 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Choose a Threshold for an Evaluation Metric for Large Language Models
Dec 10, 2024



To ensure and monitor large language models (LLMs) reliably, various evaluation metrics have been proposed in the literature. However, there is little research on prescribing a methodology to identify a robust threshold on these metrics even though there are many serious implications of an incorrect choice of the thresholds during deployment of the LLMs. Translating the traditional model risk management (MRM) guidelines within regulated industries such as the financial industry, we propose a step-by-step recipe for picking a threshold for a given LLM evaluation metric. We emphasize that such a methodology should start with identifying the risks of the LLM application under consideration and risk tolerance of the stakeholders. We then propose concrete and statistically rigorous procedures to determine a threshold for the given LLM evaluation metric using available ground-truth data. As a concrete example to demonstrate the proposed methodology at work, we employ it on the Faithfulness metric, as implemented in various publicly available libraries, using the publicly available HaluBench dataset. We also lay a foundation for creating systematic approaches to select thresholds, not only for LLMs but for any GenAI applications.
Can an unsupervised clustering algorithm reproduce a categorization system?
Aug 19, 2024
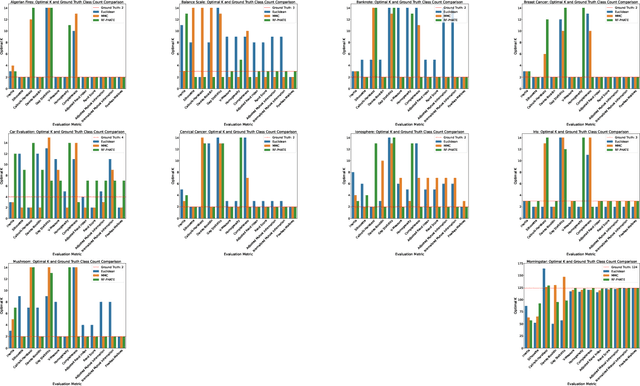


Peer analysis is a critical component of investment management, often relying on expert-provided categorization systems. These systems' consistency is questioned when they do not align with cohorts from unsupervised clustering algorithms optimized for various metrics. We investigate whether unsupervised clustering can reproduce ground truth classes in a labeled dataset, showing that success depends on feature selection and the chosen distance metric. Using toy datasets and fund categorization as real-world examples we demonstrate that accurately reproducing ground truth classes is challenging. We also highlight the limitations of standard clustering evaluation metrics in identifying the optimal number of clusters relative to the ground truth classes. We then show that if appropriate features are available in the dataset, and a proper distance metric is known (e.g., using a supervised Random Forest-based distance metric learning method), then an unsupervised clustering can indeed reproduce the ground truth classes as distinct clusters.