 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Conductor 2.0: An agent builds a TurboQuant inference accelerator in 80 hours
May 06, 2026Driven by a rapid co-evolution of both harness and underlying models, LLM agents are improving at a dizzying pace. In our prior work (performed in Dec. 2025), we introduced "Design Conductor" (or just "Conductor"), a system capable of building a 5-stage Linux-capable RISC-V CPU in 12 hours. In this work, we introduce an updated multi-agent harness powered by frontier models released in April 2026, which is able to handle 80x larger tasks, at higher quality, fully autonomously. Following a brief introduction, we examine 4 designs that the system produced autonomously, including "VerTQ", an LLM inference accelerator which hard-wires support for TurboQuant in a 240-cycle pipeline, starting from the TurboQuant arXiv paper. VerTQ includes heavy compute processing, with 5129 FP16/32 units; the design was mapped to an FPGA at 125 MHz and consumes 5.7 mm^2 in TSMC 16FF (8 attention pipes). We review the key new characteristics that enabled these results. Finally, we analyze Design Conductor's token usage and other empirical characteristics, including its limitations.
Differentiable NAS Framework and Application to Ads CTR Prediction
Oct 25, 2021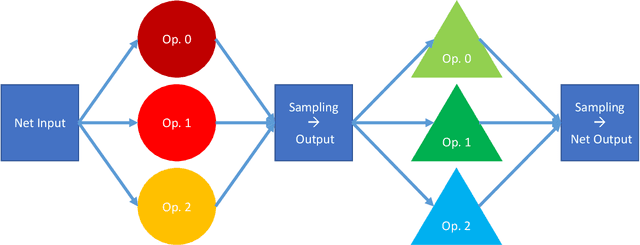
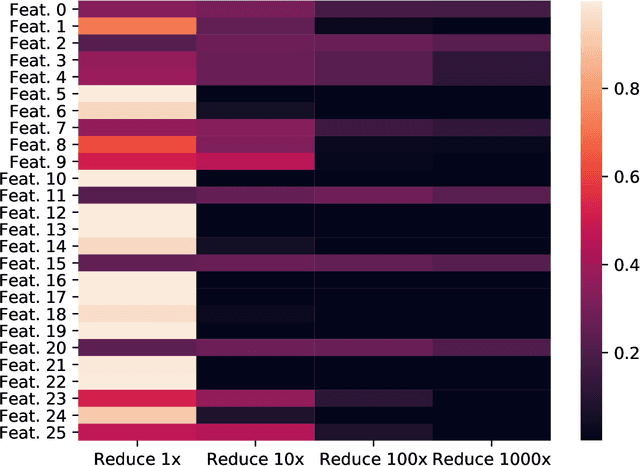
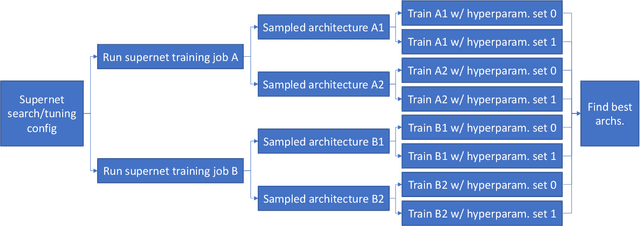
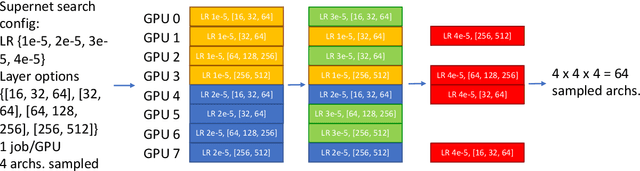
Neural architecture search (NAS) methods aim to automatically find the optimal deep neural network (DNN) architecture as measured by a given objective function, typically some combination of task accuracy and inference efficiency. For many areas, such as computer vision and natural language processing, this is a critical, yet still time consuming process. New NAS methods have recently made progress in improving the efficiency of this process. We implement an extensible and modular framework for Differentiable Neural Architecture Search (DNAS) to help solve this problem. We include an overview of the major components of our codebase and how they interact, as well as a section on implementing extensions to it (including a sample), in order to help users adopt our framework for their applications across different categories of deep learning models. To assess the capabilities of our methodology and implementation, we apply DNAS to the problem of ads click-through rate (CTR) prediction, arguably the highest-value and most worked on AI problem at hyperscalers today. We develop and tailor novel search spaces to a Deep Learning Recommendation Model (DLRM) backbone for CTR prediction, and report state-of-the-art results on the Criteo Kaggle CTR prediction dataset.
Emotional Semantics-Preserved and Feature-Aligned CycleGAN for Visual Emotion Adaptation
Nov 25, 2020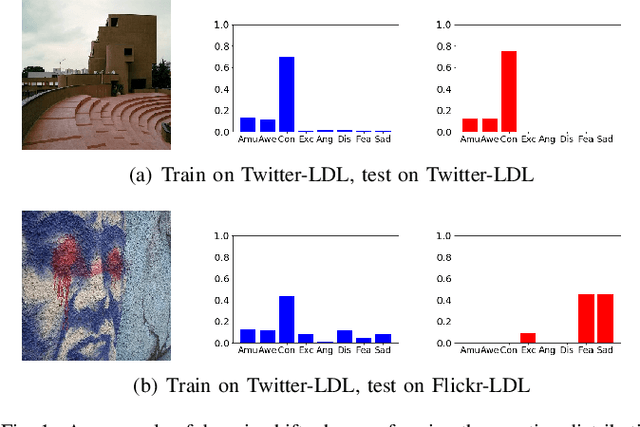

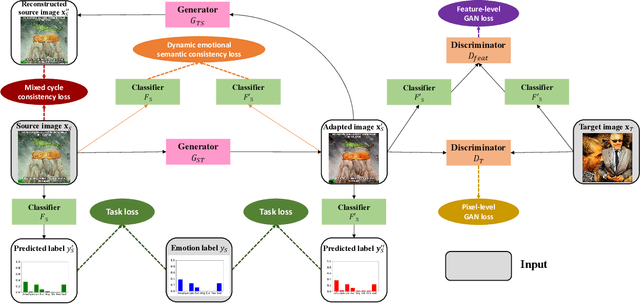
Thanks to large-scale labeled training data, deep neural networks (DNNs) have obtained remarkable success in many vision and multimedia tasks. However, because of the presence of domain shift, the learned knowledge of the well-trained DNNs cannot be well generalized to new domains or datasets that have few labels. Unsupervised domain adaptation (UDA) studies the problem of transferring models trained on one labeled source domain to another unlabeled target domain. In this paper, we focus on UDA in visual emotion analysis for both emotion distribution learning and dominant emotion classification. Specifically, we design a novel end-to-end cycle-consistent adversarial model, termed CycleEmotionGAN++. First, we generate an adapted domain to align the source and target domains on the pixel-level by improving CycleGAN with a multi-scale structured cycle-consistency loss. During the image translation, we propose a dynamic emotional semantic consistency loss to preserve the emotion labels of the source images. Second, we train a transferable task classifier on the adapted domain with feature-level alignment between the adapted and target domains. We conduct extensive UDA experiments on the Flickr-LDL & Twitter-LDL datasets for distribution learning and ArtPhoto & FI datasets for emotion classification. The results demonstrate the significant improvements yielded by the proposed CycleEmotionGAN++ as compared to state-of-the-art UDA approaches.
Curriculum CycleGAN for Textual Sentiment Domain Adaptation with Multiple Sources
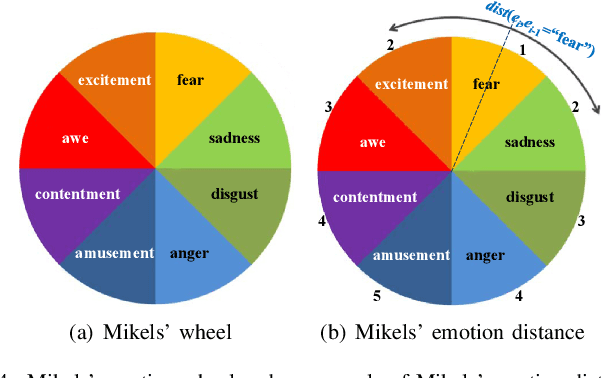
Nov 17, 2020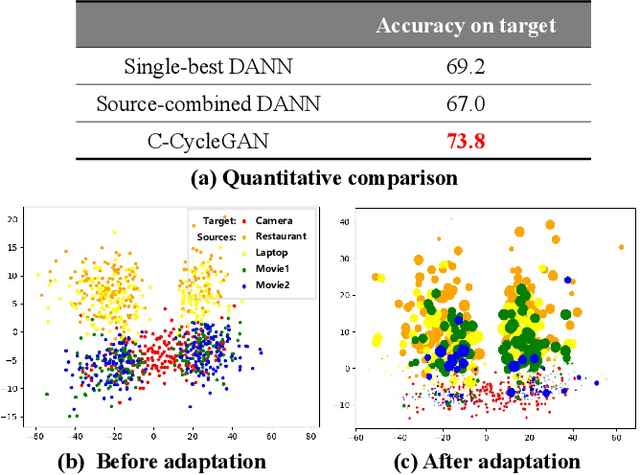


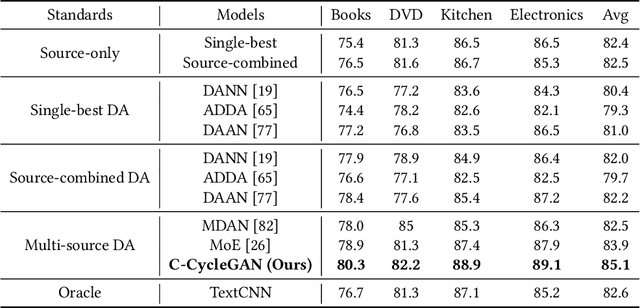
Sentiment analysis of user-generated reviews or comments on products and services on social media can help enterprises to analyze the feedback from customers and take corresponding actions for improvement. To mitigate large-scale annotations, domain adaptation (DA) provides an alternate solution by learning a transferable model from another labeled source domain. Since the labeled data may be from multiple sources, multi-source domain adaptation (MDA) would be more practical to exploit the complementary information from different domains. Existing MDA methods might fail to extract some discriminative features in the target domain that are related to sentiment, neglect the correlations of different sources as well as the distribution difference among different sub-domains even in the same source, and cannot reflect the varying optimal weighting during different training stages. In this paper, we propose an instance-level multi-source domain adaptation framework, named curriculum cycle-consistent generative adversarial network (C-CycleGAN). Specifically, C-CycleGAN consists of three components: (1) pre-trained text encoder which encodes textual input from different domains into a continuous representation space, (2) intermediate domain generator with curriculum instance-level adaptation which bridges the gap across source and target domains, and (3) task classifier trained on the intermediate domain for final sentiment classification. C-CycleGAN transfers source samples at an instance-level to an intermediate domain that is closer to target domain with sentiment semantics preserved and without losing discriminative features. Further, our dynamic instance-level weighting mechanisms can assign the optimal weights to different source samples in each training stage. We conduct extensive experiments on three benchmark datasets and achieve substantial gains over state-of-the-art approaches.
A Review of Single-Source Deep Unsupervised Visual Domain Adaptation
Sep 19, 2020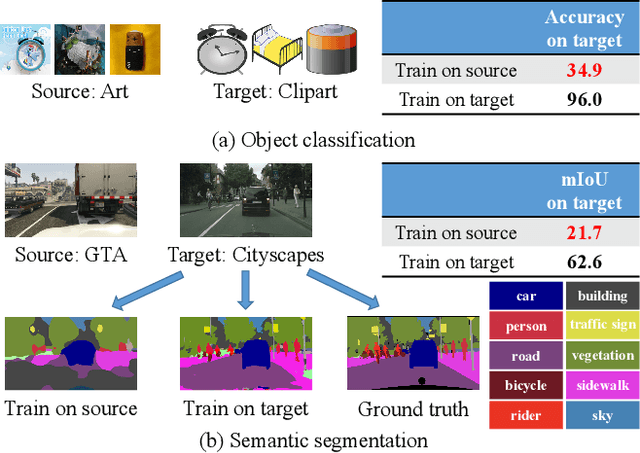
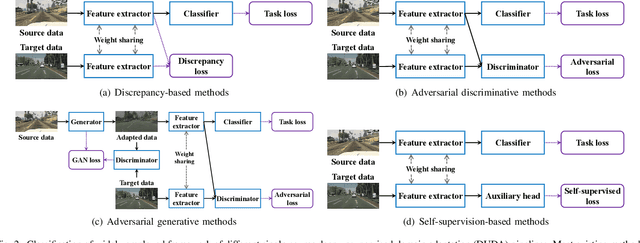

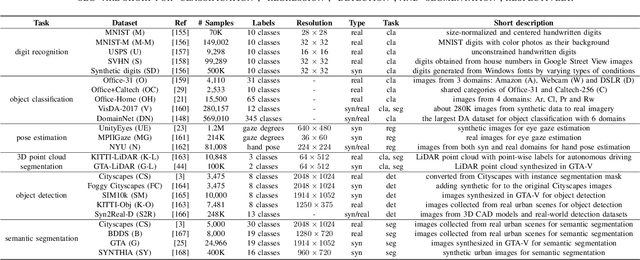
Large-scale labeled training datasets have enabled deep neural networks to excel across a wide range of benchmark vision tasks. However, in many applications, it is prohibitively expensive and time-consuming to obtain large quantities of labeled data. To cope with limited labeled training data, many have attempted to directly apply models trained on a large-scale labeled source domain to another sparsely labeled or unlabeled target domain. Unfortunately, direct transfer across domains often performs poorly due to the presence of domain shift or dataset bias. Domain adaptation is a machine learning paradigm that aims to learn a model from a source domain that can perform well on a different (but related) target domain. In this paper, we review the latest single-source deep unsupervised domain adaptation methods focused on visual tasks and discuss new perspectives for future research. We begin with the definitions of different domain adaptation strategies and the descriptions of existing benchmark datasets. We then summarize and compare different categories of single-source unsupervised domain adaptation methods, including discrepancy-based methods, adversarial discriminative methods, adversarial generative methods, and self-supervision-based methods. Finally, we discuss future research directions with challenges and possible solutions.
SqueezeBERT: What can computer vision teach NLP about efficient neural networks?
Jun 19, 2020
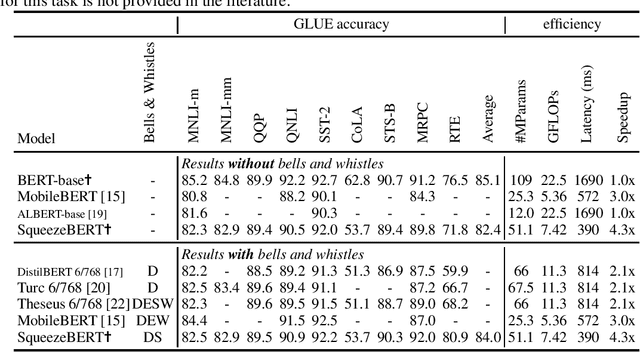


Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets, large computing systems, and better neural network models, natural language processing (NLP) technology has made significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test set. The SqueezeBERT code will be released.