 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-1-to-3: Enriching Diffusion Priors for Novel View Synthesis of Real Vehicles
Dec 19, 2024The recent advent of large-scale 3D data, e.g. Objaverse, has led to impressive progress in training pose-conditioned diffusion models for novel view synthesis. However, due to the synthetic nature of such 3D data, their performance drops significantly when applied to real-world images. This paper consolidates a set of good practices to finetune large pretrained models for a real-world task -- harvesting vehicle assets for autonomous driving applications. To this end, we delve into the discrepancies between the synthetic data and real driving data, then develop several strategies to account for them properly. Specifically, we start with a virtual camera rotation of real images to ensure geometric alignment with synthetic data and consistency with the pose manifold defined by pretrained models. We also identify important design choices in object-centric data curation to account for varying object distances in real driving scenes -- learn across varying object scales with fixed camera focal length. Further, we perform occlusion-aware training in latent spaces to account for ubiquitous occlusions in real data, and handle large viewpoint changes by leveraging a symmetric prior. Our insights lead to effective finetuning that results in a $68.8\%$ reduction in FID for novel view synthesis over prior arts.
Generative Region-Language Pretraining for Open-Ended Object Detection
Mar 15, 2024In recent research, significant attention has been devoted to the open-vocabulary object detection task, aiming to generalize beyond the limited number of classes labeled during training and detect objects described by arbitrary category names at inference. Compared with conventional object detection, open vocabulary object detection largely extends the object detection categories. However, it relies on calculating the similarity between image regions and a set of arbitrary category names with a pretrained vision-and-language model. This implies that, despite its open-set nature, the task still needs the predefined object categories during the inference stage. This raises the question: What if we do not have exact knowledge of object categories during inference? In this paper, we call such a new setting as generative open-ended object detection, which is a more general and practical problem. To address it, we formulate object detection as a generative problem and propose a simple framework named GenerateU, which can detect dense objects and generate their names in a free-form way. Particularly, we employ Deformable DETR as a region proposal generator with a language model translating visual regions to object names. To assess the free-form object detection task, we introduce an evaluation method designed to quantitatively measure the performance of generative outcomes. Extensive experiments demonstrate strong zero-shot detection performance of our GenerateU. For example, on the LVIS dataset, our GenerateU achieves comparable results to the open-vocabulary object detection method GLIP, even though the category names are not seen by GenerateU during inference. Code is available at: https:// github.com/FoundationVision/GenerateU .
Learning Object-Language Alignments for Open-Vocabulary Object Detection
Nov 27, 2022Existing object detection methods are bounded in a fixed-set vocabulary by costly labeled data. When dealing with novel categories, the model has to be retrained with more bounding box annotations. Natural language supervision is an attractive alternative for its annotation-free attributes and broader object concepts. However, learning open-vocabulary object detection from language is challenging since image-text pairs do not contain fine-grained object-language alignments. Previous solutions rely on either expensive grounding annotations or distilling classification-oriented vision models. In this paper, we propose a novel open-vocabulary object detection framework directly learning from image-text pair data. We formulate object-language alignment as a set matching problem between a set of image region features and a set of word embeddings. It enables us to train an open-vocabulary object detector on image-text pairs in a much simple and effective way. Extensive experiments on two benchmark datasets, COCO and LVIS, demonstrate our superior performance over the competing approaches on novel categories, e.g. achieving 32.0% mAP on COCO and 21.7% mask mAP on LVIS. Code is available at: https://github.com/clin1223/VLDet.
Multimodal Transformer with Variable-length Memory for Vision-and-Language Navigation
Nov 10, 2021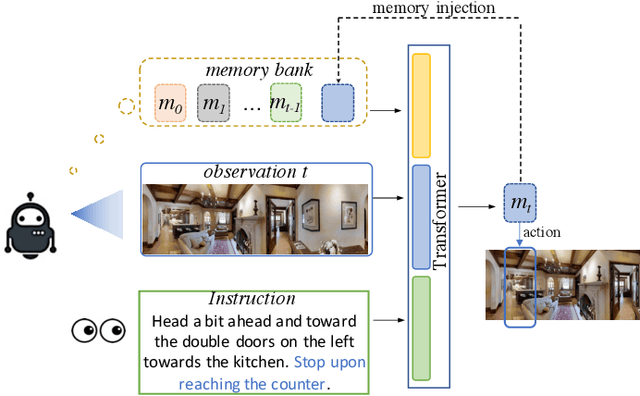
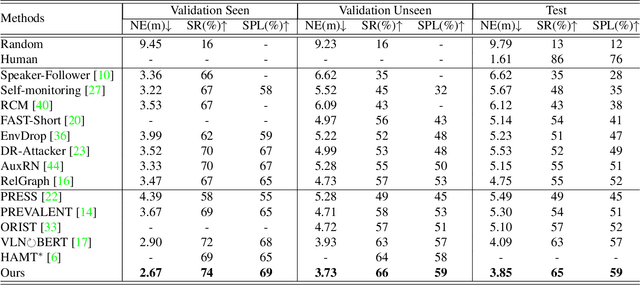
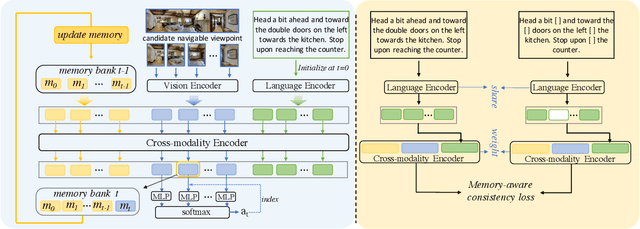
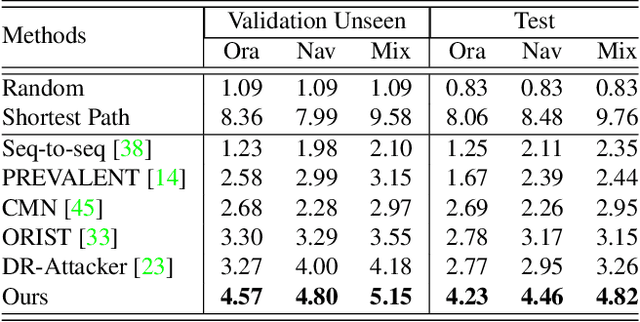
Vision-and-Language Navigation (VLN) is a task that an agent is required to follow a language instruction to navigate to the goal position, which relies on the ongoing interactions with the environment during moving. Recent Transformer-based VLN methods have made great progress benefiting from the direct connections between visual observations and the language instruction via the multimodal cross-attention mechanism. However, these methods usually represent temporal context as a fixed-length vector by using an LSTM decoder or using manually designed hidden states to build a recurrent Transformer. Considering a single fixed-length vector is often insufficient to capture long-term temporal context, in this paper, we introduce Multimodal Transformer with Variable-length Memory (MTVM) for visually-grounded natural language navigation by modelling the temporal context explicitly. Specifically, MTVM enables the agent to keep track of the navigation trajectory by directly storing previous activations in a memory bank. To further boost the performance, we propose a memory-aware consistency loss to help learn a better joint representation of temporal context with random masked instructions. We evaluate MTVM on popular R2R and CVDN datasets, and our model improves Success Rate on R2R unseen validation and test set by 2% each, and reduce Goal Process by 1.6m on CVDN test set.
Emotional Semantics-Preserved and Feature-Aligned CycleGAN for Visual Emotion Adaptation
Nov 25, 2020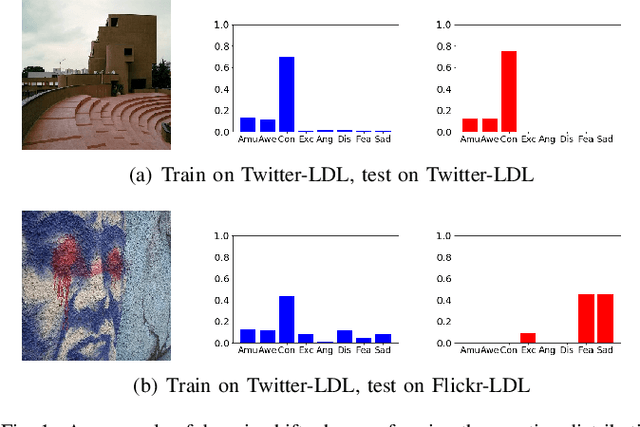

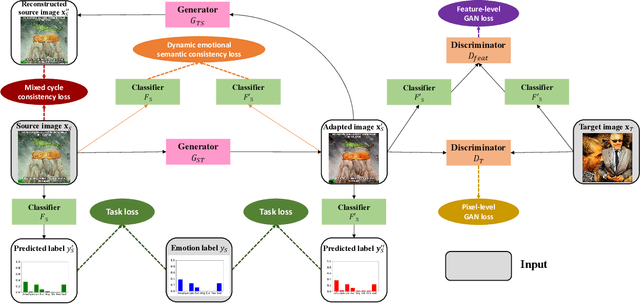
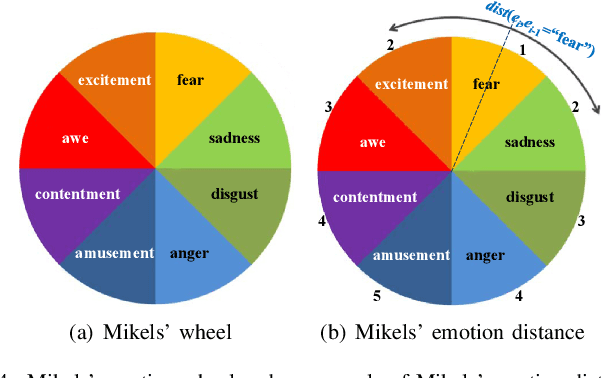
Thanks to large-scale labeled training data, deep neural networks (DNNs) have obtained remarkable success in many vision and multimedia tasks. However, because of the presence of domain shift, the learned knowledge of the well-trained DNNs cannot be well generalized to new domains or datasets that have few labels. Unsupervised domain adaptation (UDA) studies the problem of transferring models trained on one labeled source domain to another unlabeled target domain. In this paper, we focus on UDA in visual emotion analysis for both emotion distribution learning and dominant emotion classification. Specifically, we design a novel end-to-end cycle-consistent adversarial model, termed CycleEmotionGAN++. First, we generate an adapted domain to align the source and target domains on the pixel-level by improving CycleGAN with a multi-scale structured cycle-consistency loss. During the image translation, we propose a dynamic emotional semantic consistency loss to preserve the emotion labels of the source images. Second, we train a transferable task classifier on the adapted domain with feature-level alignment between the adapted and target domains. We conduct extensive UDA experiments on the Flickr-LDL & Twitter-LDL datasets for distribution learning and ArtPhoto & FI datasets for emotion classification. The results demonstrate the significant improvements yielded by the proposed CycleEmotionGAN++ as compared to state-of-the-art UDA approaches.
Multi-source Domain Adaptation for Visual Sentiment Classification
Jan 12, 2020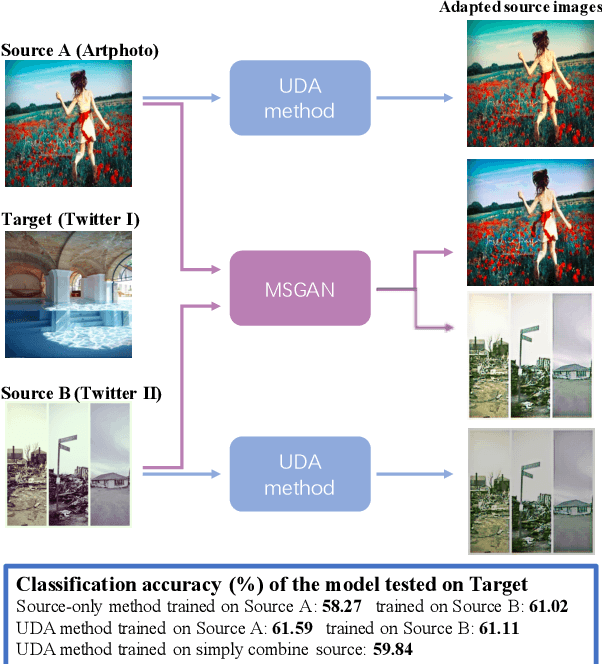
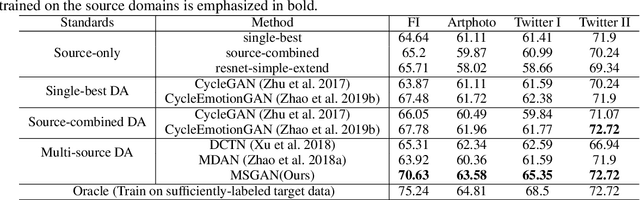
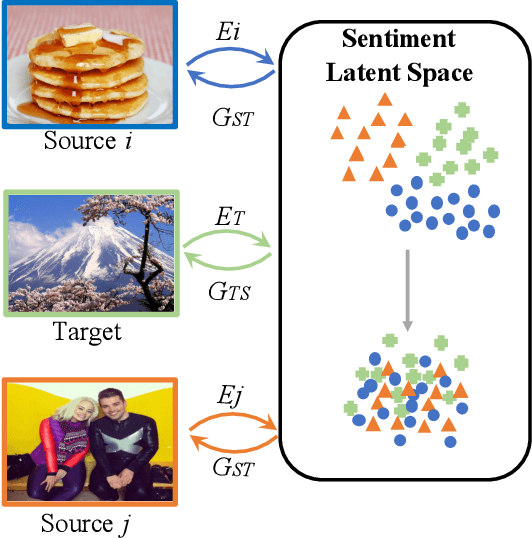
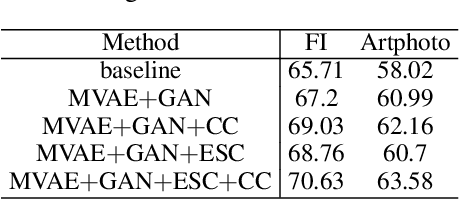
Existing domain adaptation methods on visual sentiment classification typically are investigated under the single-source scenario, where the knowledge learned from a source domain of sufficient labeled data is transferred to the target domain of loosely labeled or unlabeled data. However, in practice, data from a single source domain usually have a limited volume and can hardly cover the characteristics of the target domain. In this paper, we propose a novel multi-source domain adaptation (MDA) method, termed Multi-source Sentiment Generative Adversarial Network (MSGAN), for visual sentiment classification. To handle data from multiple source domains, it learns to find a unified sentiment latent space where data from both the source and target domains share a similar distribution. This is achieved via cycle consistent adversarial learning in an end-to-end manner. Extensive experiments conducted on four benchmark datasets demonstrate that MSGAN significantly outperforms the state-of-the-art MDA approaches for visual sentiment classification.
Robust Multi-subspace Analysis Using Novel Column L0-norm Constrained Matrix Factorization
Jan 27, 2018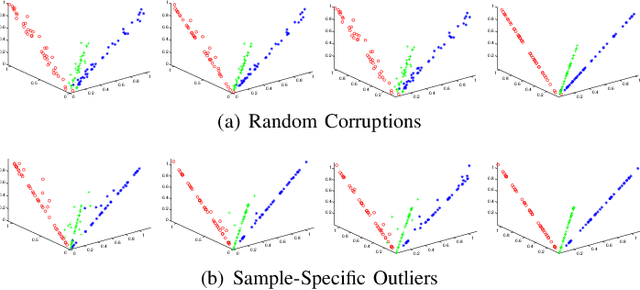
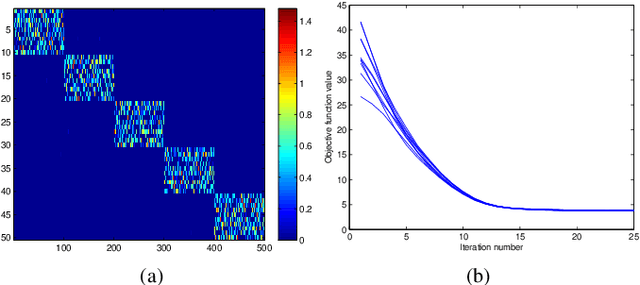
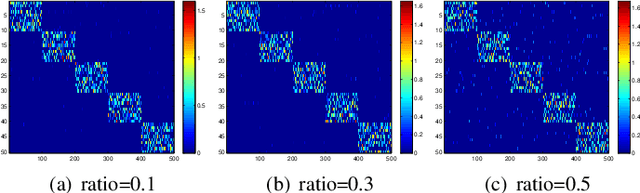
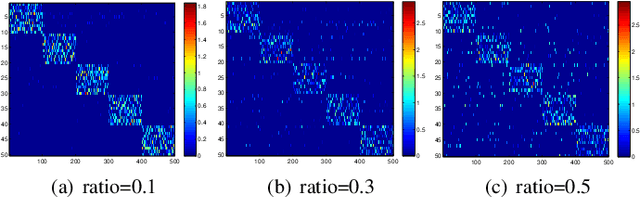
We study the underlying structure of data (approximately) generated from a union of independent subspaces. Traditional methods learn only one subspace, failing to discover the multi-subspace structure, while state-of-the-art methods analyze the multi-subspace structure using data themselves as the dictionary, which cannot offer the explicit basis to span each subspace and are sensitive to errors via an indirect representation. Additionally, they also suffer from a high computational complexity, being quadratic or cubic to the sample size. To tackle all these problems, we propose a method, called Matrix Factorization with Column L0-norm constraint (MFC0), that can simultaneously learn the basis for each subspace, generate a direct sparse representation for each data sample, as well as removing errors in the data in an efficient way. Furthermore, we develop a first-order alternating direction algorithm, whose computational complexity is linear to the sample size, to stably and effectively solve the nonconvex objective function and non- smooth l0-norm constraint of MFC0. Experimental results on both synthetic and real-world datasets demonstrate that besides the superiority over traditional and state-of-the-art methods for subspace clustering, data reconstruction, error correction, MFC0 also shows its uniqueness for multi-subspace basis learning and direct sparse representation.