 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards reducing hallucination in extracting information from financial reports using Large Language Models
Paper and Code
Oct 16, 2023
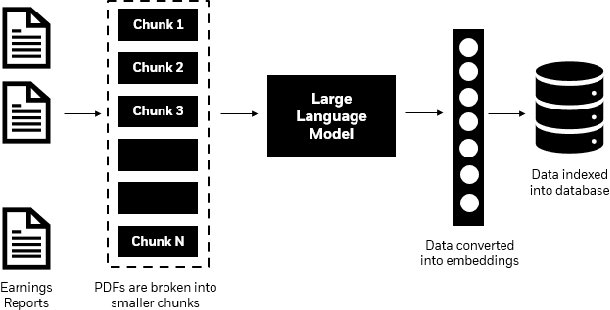

For a financial analyst, the question and answer (Q\&A) segment of the company financial report is a crucial piece of information for various analysis and investment decisions. However, extracting valuable insights from the Q\&A section has posed considerable challenges as the conventional methods such as detailed reading and note-taking lack scalability and are susceptible to human errors, and Optical Character Recognition (OCR) and similar techniques encounter difficulties in accurately processing unstructured transcript text, often missing subtle linguistic nuances that drive investor decisions. Here, we demonstrate the utilization of Large Language Models (LLMs) to efficiently and rapidly extract information from earnings report transcripts while ensuring high accuracy transforming the extraction process as well as reducing hallucination by combining retrieval-augmented generation technique as well as metadata. We evaluate the outcomes of various LLMs with and without using our proposed approach based on various objective metrics for evaluating Q\&A systems, and empirically demonstrate superiority of our method.