 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-model-guided Worst-case Sampling for Safe Reinforcement Learning
Dec 17, 2024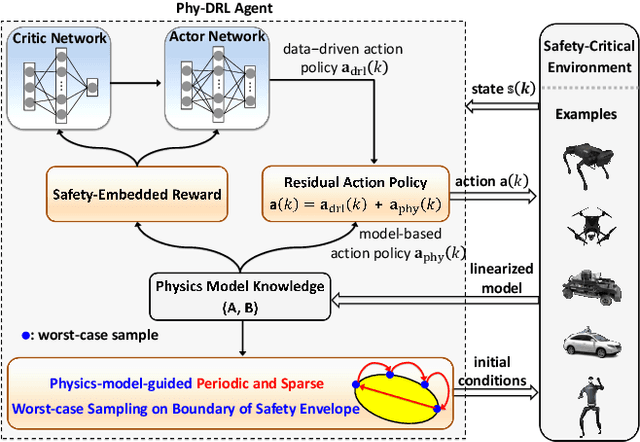

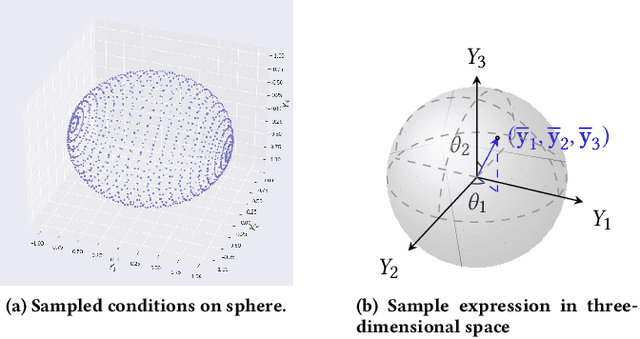
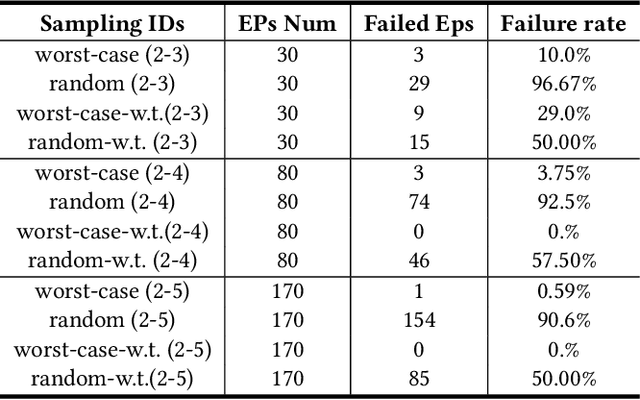
Real-world accidents in learning-enabled CPS frequently occur in challenging corner cases. During the training of deep reinforcement learning (DRL) policy, the standard setup for training conditions is either fixed at a single initial condition or uniformly sampled from the admissible state space. This setup often overlooks the challenging but safety-critical corner cases. To bridge this gap, this paper proposes a physics-model-guided worst-case sampling strategy for training safe policies that can handle safety-critical cases toward guaranteed safety. Furthermore, we integrate the proposed worst-case sampling strategy into the physics-regulated deep reinforcement learning (Phy-DRL) framework to build a more data-efficient and safe learning algorithm for safety-critical CPS. We validate the proposed training strategy with Phy-DRL through extensive experiments on a simulated cart-pole system, a 2D quadrotor, a simulated and a real quadruped robot, showing remarkably improved sampling efficiency to learn more robust safe policies.
Simplex-enabled Safe Continual Learning Machine
Sep 05, 2024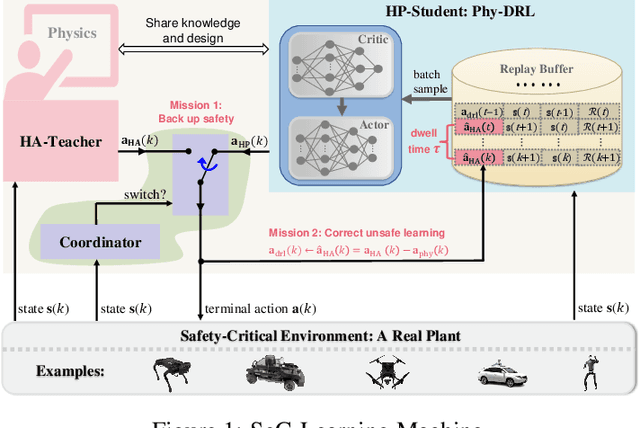

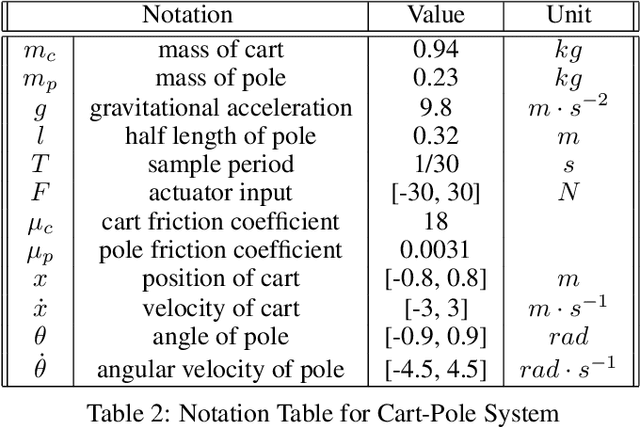
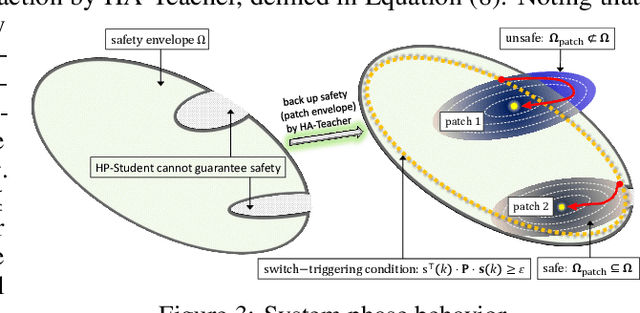
This paper proposes the SeC-Learning Machine: Simplex-enabled safe continual learning for safety-critical autonomous systems. The SeC-learning machine is built on Simplex logic (that is, ``using simplicity to control complexity'') and physics-regulated deep reinforcement learning (Phy-DRL). The SeC-learning machine thus constitutes HP (high performance)-Student, HA (high assurance)-Teacher, and Coordinator. Specifically, the HP-Student is a pre-trained high-performance but not fully verified Phy-DRL, continuing to learn in a real plant to tune the action policy to be safe. In contrast, the HA-Teacher is a mission-reduced, physics-model-based, and verified design. As a complementary, HA-Teacher has two missions: backing up safety and correcting unsafe learning. The Coordinator triggers the interaction and the switch between HP-Student and HA-Teacher. Powered by the three interactive components, the SeC-learning machine can i) assure lifetime safety (i.e., safety guarantee in any continual-learning stage, regardless of HP-Student's success or convergence), ii) address the Sim2Real gap, and iii) learn to tolerate unknown unknowns in real plants. The experiments on a cart-pole system and a real quadruped robot demonstrate the distinguished features of the SeC-learning machine, compared with continual learning built on state-of-the-art safe DRL frameworks with approaches to addressing the Sim2Real gap.
Equivariant Ensembles and Regularization for Reinforcement Learning in Map-based Path Planning
Mar 19, 2024



In reinforcement learning (RL), exploiting environmental symmetries can significantly enhance efficiency, robustness, and performance. However, ensuring that the deep RL policy and value networks are respectively equivariant and invariant to exploit these symmetries is a substantial challenge. Related works try to design networks that are equivariant and invariant by construction, limiting them to a very restricted library of components, which in turn hampers the expressiveness of the networks. This paper proposes a method to construct equivariant policies and invariant value functions without specialized neural network components, which we term equivariant ensembles. We further add a regularization term for adding inductive bias during training. In a map-based path planning case study, we show how equivariant ensembles and regularization benefit sample efficiency and performance.
Physical Deep Reinforcement Learning: Safety and Unknown Unknowns
May 26, 2023
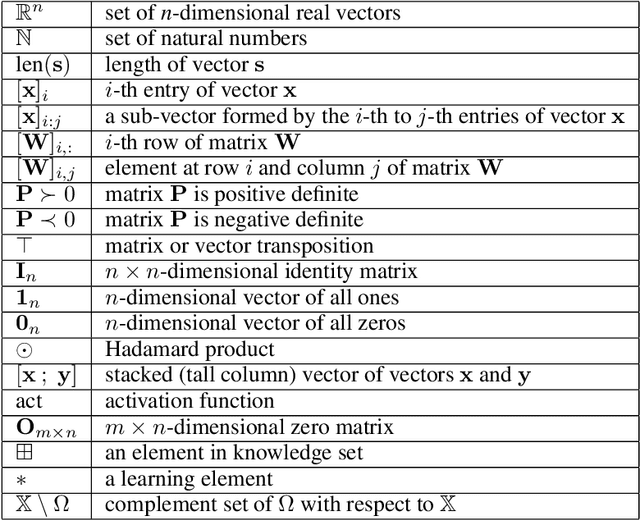
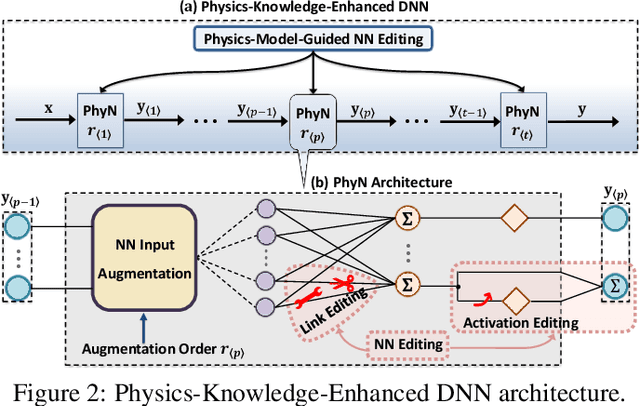

In this paper, we propose the Phy-DRL: a physics-model-regulated deep reinforcement learning framework for safety-critical autonomous systems. The Phy-DRL is unique in three innovations: i) proactive unknown-unknowns training, ii) conjunctive residual control (i.e., integration of data-driven control and physics-model-based control) and safety- \& stability-sensitive reward, and iii) physics-model-based neural network editing, including link editing and activation editing. Thanks to the concurrent designs, the Phy-DRL is able to 1) tolerate unknown-unknowns disturbances, 2) guarantee mathematically provable safety and stability, and 3) strictly comply with physical knowledge pertaining to Bellman equation and reward. The effectiveness of the Phy-DRL is finally validated by an inverted pendulum and a quadruped robot. The experimental results demonstrate that compared with purely data-driven DRL, Phy-DRL features remarkably fewer learning parameters, accelerated training and enlarged reward, while offering enhanced model robustness and safety assurance.
Physical Deep Reinforcement Learning Towards Safety Guarantee
Mar 29, 2023Deep reinforcement learning (DRL) has achieved tremendous success in many complex decision-making tasks of autonomous systems with high-dimensional state and/or action spaces. However, the safety and stability still remain major concerns that hinder the applications of DRL to safety-critical autonomous systems. To address the concerns, we proposed the Phy-DRL: a physical deep reinforcement learning framework. The Phy-DRL is novel in two architectural designs: i) Lyapunov-like reward, and ii) residual control (i.e., integration of physics-model-based control and data-driven control). The concurrent physical reward and residual control empower the Phy-DRL the (mathematically) provable safety and stability guarantees. Through experiments on the inverted pendulum, we show that the Phy-DRL features guaranteed safety and stability and enhanced robustness, while offering remarkably accelerated training and enlarged reward.
Flexible Gear Assembly With Visual Servoing and Force Feedback
Mar 06, 2023
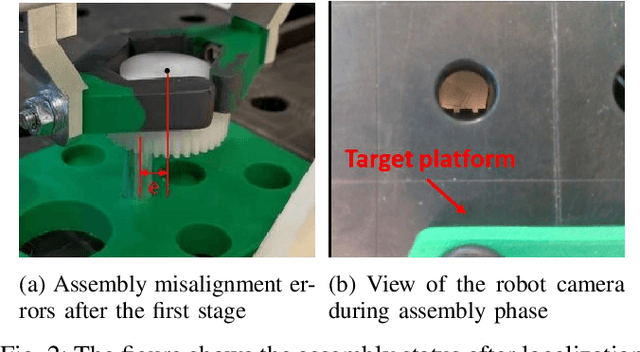


Gear assembly is an essential but challenging task in industrial automation. This paper presents a novel two-stage approach for achieving high-precision and flexible gear assembly. The proposed approach integrates YOLO to coarsely localize the workpiece in a searching phase and deep reinforcement learning (DRL) to complete the insertion. Specifically, DRL addresses the challenge of partial visibility when the on-wrist camera is too close to the workpiece. Additionally, force feedback is used to smoothly transit the process from the first phase to the second phase. To reduce the data collection effort for training deep neural networks, we use synthetic RGB images for training YOLO and construct an offline interaction environment leveraging sampled real-world data for training DRL agents. We evaluate the proposed approach in a gear assembly experiment with a precision tolerance of 0.3mm. The results show that our method can robustly and efficiently complete searching and insertion from arbitrary positions within an average of 15 seconds.
Learning 6D Pose Estimation from Synthetic RGBD Images for Robotic Applications
Aug 30, 2022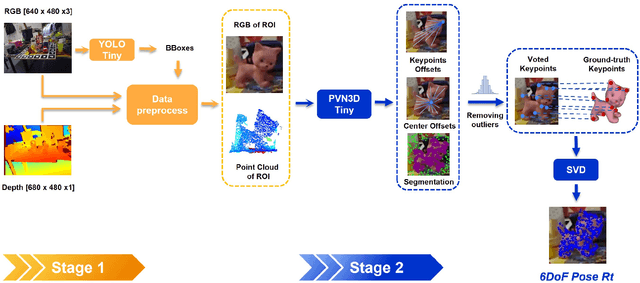
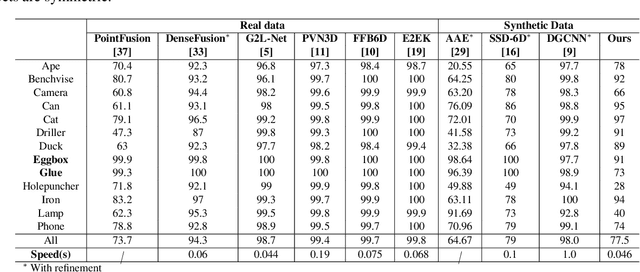

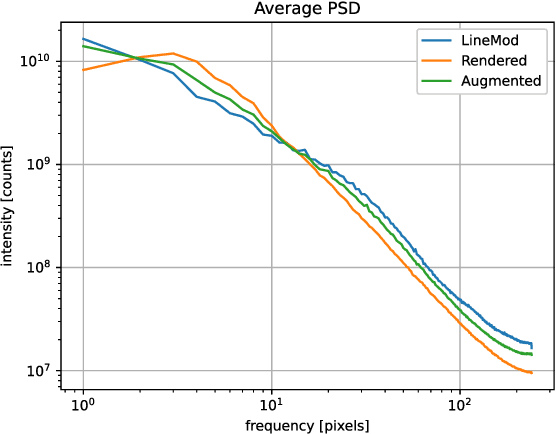
In this work, we propose a data generation pipeline by leveraging the 3D suite Blender to produce synthetic RGBD image datasets with 6D poses for robotic picking. The proposed pipeline can efficiently generate large amounts of photo-realistic RGBD images for the object of interest. In addition, a collection of domain randomization techniques is introduced to bridge the gap between real and synthetic data. Furthermore, we develop a real-time two-stage 6D pose estimation approach by integrating the object detector YOLO-V4-tiny and the 6D pose estimation algorithm PVN3D for time sensitive robotics applications. With the proposed data generation pipeline, our pose estimation approach can be trained from scratch using only synthetic data without any pre-trained models. The resulting network shows competitive performance compared to state-of-the-art methods when evaluated on LineMod dataset. We also demonstrate the proposed approach in a robotic experiment, grasping a household object from cluttered background under different lighting conditions.
Cloud-Edge Training Architecture for Sim-to-Real Deep Reinforcement Learning
Mar 04, 2022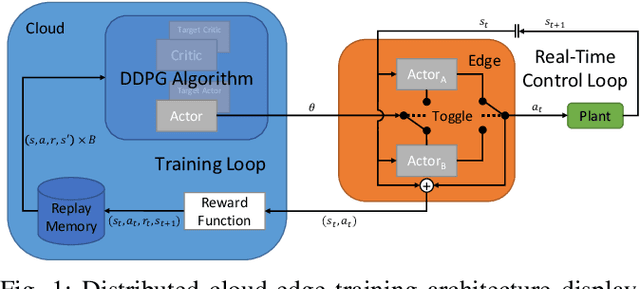
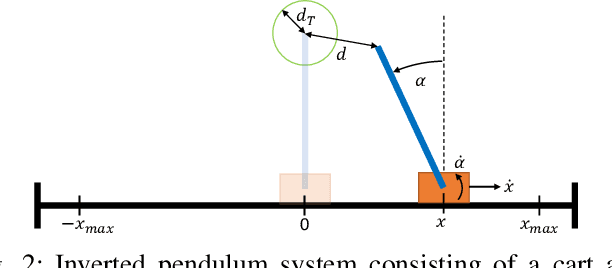
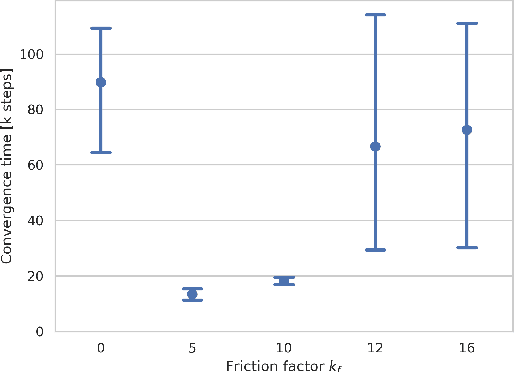
Deep reinforcement learning (DRL) is a promising approach to solve complex control tasks by learning policies through interactions with the environment. However, the training of DRL policies requires large amounts of training experiences, making it impractical to learn the policy directly on physical systems. Sim-to-real approaches leverage simulations to pretrain DRL policies and then deploy them in the real world. Unfortunately, the direct real-world deployment of pretrained policies usually suffers from performance deterioration due to the different dynamics, known as the reality gap. Recent sim-to-real methods, such as domain randomization and domain adaptation, focus on improving the robustness of the pretrained agents. Nevertheless, the simulation-trained policies often need to be tuned with real-world data to reach optimal performance, which is challenging due to the high cost of real-world samples. This work proposes a distributed cloud-edge architecture to train DRL agents in the real world in real-time. In the architecture, the inference and training are assigned to the edge and cloud, separating the real-time control loop from the computationally expensive training loop. To overcome the reality gap, our architecture exploits sim-to-real transfer strategies to continue the training of simulation-pretrained agents on a physical system. We demonstrate its applicability on a physical inverted-pendulum control system, analyzing critical parameters. The real-world experiments show that our architecture can adapt the pretrained DRL agents to unseen dynamics consistently and efficiently.