 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Transformer with Variable-length Memory for Vision-and-Language Navigation
Paper and Code
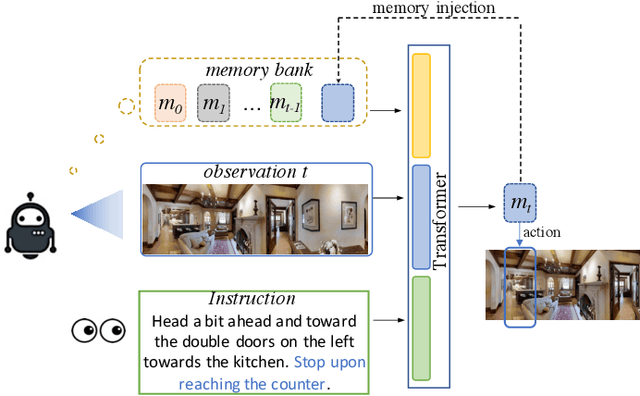
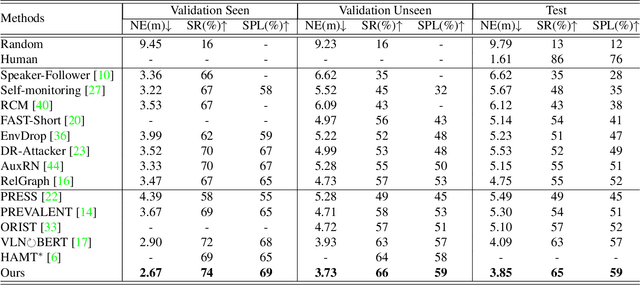
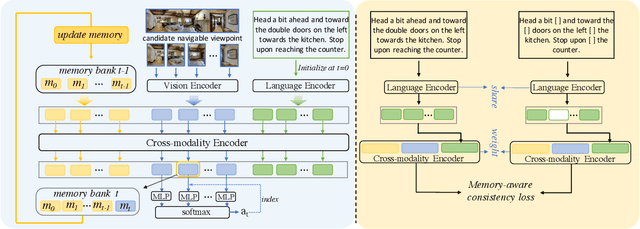
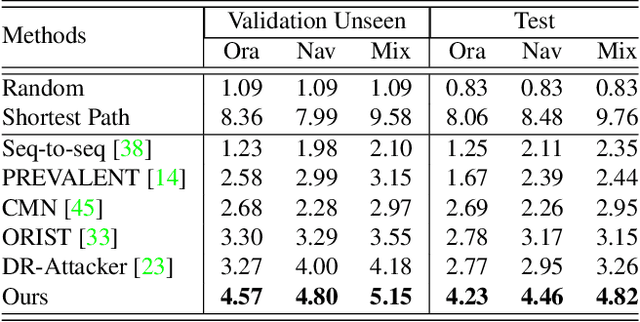
Vision-and-Language Navigation (VLN) is a task that an agent is required to follow a language instruction to navigate to the goal position, which relies on the ongoing interactions with the environment during moving. Recent Transformer-based VLN methods have made great progress benefiting from the direct connections between visual observations and the language instruction via the multimodal cross-attention mechanism. However, these methods usually represent temporal context as a fixed-length vector by using an LSTM decoder or using manually designed hidden states to build a recurrent Transformer. Considering a single fixed-length vector is often insufficient to capture long-term temporal context, in this paper, we introduce Multimodal Transformer with Variable-length Memory (MTVM) for visually-grounded natural language navigation by modelling the temporal context explicitly. Specifically, MTVM enables the agent to keep track of the navigation trajectory by directly storing previous activations in a memory bank. To further boost the performance, we propose a memory-aware consistency loss to help learn a better joint representation of temporal context with random masked instructions. We evaluate MTVM on popular R2R and CVDN datasets, and our model improves Success Rate on R2R unseen validation and test set by 2% each, and reduce Goal Process by 1.6m on CVDN test set.