 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying F1TENTH Autonomous Racing: Survey, Methods and Benchmarks
Feb 28, 2024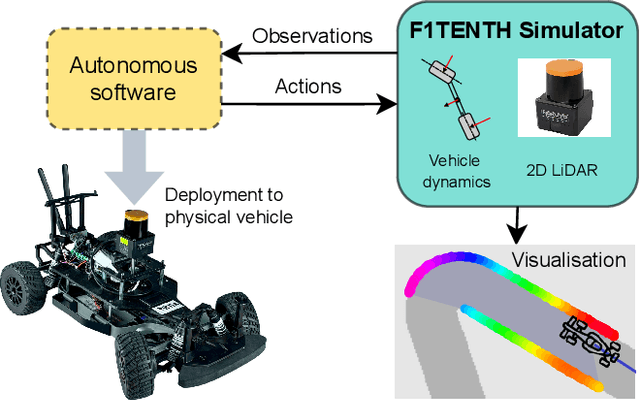
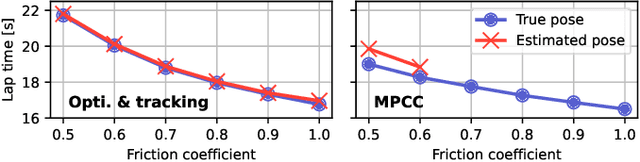
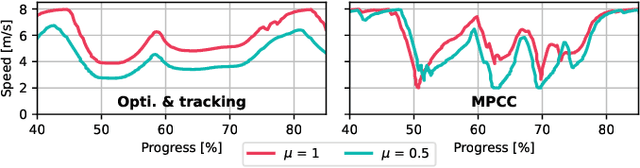
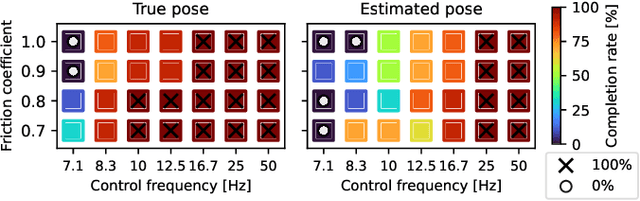
The F1TENTH autonomous racing platform, consisting of 1:10 scale RC cars, has evolved into a leading research platform. The many publications and real-world competitions span many domains, from classical path planning to novel learning-based algorithms. Consequently, the field is wide and disjointed, hindering direct comparison of methods and making it difficult to assess the state-of-the-art. Therefore, we aim to unify the field by surveying current approaches, describing common methods and providing benchmark results to facilitate clear comparison and establish a baseline for future work. We survey current work in F1TENTH racing in the classical and learning categories, explaining the different solution approaches. We describe particle filter localisation, trajectory optimisation and tracking, model predictive contouring control (MPCC), follow-the-gap and end-to-end reinforcement learning. We provide an open-source evaluation of benchmark methods and investigate overlooked factors of control frequency and localisation accuracy for classical methods and reward signal and training map for learning methods. The evaluation shows that the optimisation and tracking method achieves the fastest lap times, followed by the MPCC planner. Finally, our work identifies and outlines the relevant research aspects to help motivate future work in the F1TENTH domain.
High-performance Racing on Unmapped Tracks using Local Maps
Jan 31, 2024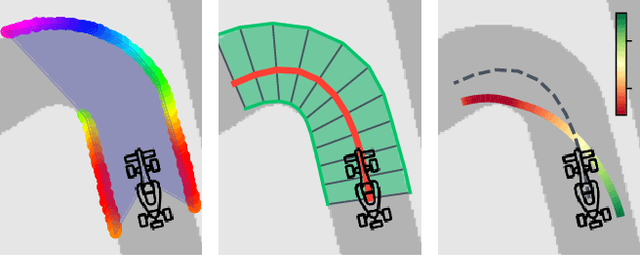



Map-based methods for autonomous racing estimate the vehicle's location, which is used to follow a high-level plan. While map-based optimisation methods demonstrate high-performance results, they are limited by requiring a map of the environment. In contrast, mapless methods can operate in unmapped contexts since they directly process raw sensor data (often LiDAR) to calculate commands. However, a major limitation in mapless methods is poor performance due to a lack of optimisation. In response, we propose the local map framework that uses easily extractable, low-level features to build local maps of the visible region that form the input to optimisation-based controllers. Our local map generation extracts the visible racetrack boundaries and calculates a centreline and track widths used for planning. We evaluate our method for simulated F1Tenth autonomous racing using a two-stage trajectory optimisation and tracking strategy and a model predictive controller. Our method achieves lap times that are 8.8% faster than the Follow-The-Gap method and 3.22% faster than end-to-end neural networks due to the optimisation resulting in a faster speed profile. The local map planner is 3.28% slower than global methods that have access to an entire map of the track that can be used for planning. Critically, our approach enables high-speed autonomous racing on unmapped tracks, achieving performance similar to global methods without requiring a track map.
Partial End-to-end Reinforcement Learning for Robustness Against Modelling Error in Autonomous Racing
Dec 11, 2023



In this paper, we address the issue of increasing the performance of reinforcement learning (RL) solutions for autonomous racing cars when navigating under conditions where practical vehicle modelling errors (commonly known as \emph{model mismatches}) are present. To address this challenge, we propose a partial end-to-end algorithm that decouples the planning and control tasks. Within this framework, an RL agent generates a trajectory comprising a path and velocity, which is subsequently tracked using a pure pursuit steering controller and a proportional velocity controller, respectively. In contrast, many current learning-based (i.e., reinforcement and imitation learning) algorithms utilise an end-to-end approach whereby a deep neural network directly maps from sensor data to control commands. By leveraging the robustness of a classical controller, our partial end-to-end driving algorithm exhibits better robustness towards model mismatches than standard end-to-end algorithms.
High-speed Autonomous Racing using Trajectory-aided Deep Reinforcement Learning
Jun 12, 2023

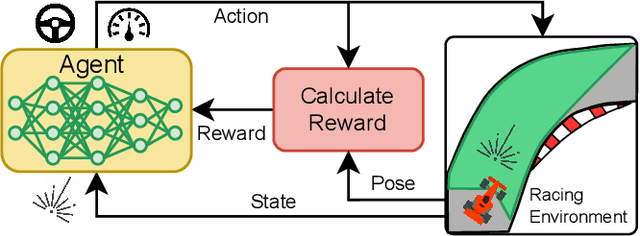

The classical method of autonomous racing uses real-time localisation to follow a precalculated optimal trajectory. In contrast, end-to-end deep reinforcement learning (DRL) can train agents to race using only raw LiDAR scans. While classical methods prioritise optimization for high-performance racing, DRL approaches have focused on low-performance contexts with little consideration of the speed profile. This work addresses the problem of using end-to-end DRL agents for high-speed autonomous racing. We present trajectory-aided learning (TAL) that trains DRL agents for high-performance racing by incorporating the optimal trajectory (racing line) into the learning formulation. Our method is evaluated using the TD3 algorithm on four maps in the open-source F1Tenth simulator. The results demonstrate that our method achieves a significantly higher lap completion rate at high speeds compared to the baseline. This is due to TAL training the agent to select a feasible speed profile of slowing down in the corners and roughly tracking the optimal trajectory.