 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
Mar 01, 2026Face recognition remains vulnerable to presentation attacks, calling for robust Face Anti-Spoofing (FAS) solutions. Recent MLLM-based FAS methods reformulate the binary classification task as the generation of brief textual descriptions to improve cross-domain generalization. However, their generalizability is still limited, as such descriptions mainly capture intuitive semantic cues (e.g., mask contours) while struggling to perceive fine-grained visual patterns. To address this limitation, we incorporate external visual tools into MLLMs to encourage deeper investigation of subtle spoof clues. Specifically, we propose the Tool-Augmented Reasoning FAS (TAR-FAS) framework, which reformulates the FAS task as a Chain-of-Thought with Visual Tools (CoT-VT) paradigm, allowing MLLMs to begin with intuitive observations and adaptively invoke external visual tools for fine-grained investigation. To this end, we design a tool-augmented data annotation pipeline and construct the ToolFAS-16K dataset, which contains multi-turn tool-use reasoning trajectories. Furthermore, we introduce a tool-aware FAS training pipeline, where Diverse-Tool Group Relative Policy Optimization (DT-GRPO) enables the model to autonomously learn efficient tool use. Extensive experiments under a challenging one-to-eleven cross-domain protocol demonstrate that TAR-FAS achieves SOTA performance while providing fine-grained visual investigation for trustworthy spoof detection.
MMAT-1M: A Large Reasoning Dataset for Multimodal Agent Tuning
Jul 29, 2025Large Language Models (LLMs), enhanced through agent tuning, have demonstrated remarkable capabilities in Chain-of-Thought (CoT) and tool utilization, significantly surpassing the performance of standalone models. However, the multimodal domain still lacks a large-scale, high-quality agent tuning dataset to unlock the full potential of multimodal large language models. To bridge this gap, we introduce MMAT-1M, the first million-scale multimodal agent tuning dataset designed to support CoT, reflection, and dynamic tool usage. Our dataset is constructed through a novel four-stage data engine: 1) We first curate publicly available multimodal datasets containing question-answer pairs; 2) Then, leveraging GPT-4o, we generate rationales for the original question-answer pairs and dynamically integrate API calls and Retrieval Augmented Generation (RAG) information through a multi-turn paradigm; 3) Furthermore, we refine the rationales through reflection to ensure logical consistency and accuracy, creating a multi-turn dialogue dataset with both Rationale and Reflection (RR); 4) Finally, to enhance efficiency, we optionally compress multi-turn dialogues into a One-turn Rationale and Reflection (ORR) format. By fine-tuning open-source multimodal models on the MMAT-1M, we observe significant performance gains. For instance, the InternVL2.5-8B-RR model achieves an average improvement of 2.7% across eight public benchmarks and 8.8% on the RAG benchmark Dyn-VQA, demonstrating the dataset's effectiveness in enhancing multimodal reasoning and tool-based capabilities. The dataset is publicly available at https://github.com/VIS-MPU-Agent/MMAT-1M.
Interpretable Face Anti-Spoofing: Enhancing Generalization with Multimodal Large Language Models
Jan 03, 2025



Face Anti-Spoofing (FAS) is essential for ensuring the security and reliability of facial recognition systems. Most existing FAS methods are formulated as binary classification tasks, providing confidence scores without interpretation. They exhibit limited generalization in out-of-domain scenarios, such as new environments or unseen spoofing types. In this work, we introduce a multimodal large language model (MLLM) framework for FAS, termed Interpretable Face Anti-Spoofing (I-FAS), which transforms the FAS task into an interpretable visual question answering (VQA) paradigm. Specifically, we propose a Spoof-aware Captioning and Filtering (SCF) strategy to generate high-quality captions for FAS images, enriching the model's supervision with natural language interpretations. To mitigate the impact of noisy captions during training, we develop a Lopsided Language Model (L-LM) loss function that separates loss calculations for judgment and interpretation, prioritizing the optimization of the former. Furthermore, to enhance the model's perception of global visual features, we design a Globally Aware Connector (GAC) to align multi-level visual representations with the language model. Extensive experiments on standard and newly devised One to Eleven cross-domain benchmarks, comprising 12 public datasets, demonstrate that our method significantly outperforms state-of-the-art methods.
ALoRE: Efficient Visual Adaptation via Aggregating Low Rank Experts
Dec 11, 2024



Parameter-efficient transfer learning (PETL) has become a promising paradigm for adapting large-scale vision foundation models to downstream tasks. Typical methods primarily leverage the intrinsic low rank property to make decomposition, learning task-specific weights while compressing parameter size. However, such approaches predominantly manipulate within the original feature space utilizing a single-branch structure, which might be suboptimal for decoupling the learned representations and patterns. In this paper, we propose ALoRE, a novel PETL method that reuses the hypercomplex parameterized space constructed by Kronecker product to Aggregate Low Rank Experts using a multi-branch paradigm, disentangling the learned cognitive patterns during training. Thanks to the artful design, ALoRE maintains negligible extra parameters and can be effortlessly merged into the frozen backbone via re-parameterization in a sequential manner, avoiding additional inference latency. We conduct extensive experiments on 24 image classification tasks using various backbone variants. Experimental results demonstrate that ALoRE outperforms the full fine-tuning strategy and other state-of-the-art PETL methods in terms of performance and parameter efficiency. For instance, ALoRE obtains 3.06% and 9.97% Top-1 accuracy improvement on average compared to full fine-tuning on the FGVC datasets and VTAB-1k benchmark by only updating 0.15M parameters.
Cyclically Disentangled Feature Translation for Face Anti-spoofing
Dec 07, 2022



Current domain adaptation methods for face anti-spoofing leverage labeled source domain data and unlabeled target domain data to obtain a promising generalizable decision boundary. However, it is usually difficult for these methods to achieve a perfect domain-invariant liveness feature disentanglement, which may degrade the final classification performance by domain differences in illumination, face category, spoof type, etc. In this work, we tackle cross-scenario face anti-spoofing by proposing a novel domain adaptation method called cyclically disentangled feature translation network (CDFTN). Specifically, CDFTN generates pseudo-labeled samples that possess: 1) source domain-invariant liveness features and 2) target domain-specific content features, which are disentangled through domain adversarial training. A robust classifier is trained based on the synthetic pseudo-labeled images under the supervision of source domain labels. We further extend CDFTN for multi-target domain adaptation by leveraging data from more unlabeled target domains. Extensive experiments on several public datasets demonstrate that our proposed approach significantly outperforms the state of the art.
ForgeryNet -- Face Forgery Analysis Challenge 2021: Methods and Results
Dec 15, 2021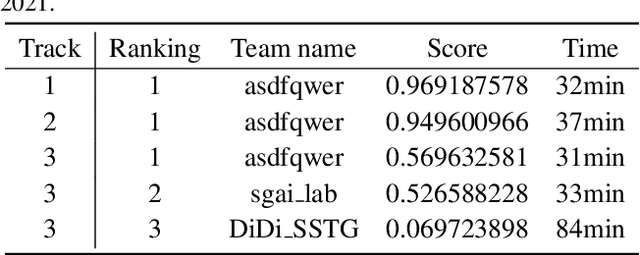
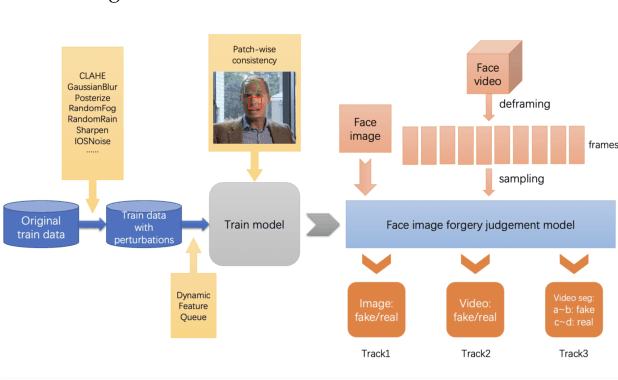
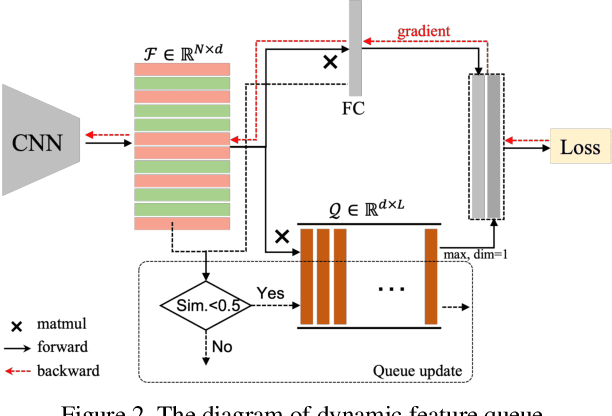
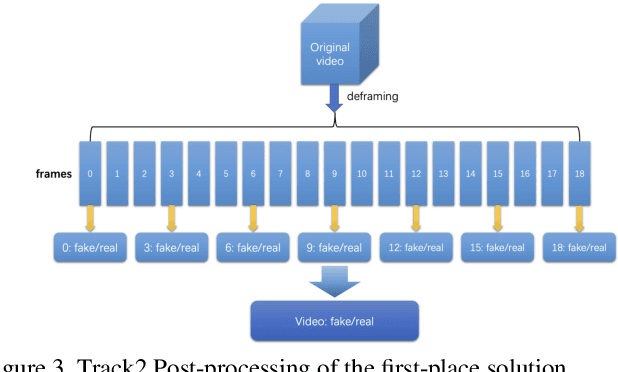
The rapid progress of photorealistic synthesis techniques has reached a critical point where the boundary between real and manipulated images starts to blur. Recently, a mega-scale deep face forgery dataset, ForgeryNet which comprised of 2.9 million images and 221,247 videos has been released. It is by far the largest publicly available in terms of data-scale, manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations), and annotations (6.3 million classification labels, 2.9 million manipulated area annotations, and 221,247 temporal forgery segment labels). This paper reports methods and results in the ForgeryNet - Face Forgery Analysis Challenge 2021, which employs the ForgeryNet benchmark. The model evaluation is conducted offline on the private test set. A total of 186 participants registered for the competition, and 11 teams made valid submissions. We will analyze the top-ranked solutions and present some discussion on future work directions.
Learning Generalized Spoof Cues for Face Anti-spoofing
May 08, 2020
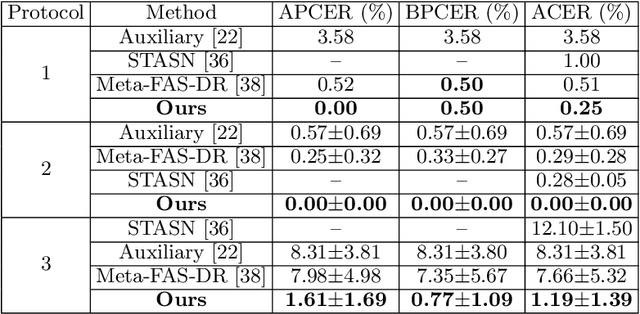
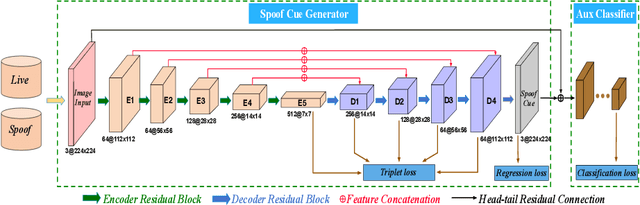
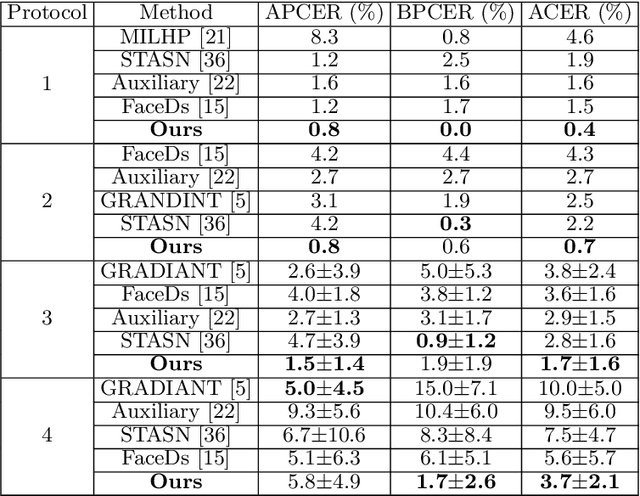
Many existing face anti-spoofing (FAS) methods focus on modeling the decision boundaries for some predefined spoof types. However, the diversity of the spoof samples including the unknown ones hinders the effective decision boundary modeling and leads to weak generalization capability. In this paper, we reformulate FAS in an anomaly detection perspective and propose a residual-learning framework to learn the discriminative live-spoof differences which are defined as the spoof cues. The proposed framework consists of a spoof cue generator and an auxiliary classifier. The generator minimizes the spoof cues of live samples while imposes no explicit constraint on those of spoof samples to generalize well to unseen attacks. In this way, anomaly detection is implicitly used to guide spoof cue generation, leading to discriminative feature learning. The auxiliary classifier serves as a spoof cue amplifier and makes the spoof cues more discriminative. We conduct extensive experiments and the experimental results show the proposed method consistently outperforms the state-of-the-art methods. The code will be publicly available at https://github.com/vis-var/lgsc-for-fas.