available at https://github.com/JerryXu0129/HyP2-Loss.
REALY: Rethinking the Evaluation of 3D Face Reconstruction
Mar 18, 2022

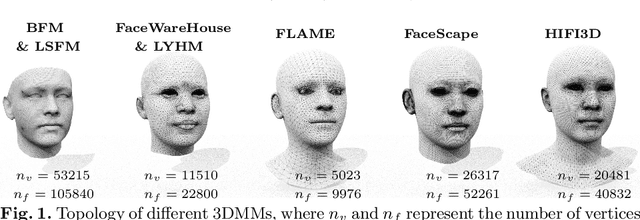
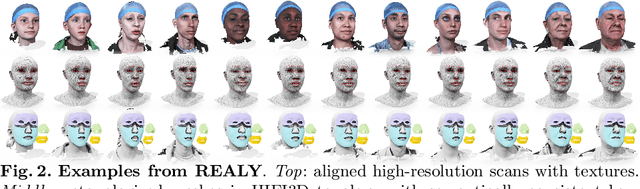
The evaluation of 3D face reconstruction results typically relies on a rigid shape alignment between the estimated 3D model and the ground-truth scan. We observe that aligning two shapes with different reference points can largely affect the evaluation results. This poses difficulties for precisely diagnosing and improving a 3D face reconstruction method. In this paper, we propose a novel evaluation approach with a new benchmark REALY, consists of 100 globally aligned face scans with accurate facial keypoints, high-quality region masks, and topology-consistent meshes. Our approach performs region-wise shape alignment and leads to more accurate, bidirectional correspondences during computing the shape errors. The fine-grained, region-wise evaluation results provide us detailed understandings about the performance of state-of-the-art 3D face reconstruction methods. For example, our experiments on single-image based reconstruction methods reveal that DECA performs the best on nose regions, while GANFit performs better on cheek regions. Besides, a new and high-quality 3DMM basis, HIFI3D++, is further derived using the same procedure as we construct REALY to align and retopologize several 3D face datasets. We will release REALY, HIFI3D++, and our new evaluation pipeline at https://realy3dface.com.