 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Real-World Autonomous Racing via Attenuated Residual Policy Optimization
Mar 13, 2026Residual policy learning (RPL), in which a learned policy refines a static base policy using deep reinforcement learning (DRL), has shown strong performance across various robotic applications. Its effectiveness is particularly evident in autonomous racing, a domain that serves as a challenging benchmark for real-world DRL. However, deploying RPL-based controllers introduces system complexity and increases inference latency. We address this by introducing an extension of RPL named attenuated residual policy optimization ($α$-RPO). Unlike standard RPL, $α$-RPO yields a standalone neural policy by progressively attenuating the base policy, which initially serves to bootstrap learning. Furthermore, this mechanism enables a form of privileged learning, where the base policy is permitted to use sensor modalities not required for final deployment. We design $α$-RPO to integrate seamlessly with PPO, ensuring that the attenuated influence of the base controller is dynamically compensated during policy optimization. We evaluate $α$-RPO by building a framework for 1:10-scaled autonomous racing around it. In both simulation and zero-shot real-world transfer to Roboracer cars, $α$-RPO not only reduces system complexity but also improves driving performance compared to baselines - demonstrating its practicality for robotic deployment. Our code is available at: https://github.com/raphajaner/arpo_racing.
Continuous World Coverage Path Planning for Fixed-Wing UAVs using Deep Reinforcement Learning
May 13, 2025Unmanned Aerial Vehicle (UAV) Coverage Path Planning (CPP) is critical for applications such as precision agriculture and search and rescue. While traditional methods rely on discrete grid-based representations, real-world UAV operations require power-efficient continuous motion planning. We formulate the UAV CPP problem in a continuous environment, minimizing power consumption while ensuring complete coverage. Our approach models the environment with variable-size axis-aligned rectangles and UAV motion with curvature-constrained B\'ezier curves. We train a reinforcement learning agent using an action-mapping-based Soft Actor-Critic (AM-SAC) algorithm employing a self-adaptive curriculum. Experiments on both procedurally generated and hand-crafted scenarios demonstrate the effectiveness of our method in learning energy-efficient coverage strategies.
Impoola: The Power of Average Pooling for Image-Based Deep Reinforcement Learning
Mar 07, 2025



As image-based deep reinforcement learning tackles more challenging tasks, increasing model size has become an important factor in improving performance. Recent studies achieved this by focusing on the parameter efficiency of scaled networks, typically using Impala-CNN, a 15-layer ResNet-inspired network, as the image encoder. However, while Impala-CNN evidently outperforms older CNN architectures, potential advancements in network design for deep reinforcement learning-specific image encoders remain largely unexplored. We find that replacing the flattening of output feature maps in Impala-CNN with global average pooling leads to a notable performance improvement. This approach outperforms larger and more complex models in the Procgen Benchmark, particularly in terms of generalization. We call our proposed encoder model Impoola-CNN. A decrease in the network's translation sensitivity may be central to this improvement, as we observe the most significant gains in games without agent-centered observations. Our results demonstrate that network scaling is not just about increasing model size - efficient network design is also an essential factor.
Action Mapping for Reinforcement Learning in Continuous Environments with Constraints
Dec 05, 2024



Deep reinforcement learning (DRL) has had success across various domains, but applying it to environments with constraints remains challenging due to poor sample efficiency and slow convergence. Recent literature explored incorporating model knowledge to mitigate these problems, particularly through the use of models that assess the feasibility of proposed actions. However, integrating feasibility models efficiently into DRL pipelines in environments with continuous action spaces is non-trivial. We propose a novel DRL training strategy utilizing action mapping that leverages feasibility models to streamline the learning process. By decoupling the learning of feasible actions from policy optimization, action mapping allows DRL agents to focus on selecting the optimal action from a reduced feasible action set. We demonstrate through experiments that action mapping significantly improves training performance in constrained environments with continuous action spaces, especially with imperfect feasibility models.
Equivariant Ensembles and Regularization for Reinforcement Learning in Map-based Path Planning
Mar 19, 2024



In reinforcement learning (RL), exploiting environmental symmetries can significantly enhance efficiency, robustness, and performance. However, ensuring that the deep RL policy and value networks are respectively equivariant and invariant to exploit these symmetries is a substantial challenge. Related works try to design networks that are equivariant and invariant by construction, limiting them to a very restricted library of components, which in turn hampers the expressiveness of the networks. This paper proposes a method to construct equivariant policies and invariant value functions without specialized neural network components, which we term equivariant ensembles. We further add a regularization term for adding inductive bias during training. In a map-based path planning case study, we show how equivariant ensembles and regularization benefit sample efficiency and performance.
Learning to Recharge: UAV Coverage Path Planning through Deep Reinforcement Learning
Sep 07, 2023



Coverage path planning (CPP) is a critical problem in robotics, where the goal is to find an efficient path that covers every point in an area of interest. This work addresses the power-constrained CPP problem with recharge for battery-limited unmanned aerial vehicles (UAVs). In this problem, a notable challenge emerges from integrating recharge journeys into the overall coverage strategy, highlighting the intricate task of making strategic, long-term decisions. We propose a novel proximal policy optimization (PPO)-based deep reinforcement learning (DRL) approach with map-based observations, utilizing action masking and discount factor scheduling to optimize coverage trajectories over the entire mission horizon. We further provide the agent with a position history to handle emergent state loops caused by the recharge capability. Our approach outperforms a baseline heuristic, generalizes to different target zones and maps, with limited generalization to unseen maps. We offer valuable insights into DRL algorithm design for long-horizon problems and provide a publicly available software framework for the CPP problem.
Edge Generation Scheduling for DAG Tasks using Deep Reinforcement Learning
Aug 28, 2023



Directed acyclic graph (DAG) tasks are currently adopted in the real-time domain to model complex applications from the automotive, avionics, and industrial domain that implement their functionalities through chains of intercommunicating tasks. This paper studies the problem of scheduling real-time DAG tasks by presenting a novel schedulability test based on the concept of trivial schedulability. Using this schedulability test, we propose a new DAG scheduling framework (edge generation scheduling -- EGS) that attempts to minimize the DAG width by iteratively generating edges while guaranteeing the deadline constraint. We study how to efficiently solve the problem of generating edges by developing a deep reinforcement learning algorithm combined with a graph representation neural network to learn an efficient edge generation policy for EGS. We evaluate the effectiveness of the proposed algorithm by comparing it with state-of-the-art DAG scheduling heuristics and an optimal mixed-integer linear programming baseline. Experimental results show that the proposed algorithm outperforms the state-of-the-art by requiring fewer processors to schedule the same DAG tasks.
Learning to Generate All Feasible Actions
Jan 26, 2023



Several machine learning (ML) applications are characterized by searching for an optimal solution to a complex task. The search space for this optimal solution is often very large, so large in fact that this optimal solution is often not computable. Part of the problem is that many candidate solutions found via ML are actually infeasible and have to be discarded. Restricting the search space to only the feasible solution candidates simplifies finding an optimal solution for the tasks. Further, the set of feasible solutions could be re-used in multiple problems characterized by different tasks. In particular, we observe that complex tasks can be decomposed into subtasks and corresponding skills. We propose to learn a reusable and transferable skill by training an actor to generate all feasible actions. The trained actor can then propose feasible actions, among which an optimal one can be chosen according to a specific task. The actor is trained by interpreting the feasibility of each action as a target distribution. The training procedure minimizes a divergence of the actor's output distribution to this target. We derive the general optimization target for arbitrary f-divergences using a combination of kernel density estimates, resampling, and importance sampling. We further utilize an auxiliary critic to reduce the interactions with the environment. A preliminary comparison to related strategies shows that our approach learns to visit all the modes in the feasible action space, demonstrating the framework's potential for learning skills that can be used in various downstream tasks.
Cloud-Edge Training Architecture for Sim-to-Real Deep Reinforcement Learning
Mar 04, 2022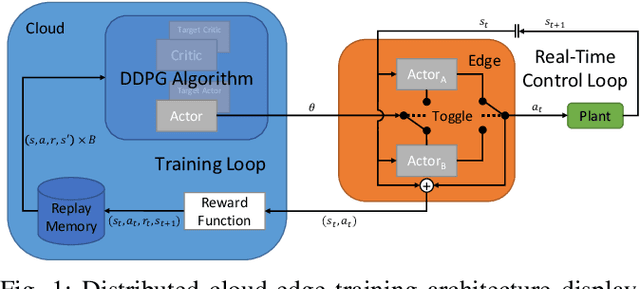
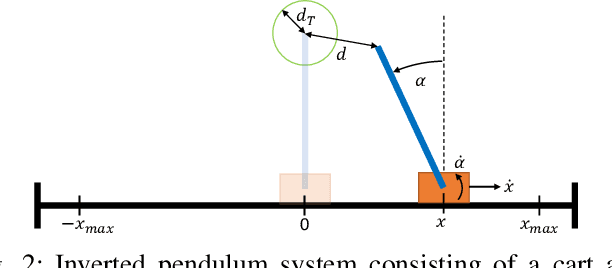
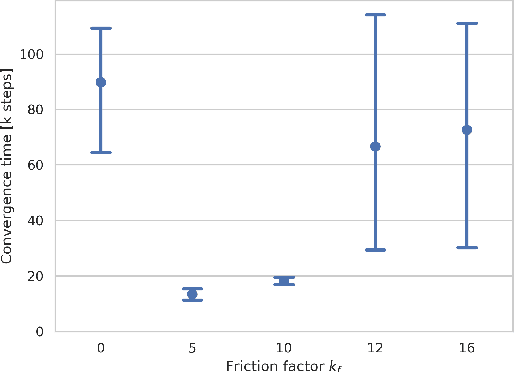
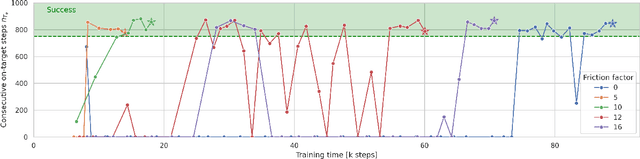
Deep reinforcement learning (DRL) is a promising approach to solve complex control tasks by learning policies through interactions with the environment. However, the training of DRL policies requires large amounts of training experiences, making it impractical to learn the policy directly on physical systems. Sim-to-real approaches leverage simulations to pretrain DRL policies and then deploy them in the real world. Unfortunately, the direct real-world deployment of pretrained policies usually suffers from performance deterioration due to the different dynamics, known as the reality gap. Recent sim-to-real methods, such as domain randomization and domain adaptation, focus on improving the robustness of the pretrained agents. Nevertheless, the simulation-trained policies often need to be tuned with real-world data to reach optimal performance, which is challenging due to the high cost of real-world samples. This work proposes a distributed cloud-edge architecture to train DRL agents in the real world in real-time. In the architecture, the inference and training are assigned to the edge and cloud, separating the real-time control loop from the computationally expensive training loop. To overcome the reality gap, our architecture exploits sim-to-real transfer strategies to continue the training of simulation-pretrained agents on a physical system. We demonstrate its applicability on a physical inverted-pendulum control system, analyzing critical parameters. The real-world experiments show that our architecture can adapt the pretrained DRL agents to unseen dynamics consistently and efficiently.
Multi-Agent Belief Sharing through Autonomous Hierarchical Multi-Level Clustering
Jul 21, 2021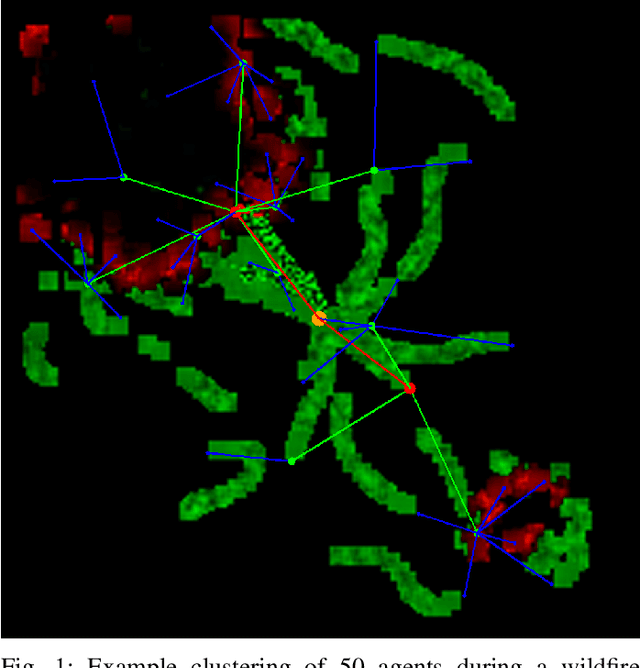

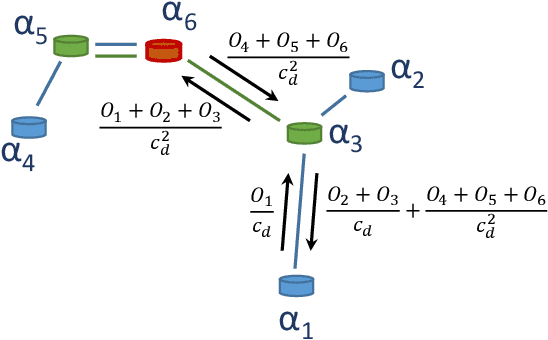
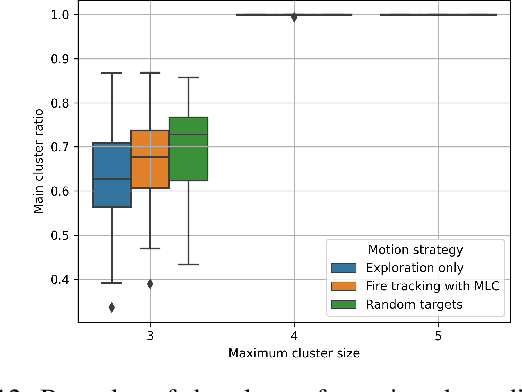
Coordination in multi-agent systems is challenging for agile robots such as unmanned aerial vehicles (UAVs), where relative agent positions frequently change due to unconstrained movement. The problem is exacerbated through the individual take-off and landing of agents for battery recharging leading to a varying number of active agents throughout the whole mission. This work proposes autonomous hierarchical multi-level clustering (MLC), which forms a clustering hierarchy utilizing decentralized methods. Through periodic cluster maintenance executed by cluster-heads, stable multi-level clustering is achieved. The resulting hierarchy is used as a backbone to solve the communication problem for locally-interactive applications such as UAV tracking problems. Using observation aggregation, compression, and dissemination, agents share local observations throughout the hierarchy, giving every agent a total system belief with spatially dependent resolution and freshness. Extensive simulations show that MLC yields a stable cluster hierarchy under different motion patterns and that the proposed belief sharing is highly applicable in wildfire front monitoring scenarios.