 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan an unsupervised clustering algorithm reproduce a categorization system?
Paper and Code

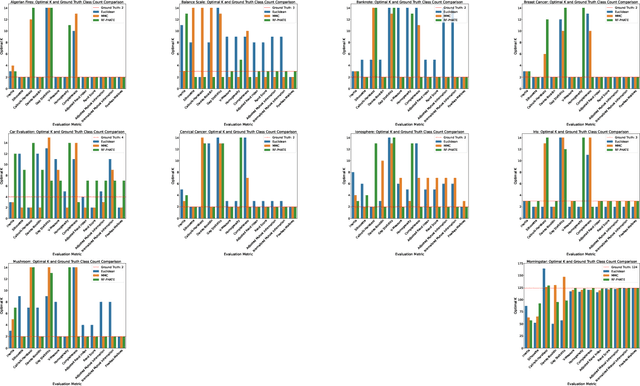


Peer analysis is a critical component of investment management, often relying on expert-provided categorization systems. These systems' consistency is questioned when they do not align with cohorts from unsupervised clustering algorithms optimized for various metrics. We investigate whether unsupervised clustering can reproduce ground truth classes in a labeled dataset, showing that success depends on feature selection and the chosen distance metric. Using toy datasets and fund categorization as real-world examples we demonstrate that accurately reproducing ground truth classes is challenging. We also highlight the limitations of standard clustering evaluation metrics in identifying the optimal number of clusters relative to the ground truth classes. We then show that if appropriate features are available in the dataset, and a proper distance metric is known (e.g., using a supervised Random Forest-based distance metric learning method), then an unsupervised clustering can indeed reproduce the ground truth classes as distinct clusters.