 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV Path Planning using Global and Local Map Information with Deep Reinforcement Learning
Nov 02, 2020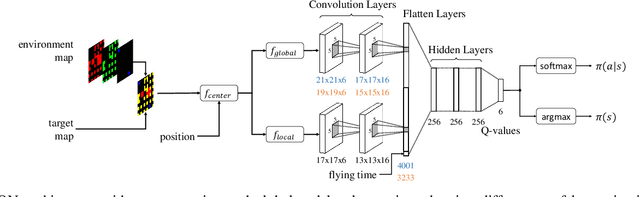
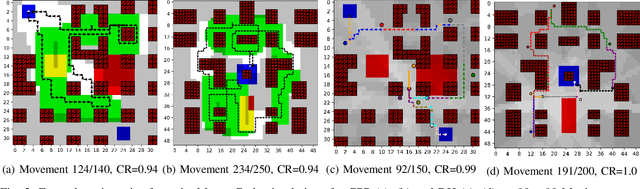
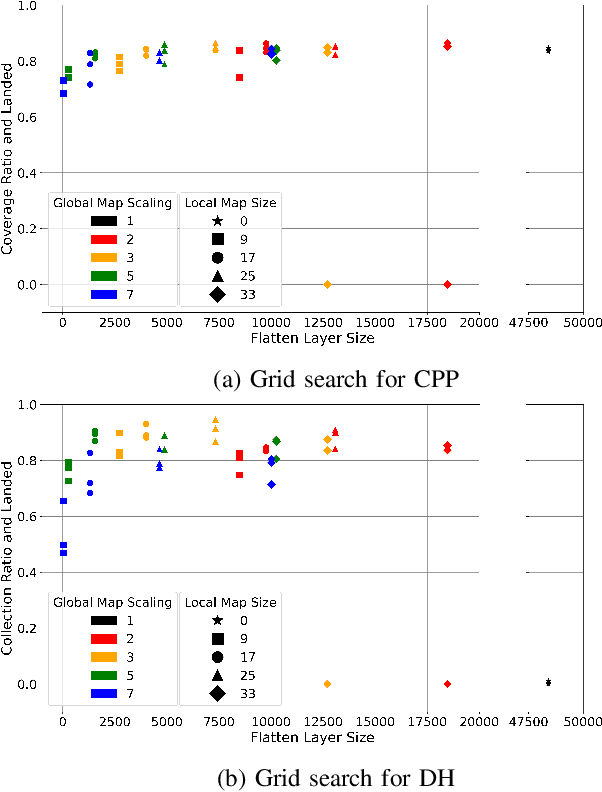
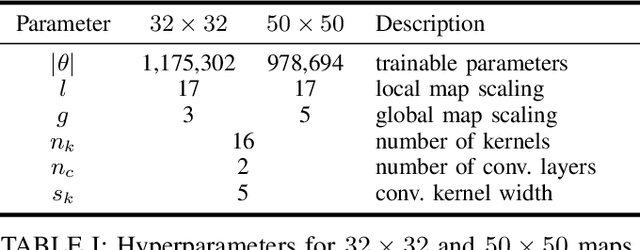
Path planning methods for autonomous unmanned aerial vehicles (UAVs) are typically designed for one specific type of mission. In this work, we present a method for autonomous UAV path planning based on deep reinforcement learning (DRL) that can be applied to a wide range of mission scenarios. Specifically, we compare coverage path planning (CPP), where the UAV's goal is to survey an area of interest to data harvesting (DH), where the UAV collects data from distributed Internet of Things (IoT) sensor devices. By exploiting structured map information of the environment, we train double deep Q-networks (DDQNs) with identical architectures on both distinctly different mission scenarios, to make movement decisions that balance the respective mission goal with navigation constraints. By introducing a novel approach exploiting a compressed global map of the environment combined with a cropped but uncompressed local map showing the vicinity of the UAV agent, we demonstrate that the proposed method can efficiently scale to large environments. We also extend previous results for generalizing control policies that require no retraining when scenario parameters change and offer a detailed analysis of crucial map processing parameters' effects on path planning performance.
UAV Coverage Path Planning under Varying Power Constraints using Deep Reinforcement Learning
Mar 05, 2020



Coverage path planning (CPP) is the task of designing a trajectory that enables a mobile agent to travel over every point of an area of interest. We propose a new method to control an unmanned aerial vehicle (UAV) carrying a camera on a CPP mission with random start positions and multiple options for landing positions in an environment containing no-fly zones. While numerous approaches have been proposed to solve similar CPP problems, we leverage end-to-end reinforcement learning (RL) to learn a control policy that generalizes over varying power constraints for the UAV. Despite recent improvements in battery technology, the maximum flying range of small UAVs is still a severe constraint, which is exacerbated by variations in the UAV's power consumption that are hard to predict. By using map-like input channels to feed spatial information through convolutional network layers to the agent, we are able to train a double deep Q-network (DDQN) to make control decisions for the UAV, balancing limited power budget and coverage goal. The proposed method can be applied to a wide variety of environments and harmonizes complex goal structures with system constraints.