 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSattiy at SemEval-2021 Task 9: An Ensemble Solution for Statement Verification and Evidence Finding with Tables
Apr 21, 2021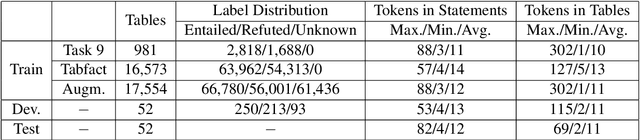
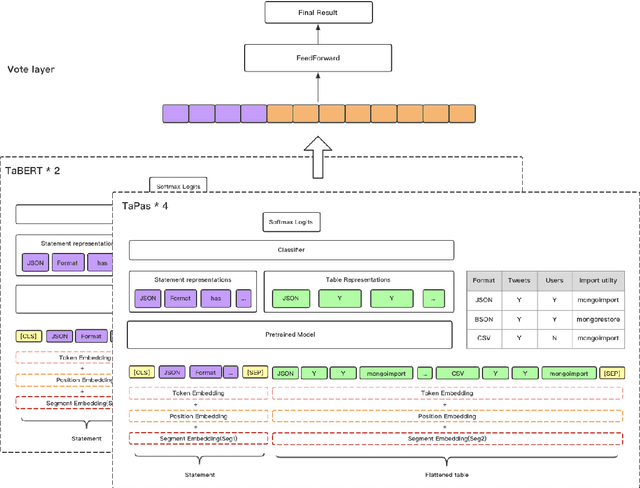
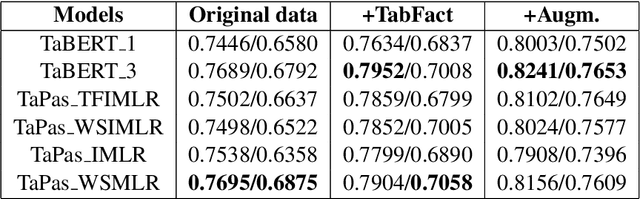
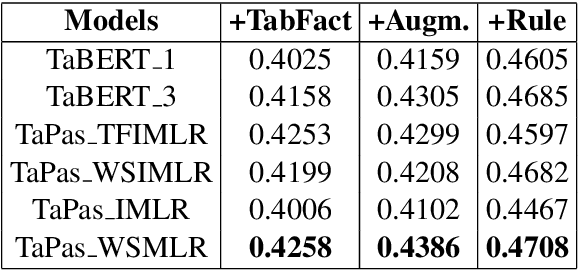
Question answering from semi-structured tables can be seen as a semantic parsing task and is significant and practical for pushing the boundary of natural language understanding. Existing research mainly focuses on understanding contents from unstructured evidence, e.g., news, natural language sentences, and documents. The task of verification from structured evidence, such as tables, charts, and databases, is still less explored. This paper describes sattiy team's system in SemEval-2021 task 9: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACT). This competition aims to verify statements and to find evidence from tables for scientific articles and to promote the proper interpretation of the surrounding article. In this paper, we exploited ensemble models of pre-trained language models over tables, TaPas and TaBERT, for Task A and adjust the result based on some rules extracted for Task B. Finally, in the leaderboard, we attain the F1 scores of 0.8496 and 0.7732 in Task A for the 2-way and 3-way evaluation, respectively, and the F1 score of 0.4856 in Task B.
MagicPai at SemEval-2021 Task 7: Method for Detecting and Rating Humor Based on Multi-Task Adversarial Training
Apr 21, 2021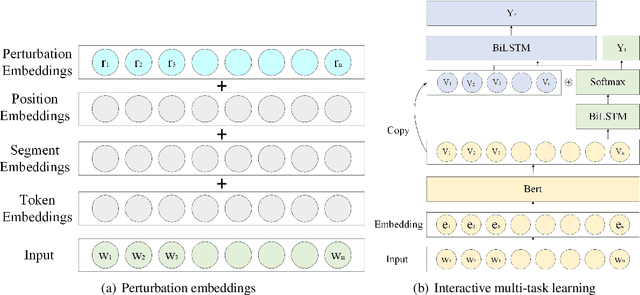
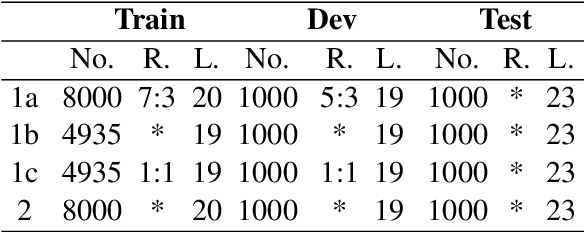
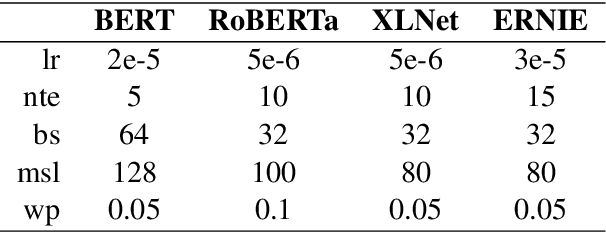
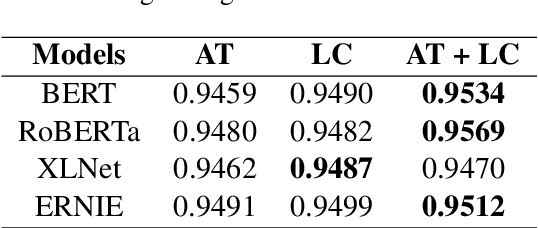
This paper describes MagicPai's system for SemEval 2021 Task 7, HaHackathon: Detecting and Rating Humor and Offense. This task aims to detect whether the text is humorous and how humorous it is. There are four subtasks in the competition. In this paper, we mainly present our solution, a multi-task learning model based on adversarial examples, for task 1a and 1b. More specifically, we first vectorize the cleaned dataset and add the perturbation to obtain more robust embedding representations. We then correct the loss via the confidence level. Finally, we perform interactive joint learning on multiple tasks to capture the relationship between whether the text is humorous and how humorous it is. The final result shows the effectiveness of our system.
* 7 pages, 1 figure, 4 tables