 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust, Don't Trust, or Flip: Robust Preference-Based Reinforcement Learning with Multi-Expert Feedback
Jan 26, 2026Preference-based reinforcement learning (PBRL) offers a promising alternative to explicit reward engineering by learning from pairwise trajectory comparisons. However, real-world preference data often comes from heterogeneous annotators with varying reliability; some accurate, some noisy, and some systematically adversarial. Existing PBRL methods either treat all feedback equally or attempt to filter out unreliable sources, but both approaches fail when faced with adversarial annotators who systematically provide incorrect preferences. We introduce TriTrust-PBRL (TTP), a unified framework that jointly learns a shared reward model and expert-specific trust parameters from multi-expert preference feedback. The key insight is that trust parameters naturally evolve during gradient-based optimization to be positive (trust), near zero (ignore), or negative (flip), enabling the model to automatically invert adversarial preferences and recover useful signal rather than merely discarding corrupted feedback. We provide theoretical analysis establishing identifiability guarantees and detailed gradient analysis that explains how expert separation emerges naturally during training without explicit supervision. Empirically, we evaluate TTP on four diverse domains spanning manipulation tasks (MetaWorld) and locomotion (DM Control) under various corruption scenarios. TTP achieves state-of-the-art robustness, maintaining near-oracle performance under adversarial corruption while standard PBRL methods fail catastrophically. Notably, TTP outperforms existing baselines by successfully learning from mixed expert pools containing both reliable and adversarial annotators, all while requiring no expert features beyond identification indices and integrating seamlessly with existing PBRL pipelines.
Where Do You Go? Pedestrian Trajectory Prediction using Scene Features
Jan 23, 2025
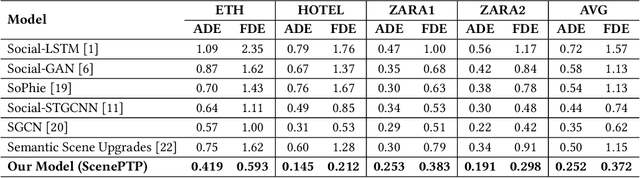
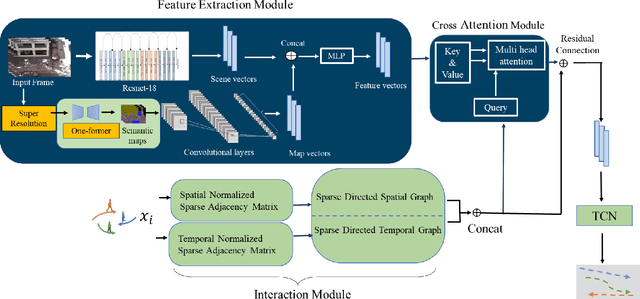

Accurate prediction of pedestrian trajectories is crucial for enhancing the safety of autonomous vehicles and reducing traffic fatalities involving pedestrians. While numerous studies have focused on modeling interactions among pedestrians to forecast their movements, the influence of environmental factors and scene-object placements has been comparatively underexplored. In this paper, we present a novel trajectory prediction model that integrates both pedestrian interactions and environmental context to improve prediction accuracy. Our approach captures spatial and temporal interactions among pedestrians within a sparse graph framework. To account for pedestrian-scene interactions, we employ advanced image enhancement and semantic segmentation techniques to extract detailed scene features. These scene and interaction features are then fused through a cross-attention mechanism, enabling the model to prioritize relevant environmental factors that influence pedestrian movements. Finally, a temporal convolutional network processes the fused features to predict future pedestrian trajectories. Experimental results demonstrate that our method significantly outperforms existing state-of-the-art approaches, achieving ADE and FDE values of 0.252 and 0.372 meters, respectively, underscoring the importance of incorporating both social interactions and environmental context in pedestrian trajectory prediction.
Neural Error Covariance Estimation for Precise LiDAR Localization
Jan 05, 2025Autonomous vehicles have gained significant attention due to technological advancements and their potential to transform transportation. A critical challenge in this domain is precise localization, particularly in LiDAR-based map matching, which is prone to errors due to degeneracy in the data. Most sensor fusion techniques, such as the Kalman filter, rely on accurate error covariance estimates for each sensor to improve localization accuracy. However, obtaining reliable covariance values for map matching remains a complex task. To address this challenge, we propose a neural network-based framework for predicting localization error covariance in LiDAR map matching. To achieve this, we introduce a novel dataset generation method specifically designed for error covariance estimation. In our evaluation using a Kalman filter, we achieved a 2 cm improvement in localization accuracy, a significant enhancement in this domain.
LiDAR-Camera Fusion for Video Panoptic Segmentation without Video Training
Dec 30, 2024



Panoptic segmentation, which combines instance and semantic segmentation, has gained a lot of attention in autonomous vehicles, due to its comprehensive representation of the scene. This task can be applied for cameras and LiDAR sensors, but there has been a limited focus on combining both sensors to enhance image panoptic segmentation (PS). Although previous research has acknowledged the benefit of 3D data on camera-based scene perception, no specific study has explored the influence of 3D data on image and video panoptic segmentation (VPS).This work seeks to introduce a feature fusion module that enhances PS and VPS by fusing LiDAR and image data for autonomous vehicles. We also illustrate that, in addition to this fusion, our proposed model, which utilizes two simple modifications, can further deliver even more high-quality VPS without being trained on video data. The results demonstrate a substantial improvement in both the image and video panoptic segmentation evaluation metrics by up to 5 points.
Identity-preserving Editing of Multiple Facial Attributes by Learning Global Edit Directions and Local Adjustments
Sep 25, 2023



Semantic facial attribute editing using pre-trained Generative Adversarial Networks (GANs) has attracted a great deal of attention and effort from researchers in recent years. Due to the high quality of face images generated by StyleGANs, much work has focused on the StyleGANs' latent space and the proposed methods for facial image editing. Although these methods have achieved satisfying results for manipulating user-intended attributes, they have not fulfilled the goal of preserving the identity, which is an important challenge. We present ID-Style, a new architecture capable of addressing the problem of identity loss during attribute manipulation. The key components of ID-Style include Learnable Global Direction (LGD), which finds a shared and semi-sparse direction for each attribute, and an Instance-Aware Intensity Predictor (IAIP) network, which finetunes the global direction according to the input instance. Furthermore, we introduce two losses during training to enforce the LGD to find semi-sparse semantic directions, which along with the IAIP, preserve the identity of the input instance. Despite reducing the size of the network by roughly 95% as compared to similar state-of-the-art works, it outperforms baselines by 10% and 7% in Identity preserving metric (FRS) and average accuracy of manipulation (mACC), respectively.