 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALI at SemEval-2021 Task 2: Fine-Tune XLM-RoBERTa for Word in Context Disambiguation
Paper and Code


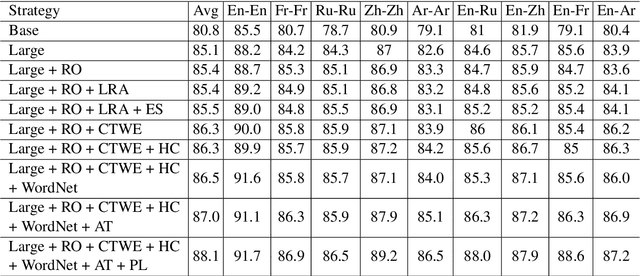
This paper presents the PALI team's winning system for SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation. We fine-tune XLM-RoBERTa model to solve the task of word in context disambiguation, i.e., to determine whether the target word in the two contexts contains the same meaning or not. In the implementation, we first specifically design an input tag to emphasize the target word in the contexts. Second, we construct a new vector on the fine-tuned embeddings from XLM-RoBERTa and feed it to a fully-connected network to output the probability of whether the target word in the context has the same meaning or not. The new vector is attained by concatenating the embedding of the [CLS] token and the embeddings of the target word in the contexts. In training, we explore several tricks, such as the Ranger optimizer, data augmentation, and adversarial training, to improve the model prediction. Consequently, we attain first place in all four cross-lingual tasks.