 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFECoM: A Step towards Fine-Grained Energy Measurement for Deep Learning
Aug 23, 2023With the increasing usage, scale, and complexity of Deep Learning (DL) models, their rapidly growing energy consumption has become a critical concern. Promoting green development and energy awareness at different granularities is the need of the hour to limit carbon emissions of DL systems. However, the lack of standard and repeatable tools to accurately measure and optimize energy consumption at a fine granularity (e.g., at method level) hinders progress in this area. In this paper, we introduce FECoM (Fine-grained Energy Consumption Meter), a framework for fine-grained DL energy consumption measurement. Specifically, FECoM provides researchers and developers a mechanism to profile DL APIs. FECoM addresses the challenges of measuring energy consumption at fine-grained level by using static instrumentation and considering various factors, including computational load and temperature stability. We assess FECoM's capability to measure fine-grained energy consumption for one of the most popular open-source DL frameworks, namely TensorFlow. Using FECoM, we also investigate the impact of parameter size and execution time on energy consumption, enriching our understanding of TensorFlow APIs' energy profiles. Furthermore, we elaborate on the considerations, issues, and challenges that one needs to consider while designing and implementing a fine-grained energy consumption measurement tool. We hope this work will facilitate further advances in DL energy measurement and the development of energy-aware practices for DL systems.
A Survey on Machine Learning Techniques for Source Code Analysis
Oct 18, 2021
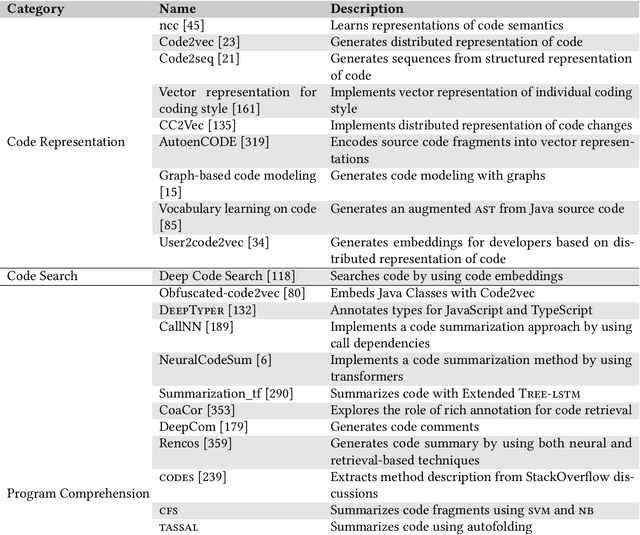

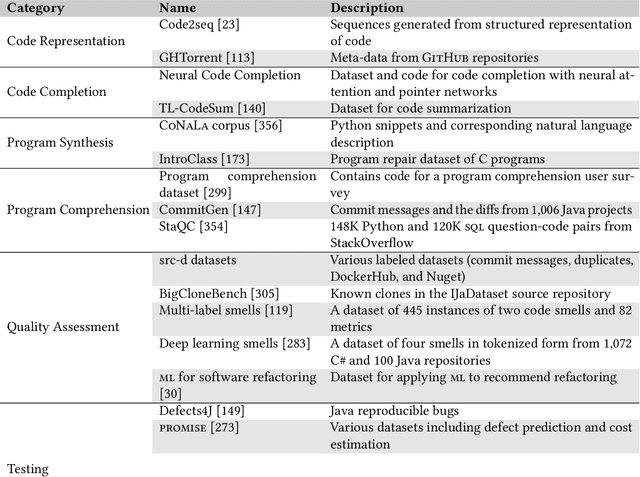
Context: The advancements in machine learning techniques have encouraged researchers to apply these techniques to a myriad of software engineering tasks that use source code analysis such as testing and vulnerabilities detection. A large number of studies poses challenges to the community to understand the current landscape. Objective: We aim to summarize the current knowledge in the area of applied machine learning for source code analysis. Method: We investigate studies belonging to twelve categories of software engineering tasks and corresponding machine learning techniques, tools, and datasets that have been applied to solve them. To do so, we carried out an extensive literature search and identified 364 primary studies published between 2002 and 2021. We summarize our observations and findings with the help of the identified studies. Results: Our findings suggest that the usage of machine learning techniques for source code analysis tasks is consistently increasing. We synthesize commonly used steps and the overall workflow for each task, and summarize the employed machine learning techniques. Additionally, we collate a comprehensive list of available datasets and tools useable in this context. Finally, we summarize the perceived challenges in this area that include availability of standard datasets, reproducibility and replicability, and hardware resources.